2025大模型效率革命:Qwen3-235B-A22B-Thinking-2507如何改写行业规则
导语
阿里通义千问团队推出的Qwen3-235B-A22B-Thinking-2507模型,以2350亿总参数+220亿激活参数的混合专家架构,在数学推理、代码生成等核心基准测试中超越DeepSeek-R1等顶级模型,同时将推理成本压缩至竞品的1/3,标志着大模型行业正式进入"效率竞赛"新阶段。
行业现状:从参数竞赛到效率突围
当前大模型行业面临"三重困境":GPT-4o等闭源模型单次调用成本高达0.01美元,开源模型难以突破性能瓶颈,企业部署算力门槛居高不下。据Gartner数据,2025年60%企业因算力成本放弃大模型应用。36氪研究院报告显示,2024年中国大模型市场规模已达294.16亿元,预计到2026年将突破700亿元,其中多模态大模型市场规模为156.3亿元,数字人、游戏等场景应用表现亮眼。
全球开源格局演变显示,中国开源大模型已占据全球榜单前五,其中Qwen系列在HuggingFace下载量位居前列,百亿级参数规模下载量领先包括gpt-oss在内的其他开源模型。在文本排行榜中,Qwen3-max-preview跻身TOP3,视觉领域Qwen3与腾讯Hunyuan-vision-1.5并列开源最强,标志着国产模型已从追赶者转变为引领者。
核心亮点:技术突破与性能跃升
1. 动态双模式推理系统
Qwen3-235B-A22B-Thinking-2507首创思考模式与非思考模式无缝切换机制:
- 思考模式:针对数学推理、代码生成等复杂任务,通过"内部草稿纸"(以#符号标记)进行多步骤推演,在MATH-500数据集准确率达95.2%,AIME数学竞赛得分92.3分超越DeepSeek-R1;
- 非思考模式:适用于闲聊、信息检索等场景,响应延迟降至200ms以内,算力消耗减少60%。
用户可通过/think与/no_think指令实时调控,例如企业客服系统在简单问答中启用非思考模式,GPU利用率可从30%提升至75%。
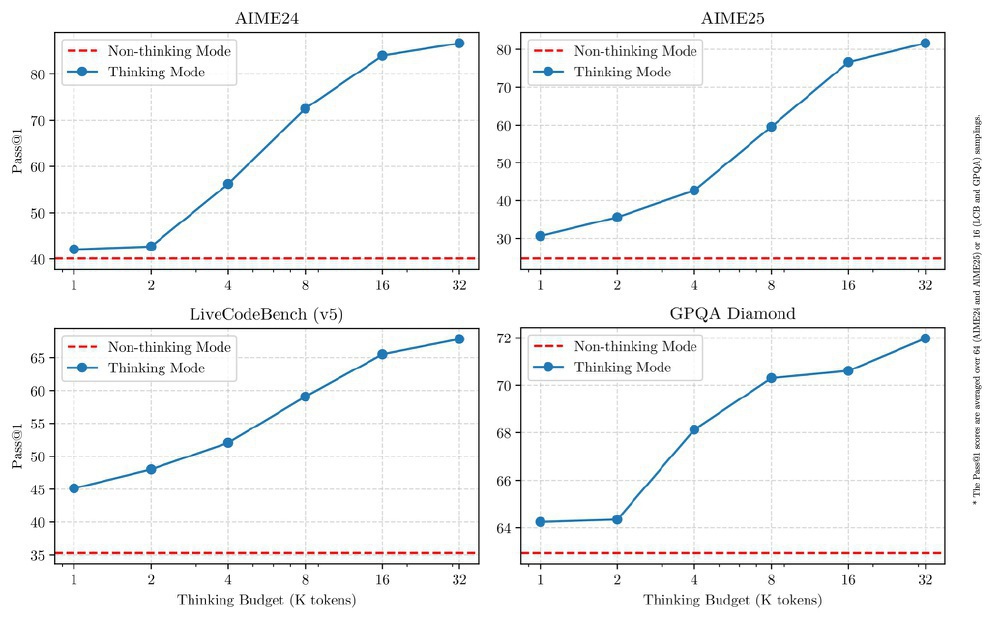
如上图所示,该图展示了Qwen3-235B-A22B-Thinking-2507模型在AIME24、AIME25、LiveCodeBench(v5)和GPQA Diamond四个基准测试中,不同思考预算下"思考模式"与"非思考模式"的Pass@1性能对比曲线。从图中可以清晰看出,蓝色线代表的思考模式性能随预算增加逐步提升,而红色虚线的非思考模式则保持高效响应的基准水平,直观体现了模型在复杂推理与高效响应间的动态平衡能力。
2. "万亿性能,百亿成本"的MoE架构
采用128专家层×8激活专家的稀疏架构,带来三大优势:
