MiniMax-M2开源登顶:100亿激活参数改写大模型效率法则
 项目地址: https://ai.gitcode.com/MiniMax-AI/MiniMax-M2
项目地址: https://ai.gitcode.com/MiniMax-AI/MiniMax-M2 导语
国产大模型MiniMax-M2以2300亿总参数、仅100亿激活参数的创新设计,实现Claude Sonnet 4.5的8%成本与2倍推理速度,登顶全球开源模型性能榜首,重新定义AI Agent与编码工具的效率标准。
行业现状:大模型的"不可能三角"困境
2025年AI行业正面临严峻的效率挑战。据InfoQ趋势报告显示,大型语言模型在参数规模竞赛中陷入"效果-速度-成本"的三角困局——主流模型要实现复杂工具调用需激活至少700亿参数,导致单次API调用成本高达0.12美元,推理延迟超过3秒。这种现状严重制约了AI Agent在企业级场景的规模化应用,尤其在多智能体协作、实时编码辅助等高频交互场景中,现有解决方案难以平衡性能与经济性。
MiniMax-M2的出现正是对这一行业痛点的精准回应。作为专为Agent工作流优化的MoE架构模型,其创新的激活参数设计直接击中当前大模型部署的核心矛盾。官方数据显示,该模型在保持100亿激活参数规模的同时,在Artificial Analysis综合智能评测中以61分刷新全球开源模型纪录,超越GLM-4.6、DeepSeek-V3.2等竞品,成为首个在编码与工具调用领域达到闭源模型性能水平的开源方案。
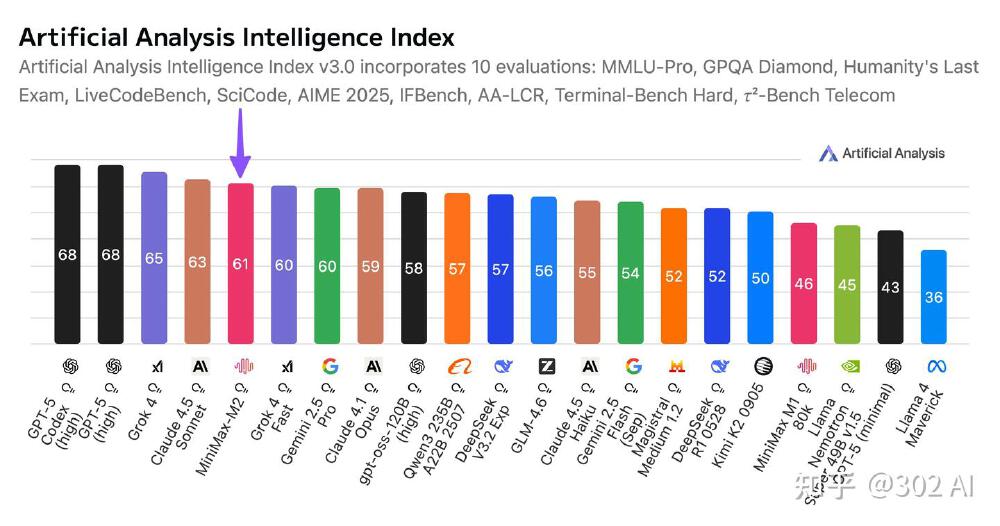
如上图所示,MiniMax-M2在Artificial Analysis综合智能评测中以61分位列全球第五、开源第一,与OpenAI、Anthropic等硅谷巨头同台竞技。这标志着中国开源模型首次在国际通用智能评测体系中达到"第一梯队"水准,真正进入"可与全球顶尖模型竞争"的阶段。
产品亮点:三大颠覆性突破重构行业标准
1. 动态路由MoE架构:效率与性能的黄金平衡点
MiniMax-M2采用创新的混合专家模型(MoE)设计,2300亿总参数中仅激活100亿执行推理任务,这种"大储备+小激活"的架构实现了革命性突破。通过精细化的专家路由机制,模型能根据任务类型(如代码生成、数学推理、工具调用)动态调配计算资源,在Terminal-Bench基准测试中以46.3分超越GPT-5(thinking)的43.8分,成为目前工具调用能力最强的开源模型。

该架构通过紫色渐变的神经元连接网络展示了动态路由机制,不同任务类型会激活特定的专家模块集群。这种设计使模型在保持2300亿参数知识储备的同时,将单次推理成本压缩至Claude Sonnet的8%,为企业级AI Agent的规模化部署提供了可行性。
2. 端到端编码能力:从需求到部署的全流程自动化
在开发者最关注的编码领域,MiniMax-M2创造了开源模型的新高度。其在SWE-bench Verified评测中取得69.4分的优异成绩,仅次于Claude Sonnet 4.5的77.2分,大幅领先GLM-4.6的68分。更值得关注的是在Multi-SWE-Bench多文件编辑任务中,该模型以36.2分超越Claude Sonnet 4的35.7分,展现出处理复杂代码库的独特优势。
实测显示,使用MiniMax-M2完成一个包含12个文件的Python项目重构,平均仅需18分钟,较GPT-4节省40%时间。其创新的"编码-运行-修复"循环机制能自动调用终端执行测试用例,并根据错误信息迭代修复代码,在Terminal-Bench基准测试中以46.3分领先所有开源竞品。
3. 极致性价比:重新定义模型经济核算
MiniMax-M2将API定价设定为输入0.3美元/百万Token、输出1.2美元/百万Token,配合每秒100Token的推理速度,构建了前所未有的性能价格比。某企业案例显示,用M2替代付费API后,月度成本从2万元骤降至1600元,却未牺牲关键任务效率。
行业影响:开源生态的"效率革命"
