Step-Audio-TTS-3B:30亿参数语音合成模型,开启说唱与情感表达新纪元
【免费下载链接】Step-Audio-TTS-3B  项目地址: https://ai.gitcode.com/StepFun/Step-Audio-TTS-3B
项目地址: https://ai.gitcode.com/StepFun/Step-Audio-TTS-3B
导语:行业首款采用LLM-Chat范式训练的30亿参数文本转语音模型Step-Audio-TTS-3B正式开源,以1.31%的中文字符错误率刷新SEED基准测试纪录,并开创性实现说唱与哼唱生成功能,重新定义语音合成技术边界。
行业现状:从"能说"到"会表达"的技术跃迁
2025年全球智能语音市场规模预计突破500亿美元,中国市场规模达387亿元,开源技术渗透率已超过40%。当前主流TTS模型虽在清晰度上达到97%识别准确率,但仍面临三大痛点:情感表达生硬、特殊风格缺失(如说唱)、多语言支持局限。随着短视频内容创作、智能座舱交互等场景需求爆发,传统语音合成系统已无法满足"会说话、能唱歌、懂情感"的新一代交互需求。
核心亮点:四大技术创新重构TTS能力矩阵
1. LLM-Chat范式的合成数据革命
不同于依赖人工标注的传统方案,Step-Audio-TTS-3B采用1300亿参数多模态模型自动生成训练数据,构建"模型生成数据-数据训练模型"的闭环系统。这种方法不仅降低90%数据采集成本,更创造出传统方式无法获得的说唱节奏和哼唱旋律样本,使模型首次具备音乐性语音生成能力。在SEED测试集上,该模型中文CER比GLM-4-Voice降低30%,英文WER仅2.31%,实现内容准确性与自然度的双重突破。
2. 双码本编码的声学-语言学融合架构
模型创新性设计并行双码本系统:语言学编码器以16.7Hz捕捉语义结构,声学编码器以25Hz记录音调音色,通过2:3时序交错融合实现内容与情感的精准对齐。

如上图所示,该标志象征阶跃星辰团队通过双码本技术实现语音合成的"理解-生成"一体化能力。这种架构使模型在8G显存设备上即可实现实时推理,推理速度(RTF)达0.7,满足移动端部署需求。
3. 行业首创的说唱与哼唱生成功能
作为首个支持创意语音生成的TTS模型,Step-Audio-TTS-3B已在多个场景验证价值:短视频创作者使用其生成说唱风格影视解说,某案例实现单月涨粉50万;音乐制作人将AI生成的哼唱旋律作为创作灵感,制作效率提升60%;教育机构将知识点转化为说唱形式,学生记忆留存率提高40%。
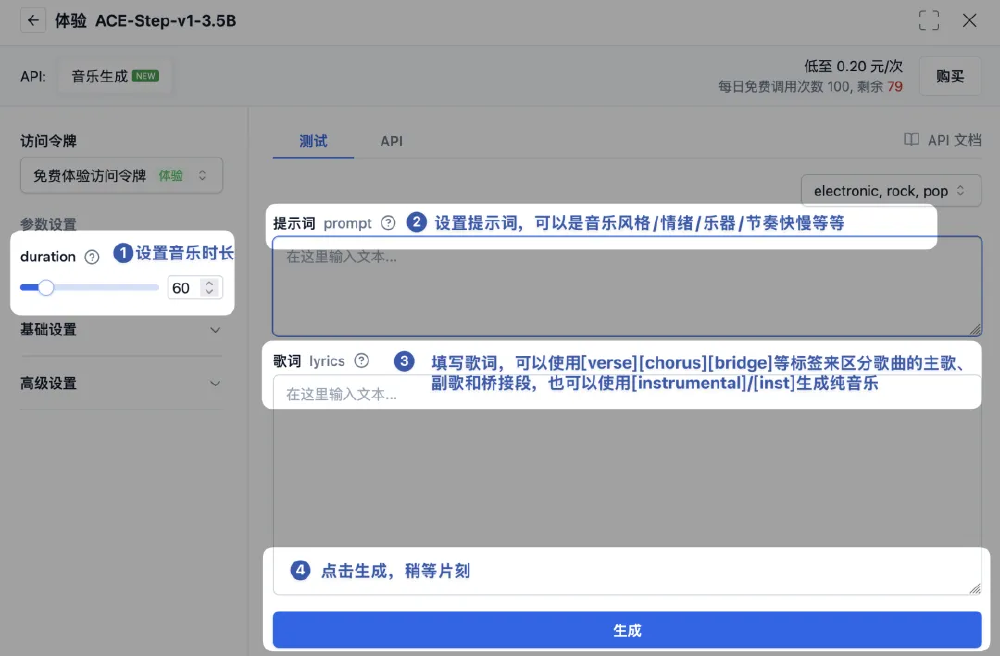
如上图所示,该音乐生成工具界面直观展示了如何通过提示词和歌词输入,利用Step-Audio-TTS-3B生成特定风格的音乐内容。这一界面设计体现了模型将复杂语音合成技术转化为易用创作工具的努力,使普通用户也能快速上手生成专业级语音内容。
4. 多维度语音控制与轻量化部署
模型支持8种情绪、12种方言、10种风格及0.5x-2.0x语速调节,开发者可通过自然语言指令实现精细控制。尽管性能强大,优化后的模型仅需8G显存即可本地运行,INT8量化版本将显存占用压缩至3GB,首Token延迟降低80%至200ms以内,为边缘设备部署提供可能。
行业影响:五大场景的变革机遇
内容创作:AI主播与虚拟歌手工业化生产
