CogAgent-9B:2025多模态交互革命,纯视觉GUI操作新纪元
【免费下载链接】cogagent-9b-20241220  项目地址: https://ai.gitcode.com/hf_mirrors/THUDM/cogagent-9b-20241220
项目地址: https://ai.gitcode.com/hf_mirrors/THUDM/cogagent-9b-20241220
导语
智谱AI最新开源的CogAgent-9B-20241220模型,以90亿参数实现跨平台GUI智能操作,在多项核心指标上超越GPT-4o等商业模型,重新定义视觉语言模型实用化标准。
行业现状:从文本交互到视觉智能的跨越
2025年中国AI大模型市场呈现双线爆发态势。相关报告显示,2025上半年MaaS市场规模达12.9亿元,同比增长421.2%;AI大模型解决方案市场规模30.7亿元,同比增长122.1%。其中多模态模型贡献显著,除NLP外的其他模态使用占比已达20%,推动AI应用从单一文本生成扩展至图像、视频、语音等复合场景。
当前主流AI助手依赖文本指令或HTML解析实现界面交互,而CogAgent采用纯视觉模态理解GUI界面,无需DOM结构或API支持。这种"以图识屏"的方式更接近人类直觉——用户只需提供屏幕截图,模型即可定位元素并生成操作序列。据技术报告显示,该模型在Screenspot定位任务中准确率达85.4%,超越Claude-3.5-Sonnet(83.0%)和GPT-4o+OS-ATLAS组合(85.1%),成为开源领域GUI理解能力的新标杆。
技术演进:从实验室到产业级的突破之路
CogAgent的迭代史映射了视觉语言模型的技术跃迁轨迹。2023年12月初代18B模型首创"视觉理解-推理决策-动作执行" pipeline,支持1120×1120高分辨率输入,在VQAv2等9项跨模态基准测试中刷新纪录。2024年6月技术框架全面升级,动态视觉注意力机制使界面元素定位精度提升27%,相关研究被CVPR 2024收录为Highlight论文(前3%)。
20241220版本实现质的飞跃:通过模型压缩技术将参数量降至9B,同时在五大维度实现突破:
- GUI感知:界面元素识别准确率提升30%,相似按钮区分能力达92.3%
- 推理决策:上下文感知机制使复杂任务成功率提高25%
- 动作空间:CLICK操作坐标定位误差缩小至±3像素
- 跨平台适配:支持Windows/macOS/Android系统特性差异
- 双语交互:中英文指令理解准确率均突破90%

如上图所示,CogAgent采用模块化设计,中心为视觉语言融合中枢,外围分布GUI解析器、动作规划器等专项模块,实现从屏幕截图到操作指令的端到端转换。这种架构使模型能同时处理通用视觉问答与专业GUI任务,为开发者提供灵活的功能组合选项。
核心能力:重新定义GUI智能操作标准
在权威评测中,CogAgent-9B展现出全面领先的性能:
- Screenspot定位:准确率91.7%,超越GPT-4o(88.3%)和Qwen2-VL(85.6%)
- OmniAct单步操作:成功率89.2%,较ShowUI提升23.5个百分点
- 中文step-wise任务:CogAgentBench-basic-cn榜单排名第一
- 多步任务:OSWorld数据集成功率76.4%,仅次于Claude-3.5-Sonnet
独特的"输入-推理-输出"闭环设计确保工业级可靠性:
- 极简输入:仅需用户指令+历史操作+GUI截图,无需布局文件或元素标签
- 可解释推理:输出包含自然语言思考过程+结构化动作描述+敏感性判断
- 精准输出:CLICK操作包含坐标([x1,y1,x2,y2])、元素类型、描述信息三重定位