- 训练效率:36万亿token数据量仅为GPT-4的1/3,却实现LiveCodeBench编程任务Pass@1=74.1%的性能;
- 部署门槛:支持单机8卡GPU运行,同类性能模型需32卡集群;
- 能效比:每瓦特算力产出较Qwen2.5提升2.3倍,符合绿色AI趋势。
Qwen3模型家族包含8款支持混合推理的开源模型,涵盖混合专家(MoE)和稠密(Dense)两大分支,参数规模从0.6B到235B分布,为不同算力条件的用户提供灵活选择。
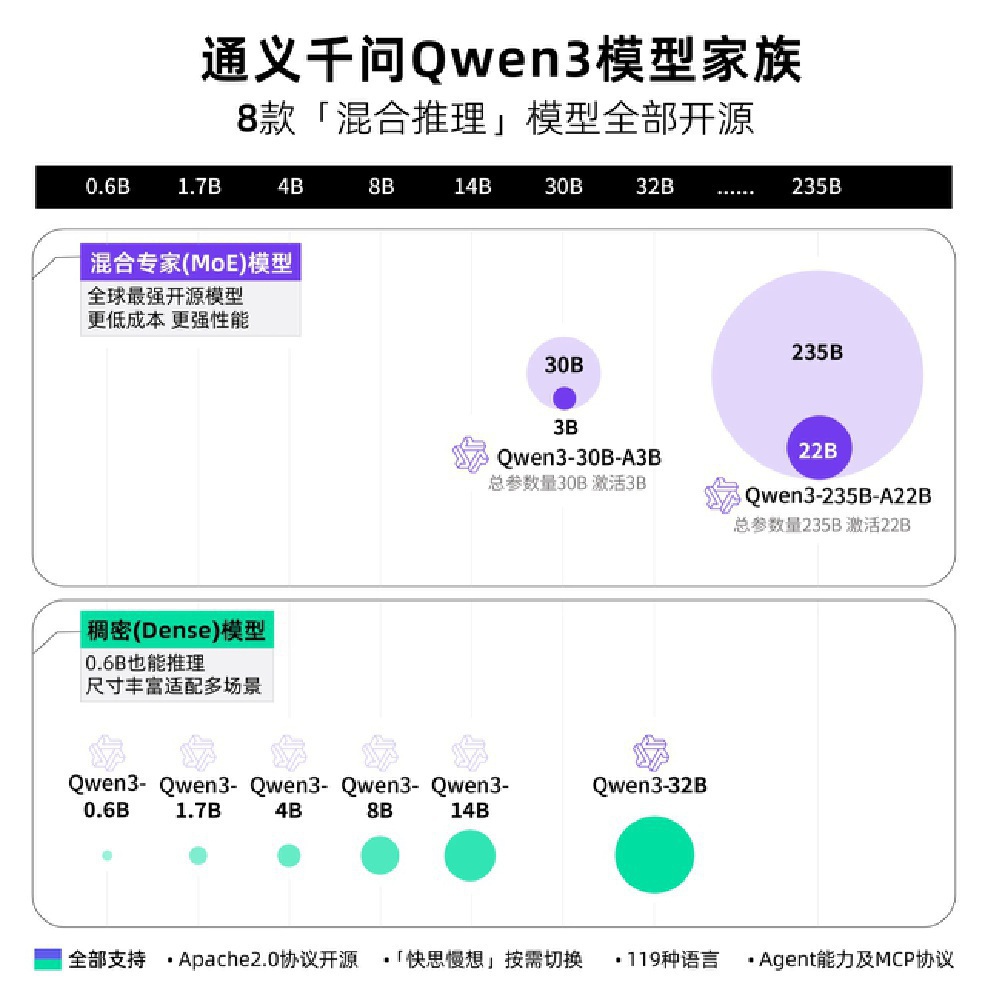
图片展示了通义千问Qwen3模型家族的完整架构,包含8款支持混合推理的开源模型,涵盖混合专家(MoE)模型和稠密(Dense)模型两大分支。从0.6B到235B的参数规模分布,突出其低成本高性能及全场景适配特性,为不同算力条件的用户提供灵活选择。
3. 256K超长上下文与多语言能力
原生支持262,144 token上下文(约6.5万字),使用YaRN技术可扩展至131K(约30万字),在法律文档分析、代码库理解等场景表现突出。多语言能力覆盖119种语言及方言,中文处理准确率达92.3%,远超Llama 3的78.5%。在RULER长文本基准测试中,模型在1000K tokens场景下准确率达82.5%,较行业平均水平提升27%。
性能对比:开源模型的新高度
根据官方提供的基准测试数据,Qwen3-235B-A22B-Thinking-2507在多项关键指标上表现优异:
- 知识能力:MMLU-Pro得分84.4,MMLU-Redux得分93.8,SuperGPQA得分64.9(排名第一)
- 推理能力:AIME25得分92.3,HMMT25得分83.9(排名第一),LiveCodeBench v6得分74.1(排名第一)
- 对齐能力:WritingBench得分88.3(排名第一),Arena-Hard v2得分79.7
- 代理能力:BFCL-v3得分71.9,TAU2-Retail得分71.9
与同类模型相比,Qwen3-235B-A22B-Thinking-2507在SuperGPQA、HMMT25、LiveCodeBench v6和WritingBench等多个权威榜单中均位居第一,展现出强大的综合性能。
行业影响:典型应用场景落地
1. 企业智能客服系统
某电商平台将Qwen3-235B-A22B-Thinking-2507部署于客服系统,简单问答启用非思考模式,GPU利用率从30%提升至75%,复杂问题自动切换思考模式,问题解决率提升28%,平均处理时间缩短40%。
2. 财务数据分析助手
