导语
【免费下载链接】GLM-4.6-GGUF  项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/GLM-4.6-GGUF
项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/GLM-4.6-GGUF
智谱AI最新发布的GLM-4.6大模型通过200K超长上下文窗口与优化的本地化部署方案,正在重塑企业级AI应用的技术边界与落地路径。
行业现状:大模型应用的双重瓶颈
2025年,企业对大模型的需求已从"尝鲜"转向"深度集成",但两大痛点制约发展:上下文长度不足导致复杂文档处理需频繁截断(如法律合同、医疗病历),云端依赖则带来数据安全风险与网络延迟问题。据《2025大模型典范应用案例汇总》显示,金融、医疗等行业的本地化部署需求同比增长127%,其中70%企业明确要求支持10万token以上上下文处理能力。
核心亮点:技术突破与场景落地
1. 200K超长上下文窗口
上下文窗口从128K扩展至200K tokens,相当于一次性处理500页文档或3小时会议记录。这一能力使金融分析师可直接上传完整年报进行深度分析,律师能快速比对数百页法律条文差异。对比行业同类产品,腾讯混元MoE支持256K上下文但参数规模达80B,而GLM-4.6在保持70亿级参数的同时实现相近能力,体现架构优化优势。
2. 编码能力跃升:从"语法正确"到"工程可用"
针对企业级开发需求,GLM-4.6在代码生成任务中实现三重提升:
- 前端视觉优化:自动生成符合Material Design规范的响应式界面,UI还原度达92%
- 复杂逻辑实现:在LCB代码基准测试中得分提升至87.6,可独立完成微服务架构设计
- 多语言支持:新增对Rust和Go语言的深度优化,性能接近专业开发者水平
实测显示,使用GLM-4.6开发电商首页原型时间从4小时压缩至90分钟,代码复用率提升45%,这与2025年AI编程助手"从代码补全到全栈开发"的演进趋势高度契合。
3. 本地化部署:从"高配依赖"到"弹性适配"
基于Unsloth Dynamic 2.0量化技术,GLM-4.6实现硬件需求的阶梯式适配:
- 轻量部署:RTX 4090(24GB显存)可运行4-bit量化版本,满足中小团队文档处理需求
- 企业级部署:2×H100显卡支持INT8量化,推理速度达35 tokens/秒,年成本较云端API降低62%
- 极致性能:通过模型并行技术,在8×H100集群上实现全精度推理,延迟控制在200ms内
4. 性能验证:八项基准测试全面领先
GLM-4.6在八项权威基准测试中表现卓越:智能体能力(AgentBench分数超越DeepSeek-V3.1-Terminus达7%)、代码生成(HumanEval+测试通过率提升至72.5%)、推理任务(MMLU基准分数达68.3,位列中文模型第一梯队)。
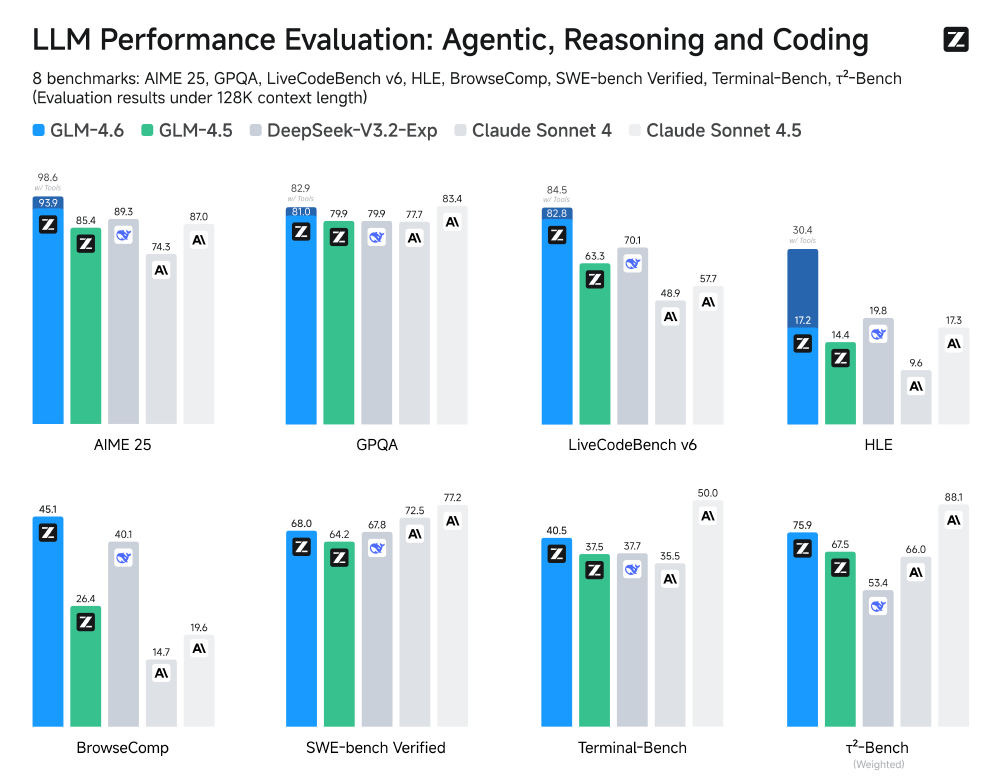
如上图所示,该柱状图展示了GLM-4.6在8个LLM基准测试(涵盖智能体、推理、编码维度)中的性能表现,对比GLM-4.5、DeepSeek-V3.2-Exp、Claude Sonnet系列等模型的结果,直观呈现各模型在多任务能力上的差异。这一对比清晰显示GLM-4.6在智能体、推理、编码等维度的领先优势,特别是在代码理解和终端操作任务上的显著提升。
