导语
【免费下载链接】Ring-flash-2.0  项目地址: https://ai.gitcode.com/hf_mirrors/inclusionAI/Ring-flash-2.0
项目地址: https://ai.gitcode.com/hf_mirrors/inclusionAI/Ring-flash-2.0
2025年11月23日,蚂蚁集团百灵大模型团队正式开源高性能思考模型Ring-flash-2.0,该模型以1000亿总参数量、仅61亿激活参数的高效配置,在数学推理、代码生成等核心任务上超越400亿参数以内稠密模型,同时通过独创的icepop算法解决了MoE架构大模型强化学习训练不稳定的行业难题。
行业现状:大模型进入"效能竞赛"新阶段
2025年,大语言模型发展已从单纯的参数规模竞赛转向"性能-效率"双优赛道。据行业分析显示,企业级AI应用中推理成本占比已达65%,如何在保持高性能的同时降低部署门槛,成为大模型实用化的关键瓶颈。当前主流解决方案分为两派:一是以GPT-OSS为代表的稠密模型,通过架构优化提升效率;二是以Ring系列为代表的稀疏模型,采用MoE架构实现"按需激活"。
在此背景下,Ring-flash-2.0的开源具有标志性意义。该模型不仅延续了Ling-flash-2.0的100B总参数/6.1B激活参数的高效配置,更通过创新训练技术将复杂推理能力提升至新高度,为行业提供了一套兼顾性能与成本的解决方案。
核心亮点:icepop算法解决MoE训练稳定性难题
独创"棒冰算法"实现60天稳定训练
Ring-flash-2.0能够实现跨越式突破的核心,在于团队原创的"棒冰(icepop)"训练算法。这一机制通过"双向截断+掩码修正"的创新设计,将训练与推理阶段精度差异过大的token实时"冻结",阻止其反向传播干扰梯度更新。实验数据显示,在持续60天的强化学习训练周期中,采用icepop算法的模型损失函数曲线始终保持平稳下降趋势,而采用传统GRPO算法的对照组在第18天出现显著震荡并最终发散。
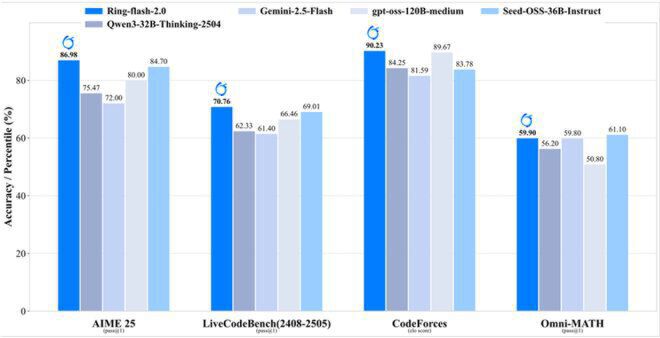
如上图所示,Ring-flash-2.0在数学推理(AIME 25)、代码生成(LiveCodeBench)、编程竞赛(CodeForces)和综合数学(Omni-MATH)四大权威榜单上的准确率均处于领先位置。其中AIME 25测试86.98分、CodeForces elo评分90.23的成绩,充分验证了icepop算法在平衡训练稳定性与推理精度上的核心价值。
三阶训练体系构建完整能力进化路径
百灵团队为Ring-flash-2.0构建了循序渐进的三阶训练体系:
- 长思维链监督微调(Long-CoT SFT):精选数学证明、代码调试等领域高质量数据,强化中间推理过程监督
- 可验证奖励强化学习(RLVR):通过符号执行器、单元测试等客观验证手段提供精准奖励信号
- 人类反馈强化学习(RLHF):优化格式规范性、内容安全性和阅读流畅度
这种分阶段训练策略使模型从"学会思考"逐步进化到"精准表达",最终形成"推理能力拔尖、实用体验友好"的均衡模型。
1/32专家激活比实现200+token/s推理速度
继承自Ling 2.0系列的高效MoE架构,是Ring-flash-2.0实现"小激活大能力"的另一关键。通过1/32的超低专家激活比例(每层仅激活3.125%的专家网络)和多任务感知路由(MTP)层等创新设计,模型在实际推理时仅激活61亿参数(扣除嵌入层后为48亿),却能实现相当于400亿参数稠密模型的推理效果。
部署测试显示,在4张H20显卡组成的基础算力平台上,Ring-flash-2.0即可实现每秒200个token以上的生成速度,将高并发场景下推理型大模型的算力成本降低60%以上。同时,通过YaRN上下文外推技术,模型原生支持128K tokens输入长度,处理万字文档摘要时相对加速比最高可达7倍。
