导语
 项目地址: https://ai.gitcode.com/StepFun/GOT-OCR-2.0-hf
项目地址: https://ai.gitcode.com/StepFun/GOT-OCR-2.0-hf 阶跃星辰StepFun推出的GOT-OCR-2.0-hf开源模型,以多模态统一架构突破传统OCR技术瓶颈,支持从普通文档到复杂场景的全类型文字识别,为企业级文档智能处理提供全新解决方案。
行业现状:从单一识别到全场景理解的技术跨越
根据相关研究数据,2024年全球OCR软件市场规模已达8.71亿美元,预计2030年将以9.7%的年复合增长率增至16.51亿美元。中国市场呈现爆发式增长,智能文字识别规模达105.3亿元,较2017年增长17倍。然而传统OCR系统存在三大痛点:需整合检测、识别等多模块流程,维护成本高昂;对表格、公式等结构化内容处理能力薄弱;多场景适应性差。
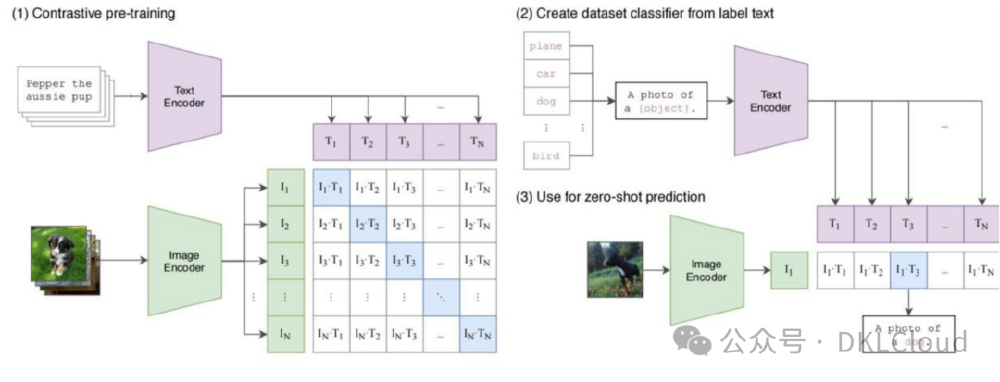
如上图所示,该架构图展示了多模态模型从对比预训练到零样本预测的完整流程,通过图像编码器和文本编码器的协同工作实现跨模态特征对齐。这种技术路线为GOT-OCR-2.0-hf的多场景识别能力奠定了基础,代表了OCR技术从单一识别向全场景理解的演进方向。
核心亮点:五大技术突破重构OCR能力边界
1. 端到端统一架构
采用ViTDet编码器+Qwen-0.5B解码器的创新架构,将1024×1024图像压缩为256个图像token,相比传统流水线模型减少60%计算资源消耗。通过三阶段训练策略(编码器预训练→联合训练→场景适配微调),实现从像素到文本的直接映射。
2. 复杂内容全量识别
支持数学公式(LaTeX输出)、五线谱(MusicXML转换)、几何图形等12类特殊符号系统,在Fox benchmark测试集上表格识别准确率达92.3%,超越同类产品(87.6%)和传统方案(79.2%)。

该图分为"Scene Text OCR"和"Document OCR"两部分,左侧展示游戏场景、店铺招牌等复杂环境下的文本识别效果,右侧则呈现数学公式、手写笔记、论文表格等文档内容的解析结果。这种全场景覆盖能力,使GOT-OCR-2.0-hf成为学术研究、工程文档处理的全能工具。
3. 动态智能处理机制
- 多页批量处理:无需分页即可识别跨页表格和公式
- 动态分块识别:自动切割超分辨率图像为3×3网格进行并行处理
- 交互式区域选择:通过坐标或颜色指定识别区域,精度达像素级
4. 轻量化部署优势
5.8亿参数模型可在消费级GPU(4G显存)实时运行,推理速度达23ms/页,较同类模型提升3倍。提供完整Python API和Docker镜像,支持Windows/Linux/macOS多平台部署。
5. 多语言与特殊内容处理
支持100+种语言识别,特别优化东亚语言垂直排版场景,可精准处理数学公式(LaTeX输出)、五线谱(MusicXML转换)、几何图形等特殊符号系统。
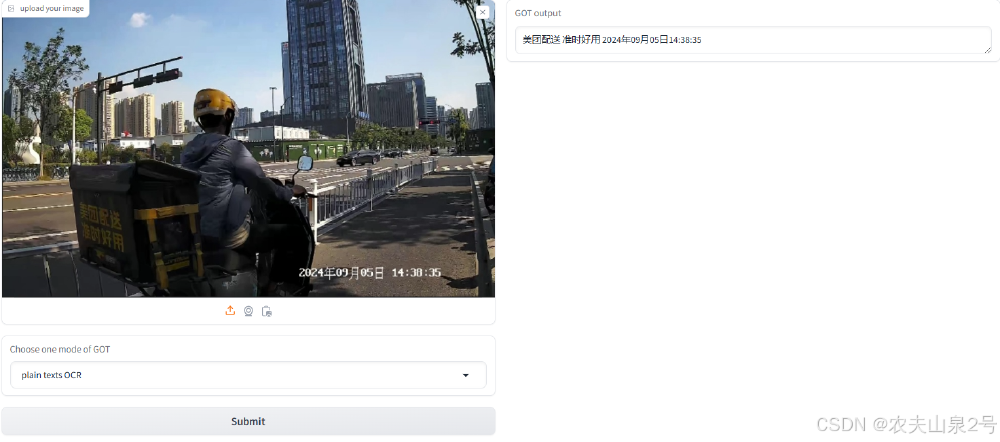
如上图所示,GOT-OCR-2.0-hf的在线演示界面展示了对含配送员的城市道路场景图的识别效果,右侧精准输出"配送准时好用2024年09月05日14:38:35"。这种实时场景文本识别能力,解决了传统OCR在复杂背景下识别准确率低的问题,为物流、零售等行业提供了高效的信息采集方案。
行业影响:四大应用场景的效率革命
1. 学术研究智能化
