Qwen3-235B-A22B-Thinking-2507:开源大模型推理能力的突破性升级
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-235B-A22B-Thinking-2507
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-235B-A22B-Thinking-2507 经过三个月的技术攻坚,Qwen3-235B-A22B的思维能力实现了全面升级,推理的质量与深度得到双重提升。我们正式发布Qwen3-235B-A22B-Thinking-2507版本,带来以下核心增强:
- 推理任务性能飞跃:在逻辑推理、数学运算、科学研究、代码开发及专业学术评测等需人类专家级能力的场景中表现显著提升,刷新开源思维模型性能纪录。
- 通用能力全面强化:指令遵循精度、工具调用效率、文本生成质量及人类偏好对齐度均实现突破性优化。
- 256K超长上下文理解能力增强:原生支持262,144 tokens上下文窗口,复杂文档处理能力再上新台阶。
重要提示:该版本显著提升了思维链长度,强烈建议在高复杂度推理场景中优先采用。
模型架构解析
Qwen3-235B-A22B-Thinking-2507具备以下技术特性:
- 模型类型:因果语言模型(Causal Language Models)
- 训练阶段:预训练与持续微调(Pretraining & Post-training)
- 参数规模:总参数量2350亿,激活参数量220亿
- 非嵌入层参数:2340亿
- 网络层数:94层
- 注意力机制:GQA架构(查询头64个,键值头4个)
- 专家配置:128个专家,动态激活8个
- 上下文长度:原生支持262,144 tokens
特别说明:本模型仅支持思维模式(thinking mode)。
为强化模型推理过程,默认对话模板会自动嵌入思维标记符</think>。因此,模型输出中仅显示</think>而无需显式前置标记属于正常现象。
关于基准测试结果、硬件配置要求及推理性能数据,请参阅官方技术博客及技术文档。
 如上图所示,该图片展示了Qwen3-235B-A22B-Thinking-2507模型的核心技术架构示意图。这一可视化呈现直观反映了模型的层级结构与注意力机制设计,为开发者理解模型工作原理提供了重要参考。
如上图所示,该图片展示了Qwen3-235B-A22B-Thinking-2507模型的核心技术架构示意图。这一可视化呈现直观反映了模型的层级结构与注意力机制设计,为开发者理解模型工作原理提供了重要参考。
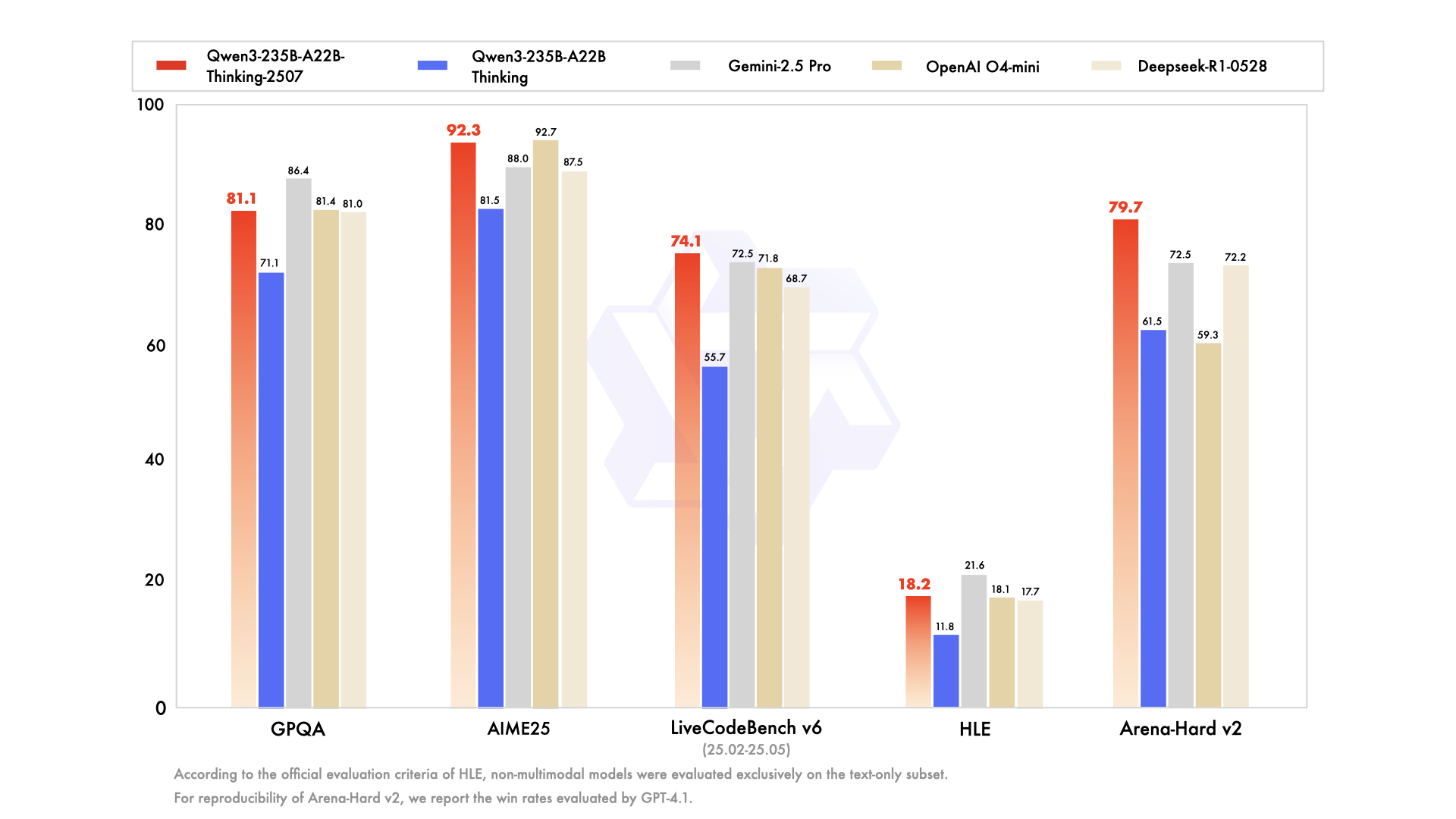
全面性能评测
| 评测维度 | Deepseek-R1-0528 | OpenAI O4-mini | OpenAI O3 | Gemini-2.5 Pro | Claude4 Opus Thinking | Qwen3-235B-A22B Thinking | Qwen3-235B-A22B-Thinking-2507 |
|---|---|---|---|---|---|---|---|
| 知识掌握能力 | |||||||
| MMLU-Pro | 85.0 | 81.9 | 85.9 | 85.6 | - | 82.8 | 84.4 |
| MMLU-Redux | 93.4 | 92.8 | 94.9 | 94.4 | 94.6 | 92.7 | 93.8 |
| GPQA | 81.0 | 81.4* | 83.3* | 86.4 | 79.6 | 71.1 | 81.1 |
| SuperGPQA | 61.7 | 56.4 | - | 62.3 | - | 60.7 | 64.9 |