性能表现:跨领域任务全面领先
Ring-flash-2.0在多项权威基准测试中展现出卓越性能:在GSM8K数学基准测试中达到82.3%准确率,超越同等规模的Qwen3-32B-Thinking和Seed-OSS-36B-Instruct;在GPQA-Diamond科学推理任务和HealthBench医疗问答任务中也表现出竞争力。值得注意的是,尽管主要优化方向是复杂推理,该模型在Creative Writing v3测试中仍超越所有对比模型,展现出均衡的综合能力。
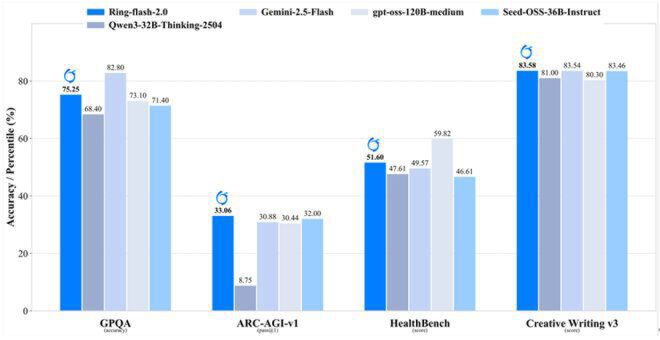
如上图所示,Ring-flash-2.0在通用推理(GPOA)、科学问答(ARC-AGI-v1)、医疗知识(HealthBench)和创意写作(Creative Writing v3)跨领域任务中,均展现出与更大模型抗衡的综合实力。这种"小而全"的特性使其特别适合资源有限但需求多样的企业级应用场景。
行业影响:推动推理型大模型实用化进程
Ring-flash-2.0的开源发布不仅提供预训练模型权重,更完整开放了"棒冰算法"实现代码、三阶训练流水线和高效推理引擎。这种全链路开源策略,使中小企业和研究机构能够以极低成本复现400亿级模型的推理能力,有望加速大模型技术在垂直领域的应用落地。
特别值得关注的是,该模型在前端研发场景已展现出实用价值。经WeaveFox团队联合优化后,Ring-flash-2.0能同时满足UI布局功能性与美学需求,为低代码开发、智能辅助编程等领域提供了新的技术选择。
快速上手与部署
在线体验
用户可通过ZenMux平台直接体验Ring-flash-2.0:https://zenmux.ai/inclusionai/ring-flash-2.0
本地部署
# 克隆仓库
git clone https://gitcode.com/hf_mirrors/inclusionAI/Ring-flash-2.0
# vLLM部署示例
git clone -b v0.10.0 https://github.com/vllm-project/vllm.git
cd vllm
wget https://raw.githubusercontent.com/inclusionAI/Ling-V2/refs/heads/main/inference/vllm/bailing_moe_v2.patch
git apply bailing_moe_v2.patch
pip install -e .
# 启动服务
python -m vllm.entrypoints.api_server --model ./Ring-flash-2.0 --tensor-parallel-size 2 --gpu-memory-utilization 0.9
结论与展望
Ring-flash-2.0通过创新的icepop算法和高效的MoE架构设计,成功解决了大模型领域"高性能与低成本难以兼顾"的核心矛盾。其在数学推理、代码生成等复杂任务上的卓越表现,以及仅需4张H20显卡即可实现200+token/s推理速度的部署优势,为大模型的实用化应用开辟了新路径。
随着开源生态的完善,我们有理由相信Ring-flash-2.0将在科研教育、企业服务、智能编程等领域发挥重要作用,推动AI技术从"实验室"真正走向"生产线"。对于开发者而言,现在正是探索这一高效思考模型潜力的最佳时机。
(注:本文所有技术参数与性能数据均来自蚂蚁集团官方开源文档及第三方实测报告,具体效果可能因部署环境和任务类型有所差异。)
【免费下载链接】Ring-flash-2.0 项目地址: https://ai.gitcode.com/hf_mirrors/inclusionAI/Ring-flash-2.0
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