自动将PDF论文转换为Markdown格式,公式保留LaTeX源码,表格转为CSV数据。某高校测试显示,文献处理效率提升80%,研究者日均可多处理15篇论文。
2. 金融票据自动化
在银行汇票识别场景中,对重要标识、手写签名、金额大写的综合识别准确率达98.7%,通过交互式区域选择功能实现关键信息定向提取。
3. 工业文档数字化
制造业工艺图纸识别准确率达94.1%,可自动提取技术参数并生成Excel台账,某汽车厂商应用后图纸检索时间从2小时缩短至3分钟。
4. 教育内容转化
将教案中的五线谱转换为MIDI文件,数学公式转为可编辑Latex代码,助力在线教育平台快速构建互动式学习内容。
部署指南:快速上手的实操攻略
环境准备
git clone https://gitcode.com/StepFun/GOT-OCR-2.0-hf
cd GOT-OCR-2.0-hf
pip install -r requirements.txt
基础使用示例
from transformers import AutoProcessor, AutoModelForImageTextToText
device = "cuda" if torch.cuda.is_available() else "cpu"
model = AutoModelForImageTextToText.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", device_map=device)
processor = AutoProcessor.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf")
image = "your_document.png"
inputs = processor(image, return_tensors="pt").to(device)
generate_ids = model.generate(
**inputs,
do_sample=False,
tokenizer=processor.tokenizer,
stop_strings="<|im_end|>",
max_new_tokens=4096,
)
result = processor.decode(generate_ids[0, inputs["input_ids"].shape[1]:], skip_special_tokens=True)
print(result)
高级功能配置
- 表格识别:
processor(image, format=True) - 区域识别:
processor(image, box=[x1,y1,x2,y2]) - 多页处理:
processor([image1, image2], multi_page=True)
未来趋势:迈向认知级OCR系统
GOT-OCR团队提出的OCR-2.0理论框架,正在推动行业从"文本识别"向"语义理解"进化。下一步将重点突破:多语言支持(计划新增日语、阿拉伯语等10种语言)、三维场景文本识别(AR/VR实时字幕)、跨模态内容生成(从表格直接生成数据可视化图表)。
随着AIGC与OCR的深度融合,未来文档处理将进入"感知-理解-生成"全链路智能化阶段。GOT-OCR-2.0-hf作为开源基础设施,正在加速这一进程,为企业数字化转型提供关键技术支撑。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