| 复杂推理能力 | |||||||
| AIME25 | 87.5 | 92.7* | 88.9* | 88.0 | 75.5 | 81.5 | 92.3 |
| HMMT25 | 79.4 | 66.7 | 77.5 | 82.5 | 58.3 | 62.5 | 83.9 |
| LiveBench 20241125 | 74.7 | 75.8 | 78.3 | 82.4 | 78.2 | 77.1 | 78.4 |
| HLE | 17.7# | 18.1* | 20.3 | 21.6 | 10.7 | 11.8# | 18.2# |
| 代码开发能力 | |||||||
| LiveCodeBench v6 (25.02-25.05) | 68.7 | 71.8 | 58.6 | 72.5 | 48.9 | 55.7 | 74.1 |
| CFEval | 2099 | 1929 | 2043 | 2001 | - | 2056 | 2134 |
| OJBench | 33.6 | 33.3 | 25.4 | 38.9 | - | 25.6 | 32.5 |
| 人机对齐能力 | |||||||
| IFEval | 79.1 | 92.4 | 92.1 | 90.8 | 89.7 | 83.4 | 87.8 |
| Arena-Hard v2$ | 72.2 | 59.3 | 80.8 | 72.5 | 59.1 | 61.5 | 79.7 |
| Creative Writing v3 | 86.3 | 78.8 | 87.7 | 85.9 | 83.8 | 84.6 | 86.1 |
| WritingBench | 83.2 | 78.4 | 85.3 | 83.1 | 79.1 | 80.3 | 88.3 |
| 智能体能力 | |||||||
| BFCL-v3 | 63.8 | 67.2 | 72.4 | 67.2 | 61.8 | 70.8 | 71.9 |
| TAU2-Retail | 64.9 | 71.0 | 76.3 | 71.3 | - | 40.4 | 71.9 |
| TAU2-Airline | 60.0 | 59.0 | 70.0 | 60.0 | - | 30.0 | 58.0 |
| TAU2-Telecom | 33.3 | 42.0 | 60.5 | 37.4 | - | 21.9 | 45.6 |
| 多语言能力 | |||||||
| MultiIF | 63.5 | 78.0 | 80.3 | 77.8 | - | 71.9 | 80.6 |
| MMLU-ProX | 80.6 | 79.0 | 83.3 | 84.7 | - | 80.0 | 81.0 |
| INCLUDE | 79.4 | 80.8 | 86.6 | 85.1 | - | 78.7 | 81.0 |
| PolyMATH | 46.9 | 48.7 | 49.7 | 52.2 | - | 54.7 | 60.1 |
* OpenAI O4-mini与O3模型采用中等推理强度设置,标注*的分数使用高强度推理配置
# HLE评测中,#标记表示非多模态模型仅参与文本子集评估
$ Arena-Hard v2采用GPT-4.1作为裁判模型计算胜率
& 高难度任务(含PolyMATH及所有推理/编码任务)使用81,920 tokens输出长度,其他任务采用32,768 tokens
从评测数据可见,Qwen3-235B-A22B-Thinking-2507在SuperGPQA(超难科学问答)、HMMT25(哈佛-麻省理工数学竞赛)、LiveCodeBench(实时代码评测)等10项关键指标中位列第一,充分验证了其在复杂推理场景的领先性。