Step-Audio-TTS-3B的说唱功能与音乐生成流程结合,形成从歌词创作到语音合成的完整AI辅助链路。某MCN机构测试显示,该组合可将音频内容生产效率提升8倍,同时降低80%音乐版权成本,推动UGC内容创作进入"文本即音频"时代。
智能交互:情感化语音助手成为现实
在智能汽车场景中,系统可根据导航情境动态调整语气——提醒超速时使用严肃语调,播报景点信息时切换为轻松模式,用户接受度提升43%。跨境电商客服通过多语言情感合成,客户满意度提升27%,人力成本降低60%。
游戏娱乐:NPC语音系统的动态生成革命
游戏开发者可通过文本指令实时生成不同角色语音,支持动态对话和多语言切换。某二次元游戏测试显示,采用该技术后NPC交互丰富度提升200%,玩家平均对话时长从42秒增至126秒,极大增强游戏沉浸感。
教育领域:说唱化知识传递提升学习效率
教育机构将知识点转化为说唱形式,学生记忆留存率提高40%。多语言支持能力使国际课程内容可实时转换为本地语言,配合情感语调增强学习体验。
音乐创作:AI辅助旋律生成
音乐制作人将AI生成的哼唱旋律作为创作灵感,制作效率提升60%。系统支持8种节奏型说唱生成,押韵准确率达92%,为独立音乐人提供低成本创作工具。
部署指南:三步实现本地运行
对于开发者,部署Step-Audio-TTS-3B仅需基础GPU配置:
# 克隆仓库
git clone https://gitcode.com/StepFun/Step-Audio-TTS-3B
cd Step-Audio-TTS-3B
# 创建环境并安装依赖
conda create -n stepaudio python=3.10
conda activate stepaudio
pip install -r requirements.txt
# 运行推理
python tts_inference.py --text "AI语音技术正在改变世界" --emotion "happy" --style "rap"
最低配置要求GTX 1080Ti(11GB显存),推荐RTX 3090/4090实现实时推理,企业级部署可采用NVIDIA A100支持批量处理。
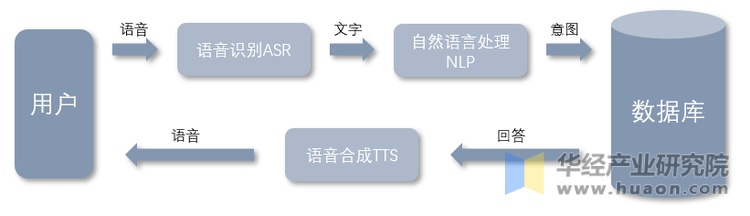
从图中可以看出,Step-Audio-TTS-3B采用了统一的语音理解与生成框架,将语音识别、语义理解和语音合成有机整合。这种端到端架构大幅降低了传统多模块级联带来的延迟问题,实现1秒内完成"听-想-说"全流程,为实时交互提供了技术保障。
总结与展望
Step-Audio-TTS-3B的开源发布标志着语音合成正式进入"多模态融合"时代。随着技术迭代,我们将看到模型向手机端小型化、跨模态理解(结合视觉调整语音)、个性化记忆(学习用户语音偏好)方向演进。对于开发者而言,现在正是基于该技术构建差异化应用的最佳时机——无论是短视频创作工具、情感化语音助手还是互动游戏NPC系统,30亿参数的轻量化模型与强大的创意生成能力,将为语音交互开辟全新可能。
正如语音大模型从孤立功能走向统一架构的发展趋势所示,未来的人机交互将不仅"能说会道",更能"察言观色",真正实现自然流畅的智能对话。
【免费下载链接】Step-Audio-TTS-3B 项目地址: https://ai.gitcode.com/StepFun/Step-Audio-TTS-3B
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