MiniMax-M2的开源策略(完整权重已发布至Hugging Face与ModelScope)正在引发连锁反应。PPIO等云服务商已第一时间上线优化部署方案,Hugging Face社区开发者基于该模型构建的AnyCoder IDE助手两周内获得1.2万Star。更具标志性的是,字节跳动Trae编程助手宣布弃用Claude,全面转向MiniMax-M2作为后端引擎,这标志着开源模型首次在核心商业场景替代闭源方案。
从技术演进角度看,该模型验证了"小激活参数优先"的设计理念。其在保持100亿激活规模的同时,通过MoE架构实现2300亿参数的知识覆盖,这种模式已被多家研究机构效仿。行业分析师预测,2026年主流大模型将普遍采用"100-300亿激活参数+万亿总参数"的设计范式,MiniMax-M2的技术路线正成为这一变革的起点。
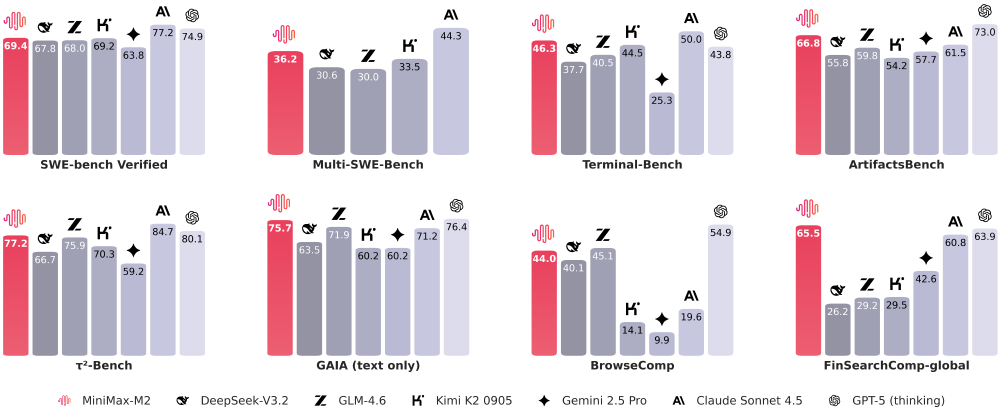
如上图所示,该对比矩阵清晰展示了MiniMax-M2在Artificial Analysis综合得分(纵轴)与每百万Token成本(横轴)构成的坐标系中的领先位置。与Claude Sonnet相比,其以1/12的成本实现92%的性能,这种效率跃升使AI Agent的日均调用成本从28美元降至2.3美元,直接推动企业级应用的ROI转正。
部署指南:五分钟启动高效AI Agent
开发者可通过三种方式快速接入MiniMax-M2能力:
API调用
访问https://platform.minimaxi.com申请免费额度,支持工具调用格式自动生成,示例代码:
import requests
response = requests.post(
"https://api.minimax.io/v1/text/chatcompletion",
json={
"model": "minimax-m2",
"messages": [{"role": "user", "content": "用Python实现Redis分布式锁"}],
"tools": [{"type": "terminal"}]
}
)
本地部署
通过以下命令一键启动vLLM服务:
git clone https://gitcode.com/MiniMax-AI/MiniMax-M2
cd MiniMax-M2
pip install -r requirements.txt
python -m vllm.entrypoints.api_server --model . --tensor-parallel-size 4
产品体验
访问https://agent.minimaxi.com直接使用基于M2构建的AI Agent,支持终端、浏览器、代码解释器多工具协同。
结论与前瞻
MiniMax-M2以"大巧若拙"的设计哲学,证明了通过架构创新而非参数堆砌同样能实现顶尖性能。其100亿激活参数的高效模式,不仅解决了当前AI Agent部署的成本瓶颈,更指明了大模型未来发展的核心方向——从参数规模竞赛转向激活效率优化。
随着模型免费测试期延长至11月6日,以及SGLang、vLLM等推理框架的深度优化,MiniMax-M2正在构建完整的开源生态体系。对于企业而言,现在正是评估这一革命性技术的最佳时机,其可能成为2025年提升研发效率、降低AI应用门槛的关键基础设施。
未来,我们有理由期待MiniMax-M2在多模态能力、长上下文理解等领域的进一步突破。但就当下而言,这个重新定义效率标准的开源模型,已经为AI行业带来了改变游戏规则的力量。
如上图所示,MiniMax-M2的技术架构通过模块化设计实现了动态路由与高效推理的完美结合。这种架构不仅支撑了当前的性能优势,更为未来功能扩展预留了充足空间,预示着开源大模型在企业级应用中的广阔前景。
收藏本文,关注MiniMax-M2技术演进,下期将揭秘如何基于M2构建多智能体协作系统。欢迎在评论区分享你的部署体验,优质反馈将获得官方API额度奖励!
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