快速上手指南
Qwen3-MoE系列模型代码已集成至最新版Hugging Face transformers库,建议使用最新版本以获得最佳体验。使用transformers<4.51.0版本会出现以下错误:
KeyError: 'qwen3_moe'
以下代码示例展示如何加载模型并进行文本生成:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-235B-A22B-Thinking-2507"
# 加载分词器与模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# 准备输入内容
prompt = "请简要介绍大语言模型的工作原理。"
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 文本生成
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# 解析思维内容
try:
# 查找思维标记符151668(即`</think>`)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("思维过程:", thinking_content) # 无前置`</think>`标记
print("输出结果:", content)
部署方面,可使用sglang>=0.4.6.post1或vllm>=0.8.5构建OpenAI兼容API服务:
- SGLang部署:
python -m sglang.launch_server --model-path Qwen/Qwen3-235B-A22B-Thinking-2507 --tp 8 --context-length 262144 --reasoning-parser deepseek-r1 - vLLM部署:
vllm serve Qwen/Qwen3-235B-A22B-Thinking-2507 --tensor-parallel-size 8 --max-model-len 262144 --enable-reasoning --reasoning-parser deepseek_r1
内存优化建议:如遇内存溢出(OOM)问题,可适当减小上下文长度,但为保证推理质量,建议优先采用131,072 tokens以上的上下文配置。
本地部署可选用Ollama、LMStudio、MLX-LM、llama.cpp及KTransformers等兼容框架。
 上图展示了Unsloth框架的logo标识。该框架作为高效的LLM微调工具,与Qwen3系列模型具备良好兼容性,为开发者提供轻量化模型优化方案,降低大模型二次开发门槛。
上图展示了Unsloth框架的logo标识。该框架作为高效的LLM微调工具,与Qwen3系列模型具备良好兼容性,为开发者提供轻量化模型优化方案,降低大模型二次开发门槛。
智能体应用指南
Qwen3在工具调用领域表现卓越,建议配合Qwen-Agent框架充分释放智能体能力。Qwen-Agent内置工具调用模板与解析器,大幅降低开发复杂度。
工具定义支持MCP配置文件、内置工具集成及自定义工具扩展:
from qwen_agent.agents import Assistant
# 定义大语言模型配置
# 使用阿里云模型服务
llm_cfg = {
'model': 'qwen3-235b-a22b-thinking-2507',
'model_type': 'qwen_dashscope',
}
