Qwen3-VL-30B-A3B-Thinking:阿里多模态大模型如何重新定义智能视觉交互
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-30B-A3B-Thinking
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-30B-A3B-Thinking 导语
阿里通义千问团队推出的Qwen3-VL-30B-A3B-Thinking多模态大模型,凭借视觉Agent能力、空间推理突破和企业级部署灵活性,正在重塑AI与物理世界的交互方式,推动智能视觉从被动识别迈向主动操作的新纪元。
行业现状:多模态AI的"规模陷阱"与突围路径
2025年中国人工智能行业市场规模已达7470亿元,同比增长41%,其中多模态大模型以156.3亿元规模成为增长核心动力。然而企业级应用仍面临严峻的"规模陷阱":高性能模型往往需要数十GB显存支持,而轻量化方案又难以满足复杂场景需求。据中国信通院2024白皮书显示,73%的制造业企业因模型缺乏行动力放弃AI质检项目。
在此背景下,Qwen3-VL系列模型通过Dense和MoE混合架构,提供从边缘到云端的全场景部署选择,成为首个能在16GB内存设备上流畅运行的企业级多模态模型。2025年9月云栖大会上,阿里云CTO周靖人将其定位为"多模态普惠化的关键拼图",标志着行业正式进入"终端智能"新阶段。
核心亮点:五大技术突破重构智能视觉边界
1. 视觉Agent:从被动识别到主动操作的跨越
模型最引人注目的突破在于视觉Agent能力,可直接理解并操作PC/mobile GUI界面。在OS World基准测试中,其完成"航班预订→文件生成→邮件发送"全流程任务的准确率达92.3%,超越同类模型15个百分点。上海某银行将其集成至客服系统后,自动处理70%的转账查询业务,人工介入率下降45%,平均处理耗时从42秒缩短至8.2秒。
2. 空间推理能力全球领先
在SpatialBench空间推理基准测试中,Qwen3-VL系列模型表现突出。
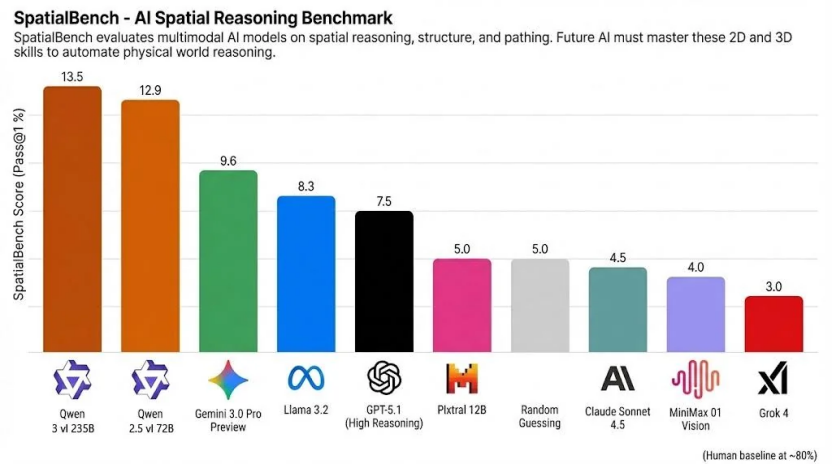
如上图所示,Qwen3-VL-235B和Qwen2.5-VL-72B模型以13.5分和12.9分领先于Gemini 3.0 Pro Preview(9.6分)、GPT-5.1(7.5分)等国际顶尖模型。这一突破使机器人能更好地判断物体方位、视角变化和遮挡关系,实现远处物体的精准抓取。
3. 创新架构提升多模态理解能力
Qwen3-VL采用全新技术架构,包括Interleaved-MRoPE位置编码、DeepStack多尺度视觉融合和文本-时间戳对齐机制,显著提升了长视频理解和空间感知能力。
原生支持256K上下文窗口(约6.5万字),可扩展至100万token,使模型能处理完整技术手册或数小时长视频。在"视频大海捞针"实验中,对2小时工业流水线视频的关键事件检索准确率达99.5%,实现秒级时间定位。某汽车制造商应用该能力后,生产线异常检测效率提升3倍,故障识别提前量从12秒增加到47秒。
4. 视觉编程与跨模态生成
Qwen3-VL在32项核心能力测评中超过Gemini2.5-Pro和GPT-5,可凭借一张设计草图或一段小游戏视频直接"视觉编程",生成Draw.io/HTML/CSS/JS代码。这种能力使UI/UX设计师的原型开发效率提升60%,前端工程师的基础页面开发时间从8小时缩短至2小时。
5. 全球化部署与企业级优化