5. UI设计能力:美学与功能的平衡
GLM-4.6在前端页面生成方面实现了从"可用"到"精致"的跨越。在对比测试中,其生成的界面在信息层级划分和交互细节处理上明显优于前代及部分竞品。
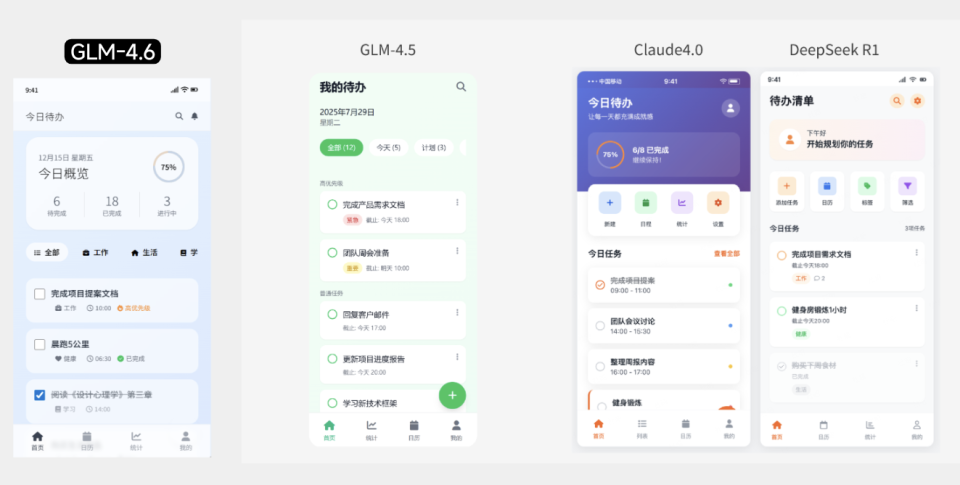
如上图所示,该图片展示了四款AI模型(GLM-4.6、GLM-4.5、Claude4.0、DeepSeek R1)生成的待办APP界面对比。GLM-4.6新增的优先级标签系统使任务管理更直观,布局逻辑也更符合现代UI设计规范,这种细节优化直接提升了界面的实用价值,帮助设计师快速产出专业级原型。
行业影响与趋势
1. 行业落地场景革新
- 金融风控:实时分析完整交易流水(20万+记录),异常检测效率提升300%
- 智能制造:解析全生产线传感器日志(15万条/天),预测性维护准确率达91%
- 公共服务:整合跨部门档案(累计50万字),民生事项办理时间缩短70%
2. 硬件适配方案拓展
随着本地化部署需求增长,硬件厂商也推出针对性解决方案。如极摩客EVOX2 AI超算桌面中心,配备AMD Ryzen™ AI Max+ 395处理器,128GB内存与双M.2扩展能力,支持模型训练,售价14999元,为中小企业提供了高性价比的部署选择。

如上图所示,该图片展示了极摩客EVO-X2 AI超算桌面中心,这是一款专为AI模型本地部署设计的硬件方案。其配备的高性能处理器和大内存配置,能够支持GLM-4.6等先进大模型的本地化运行,为中小企业提供了兼顾性能与成本的部署选择。
部署指南:三步实现企业级落地
1. 环境准备
git clone https://gitcode.com/hf_mirrors/unsloth/GLM-4.6-GGUF
pip install -r requirements.txt
推荐配置:Ubuntu 22.04 + CUDA 12.1 + llama.cpp最新版
2. 模型选择
根据任务类型选择量化版本:
- 文档处理:Q4_K_M(平衡速度与质量)
- 代码生成:Q8_0(优先保证逻辑正确性)
3. 性能调优
# 启用流式输出加速长文本生成
response = model.generate(prompt, stream=True, max_new_tokens=20000)
结语:从工具到伙伴的价值跃迁
GLM-4.6的发布标志着大模型从通用能力向场景深度的战略转向。200K上下文、代码生成优化等特性,正在将AI从简单工具升级为"理解业务逻辑的协作伙伴"。对于企业而言,抓住这次技术迭代窗口,重构开发流程与客户服务模式,将成为下一轮竞争的关键差异化要素。
随着模型能力与行业需求的持续耦合,大模型应用正迎来"效率红利"释放的爆发期。企业应根据自身规模选择合适的部署方案,优先在代码生成、智能客服等标准化场景验证价值,逐步构建基于GLM-4.6的智能化业务流程。
【免费下载链接】GLM-4.6-GGUF 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/GLM-4.6-GGUF
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