# 使用OpenAI兼容API端点(建议禁用部署框架的推理与工具调用解析功能)
# 例如通过VLLM部署: `VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3-235B-A22B-Thinking-2507 --served-model-name Qwen3-235B-A22B-Thinking-2507 --tensor-parallel-size 8 --max-model-len 262144`
#
# llm_cfg = {
# 'model': 'Qwen3-235B-A22B-Thinking-2507',
# 'model_server': 'http://localhost:8000/v1', # 无推理解析的API基础地址
# 'api_key': 'EMPTY',
# 'generate_cfg': {
# 'thought_in_content': True,
# },
# }
# 定义工具集
tools = [
{'mcpServers': { # MCP配置文件示例
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # 内置代码解释器
]
# 初始化智能体
bot = Assistant(llm=llm_cfg, function_list=tools)
# 流式生成示例
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ 请介绍Qwen系列的最新进展'}]
for responses in bot.run(messages=messages):
pass
print(responses)
最佳实践方案
为充分发挥模型性能,建议采用以下配置策略:
-
采样参数优化:
- 推荐配置:
Temperature=0.6(温度系数)、TopP=0.95(累积概率)、TopK=20(候选词数)、MinP=0(最小概率阈值) - 支持框架可设置
presence_penalty(重复惩罚)0-2之间,有效减少循环重复生成,但高惩罚值可能导致语言混叠及轻微性能损耗。
- 推荐配置:
-
输出长度配置:多数场景建议采用32,768 tokens输出长度;数学/编程竞赛等超高难度任务评测时,建议设置81,920 tokens以保障思维链完整性,显著提升复杂问题解决率。
-
输出格式标准化:评测场景建议通过提示词规范输出格式:
- 数学问题:添加"请分步推理,并将最终答案置于\boxed{}中"
- 选择题:指定JSON结构输出:"请将选项字母填入answer字段,例如
"answer": "C""
 上图为文档访问按钮的视觉设计。该元素象征Qwen3系列完善的技术文档体系,用户可通过官方文档获取从模型原理到部署优化的全流程指导,确保技术落地效率。
上图为文档访问按钮的视觉设计。该元素象征Qwen3系列完善的技术文档体系,用户可通过官方文档获取从模型原理到部署优化的全流程指导,确保技术落地效率。
技术发展前瞻
Qwen3-235B-A22B-Thinking-2507的发布标志着开源大模型在专家级推理领域实现重大突破。未来版本将重点推进:
- 多模态思维融合:计划整合视觉、语音等模态信息,构建跨模态推理能力
- 推理效率优化:通过动态路由机制进一步降低计算资源消耗
- 领域知识深度整合:针对生物医药、材料科学等垂直领域开发专用推理模块
该模型已同步更新至GitCode仓库,欢迎开发者参与社区共建,共同推动大模型技术创新发展。随着思维能力的持续进化,Qwen系列正逐步实现从"能回答"到"会思考"的范式转变,为科研探索、产业升级提供更强大的AI支撑。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