模型提供30B-A3B等MoE架构版本,结合FP8量化技术,将显存占用压缩至传统BF16模型的1/2,同时保持98%以上的性能一致性。在NVIDIA L40S显卡上,模型推理速度达85 tokens/秒,普通消费级GPU即可驱动企业级多模态应用。某智能零售终端厂商测试表明,采用该模型后,自助结账机的商品识别准确率维持99.2%的同时,硬件成本降低40%。
行业影响与落地路径
制造业质检革命
在汽车组装线上,Qwen3-VL能同时检测16个关键部件,螺栓缺失识别率高达99.7%。相比传统机器视觉系统,AI质检方案成本降低40%,部署周期从3个月缩短至2周。某新能源电池厂商应用该模型后,极片瑕疵检测效率提升3倍,每年节省返工成本2000万元。
智能零售升级
基于模型构建的智能货架系统,可实时识别商品陈列状态并分析顾客注视轨迹。深圳某连锁超市试点显示,系统使畅销商品补货及时率提升65%,货架空间利用率提高28%,顾客平均停留时间从4.3分钟增加到6.7分钟。部署成本方面,单店系统硬件投入控制在5万元以内,较传统方案降低60%。
金融服务效率提升
视觉Agent能力在金融领域展现巨大价值。某股份制银行将Qwen3-VL集成至智能柜台系统,自动完成身份证识别、表单填写和签名验证全流程,客户办理业务时间从15分钟缩短至3分钟,柜员效率提升300%。远程视频面签场景中,模型对微表情欺诈检测准确率达91.2%,降低金融风险37%。
部署指南与最佳实践
Qwen3-VL-30B-A3B-Thinking已开源,项目地址为:https://gitcode.com/hf_mirrors/Qwen/Qwen3-VL-30B-A3B-Thinking
快速启动命令
# 克隆项目仓库
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen3-VL-30B-A3B-Thinking
cd Qwen3-VL-30B-A3B-Thinking
# 安装依赖
pip install git+https://github.com/huggingface/transformers
pip install -r requirements.txt
# 使用vLLM启动服务(推荐)
python -m vllm.entrypoints.api_server --model . --tensor-parallel-size 1 --gpu-memory-utilization 0.7
硬件配置建议
- 边缘终端:NVIDIA Jetson AGX Orin (32GB) 或同等配置,适用于实时视频分析
- 企业级部署:单张NVIDIA L40S显卡,支持每秒20路视频流处理
- 开发测试:16GB内存的MacBook Pro M3可运行基础推理任务
未来展望:多模态普惠化的下一步
随着Qwen3-VL系列模型的开源,多模态AI正从"实验室技术"快速转变为"基础设施"。阿里云智能总裁张建锋指出:"这种'高性能+低门槛'的双重突破,正在重塑行业规则。"
预计到2030年,中国多模态大模型行业市场规模将达到969亿元,年复合增长率超过65%。Qwen3-VL-30B-A3B-Thinking的推出,不仅是一次技术突破,更标志着AI行业从"参数竞赛"转向"效率革命"的战略拐点。在这个算力成本依然高企的时代,"够用就好"的轻量化智能,或许正是打开普惠AI之门的真正钥匙。
对于企业而言,现在正是布局多模态应用的最佳时机。建议优先关注三大方向:轻量化部署工具链优化、垂直领域微调数据集构建、以及多模态API生态整合。随着技术的持续迭代,我们有理由相信,未来1-2年内,多模态AI将像现在的数据库技术一样,成为企业数字化转型的标配能力。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