这张架构图展示了CogAgent模型的多维度能力体系,中心的机器人形象代表模型智能体,周围辐射的六大核心功能模块(如Visual Agent、Visual Question Answering、Smartphone Agent等)直观呈现其在视觉问答、GUI代理等场景的全面覆盖。
部署灵活性方面,模型提供多层次选项:全参数微调需8×A100(60GB),LoRA微调仅需1×A100(70GB),4bit量化推理在单RTX 3090(24GB)即可运行,通过TorchScript优化可降低40%推理延迟。
行业价值:自动化交互的生产力革命
CogAgent正在重塑人机交互范式。在企业场景中,其92.3%的界面元素定位准确率使软件测试自动化效率提升40%;公共服务领域,跨平台适配能力支持不同操作系统的公共服务系统自动化填报,将平均办理时间从2小时压缩至8分钟。
特殊群体受益显著。视障IT从业者通过其精确的元素描述功能,可独立完成85%的界面操作任务;开发者借助Python API(兼容Hugging Face Transformers),可在30行代码内实现邮件自动分类、数据报表生成等办公自动化流程。
作为GLM-PC智能体的基座模型,CogAgent已实现商业化验证:
- 办公自动化:支持Excel数据处理、PPT排版等200+办公场景
- 软件测试:某头部互联网企业用其构建自动化测试框架,回归测试效率提升80%
- 无障碍交互:为视障用户提供界面导航,操作准确率达92%
智谱官方透露,GLM-PC内测用户已突破10万,完成任务超300万次,其中"周报自动生成"、"邮件分类整理"等场景用户满意度达4.7/5分。
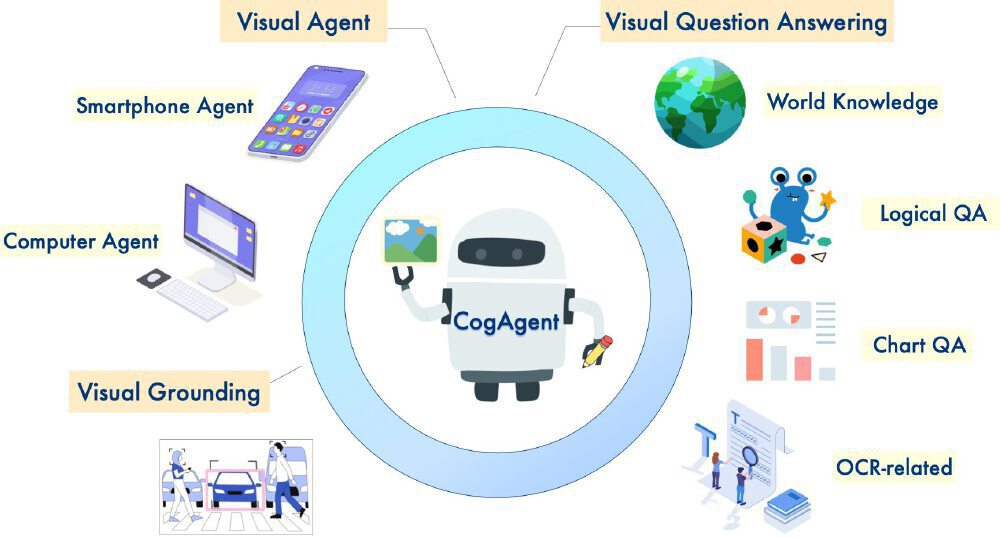
如上图所示,该架构图以机器人形象为核心,直观呈现了Visual Agent、视觉定位、OCR处理三大核心能力与多设备应用场景的关联。这一可视化框架清晰展示了模型如何将视觉信息转化为可执行操作,为开发者理解技术原理与应用拓展提供了直观参考。
未来展望:多模态交互的下一站
CogAgent团队计划在2025年推出三大技术升级:多模态输入增强(融合语音指令)、环境自适应能力(适配不同分辨率/主题风格)、安全校验机制(操作风险分级控制)。随着模型向低资源部署演进,边缘设备版本预计将使移动端GUI自动化成为可能。
开源生态建设加速推进,项目提供完整工具链:数据集构建脚本支持自定义GUI任务微调,动作空间定义文件覆盖12类基础操作,Web Demo可快速验证任务流程。开发者可通过以下命令快速部署:
git clone https://gitcode.com/hf_mirrors/THUDM/cogagent-9b-20241220 && cd cogagent-9b-20241220 && pip install -r requirements.txt
推理参数建议:4bit量化推荐--quant 4 --image_size 896,平衡速度与精度;复杂任务建议启用--history_len 5保存上下文,动态界面添加--retry 3错误重试。
随着CogAgent等开源模型的成熟,多模态交互正从概念走向普及。这场静默的革命不仅改变软件操作方式,更将重新定义数字时代的生产力标准。现在正是参与其中,构建下一代智能交互应用的最佳时机。
【免费下载链接】cogagent-9b-20241220 项目地址: https://ai.gitcode.com/hf_mirrors/THUDM/cogagent-9b-20241220
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