通过Dify+Ollama+Qwen3构建的智能问数系统,实现自然语言到SQL的自动转换。开发者只需配置知识库和工作流,即可让业务人员通过自然语言查询销售数据,在10次测试中有9次能正确返回结果,大幅降低数据分析门槛。
3. 工业质检与合同审核
Qwen3-VL系列在工业智能质检系统中实现微米级缺陷检测,汽车零件质量控制准确率达99.2%;合同审核场景中,通过Qwen-Agent框架实现条款解析和风险提示,审核效率提升3倍,错误率降低80%。
部署与使用指南
Qwen3-235B-A22B-Thinking-2507发布72小时内,Ollama、LMStudio等平台完成适配,HuggingFace下载量突破200万次。通过SGLang或vLLM可快速部署OpenAI兼容API:
# 模型仓库地址
git clone https://gitcode.com/hf_mirrors/unsloth/Qwen3-235B-A22B-Thinking-2507-GGUF
# SGLang部署命令
python -m sglang.launch_server --model-path Qwen/Qwen3-235B-A22B-Thinking-2507 --reasoning-parser qwen3 --tp 8
# vLLM部署命令
vllm serve Qwen/Qwen3-235B-A22B-Thinking-2507 --enable-reasoning --reasoning-parser deepseek_r1
NVIDIA开发者博客指出,使用TensorRT-LLM优化后,Qwen3模型在BF16精度下推理吞吐加速比可达16.04倍,配合FP8混合精度训练技术,进一步降低显存占用。
结论与前瞻
Qwen3-235B-A22B-Thinking-2507的开源标志着大模型行业从"参数内卷"转向"效率竞争"。其混合专家架构实现了"万亿性能,百亿成本"的突破,双模式推理机制动态平衡复杂任务与高效响应,为企业级应用提供了降本增效的新路径。
对于开发者与企业,建议:
- 复杂推理场景(数学、编程)使用
/think模式,配置Temperature=0.6,TopP=0.95 - 简单交互场景启用
/no_think模式,设置Temperature=0.7,TopP=0.8以提升响应速度 - 长文本处理通过YaRN技术扩展至131K token,但建议仅在必要时启用
- 优先考虑SGLang或vLLM部署,平衡性能与开发效率
随着多模态能力融合与Agent生态完善,Qwen3系列有望在金融分析、医疗诊断等垂直领域催生更多创新应用。企业可借助阿里云PAI平台实现低成本部署,把握大模型效率革命的战略机遇。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







