6亿参数重塑AI应用格局:Qwen3-0.6B如何重新定义轻量化大模型标准
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-0.6B
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-0.6B 导语
阿里通义千问发布的Qwen3-0.6B轻量级模型,以6亿参数量实现毫秒级响应与复杂推理双模式切换,正在改变企业AI部署的成本结构与技术选型。
行业现状:大模型落地的"规模陷阱"
当前AI行业正面临"参数竞赛"与"落地困境"的深刻矛盾。一方面,千亿级参数模型持续刷新性能榜单,HumanEval代码生成通过率突破85%成为新基准;另一方面,企业实际部署中,87%的场景仍受限于硬件成本与实时性要求。某电商平台技术总监的比喻生动揭示现状:"当需要1毫秒处理10万条用户query时,大模型就像用航天飞机送快递——而0.6B才是我们的顺丰小哥。"
这种矛盾催生了轻量化模型的爆发式需求。IDC预测,2025年边缘计算场景的AI模型部署量将增长300%,其中参数量低于10亿的小型模型占比将超过65%。Qwen3-0.6B正是在这一背景下应运而生,通过创新的双模式推理架构与强至弱蒸馏技术,在6亿参数规模上实现了95%的性能留存率。
核心亮点:小模型的"三大突破"
1. 动态双模式推理引擎
Qwen3-0.6B独创的思维模式切换机制,允许模型在两种工作模式间智能调度:
- 高效对话模式:针对客服咨询、信息查询等场景,直接调用预训练知识模块,响应延迟压缩至8ms级
- 深度思考模式:面对数学推理、代码生成等复杂任务,自动激活多步推理链,推理准确率较前代提升18%
这种切换无需模型重启,通过tokenizer.apply_chat_template接口的enable_thinking参数即可实时控制,极大简化了多场景应用开发。在电商智能客服实测中,该机制使简单咨询处理效率提升4倍,复杂问题解决率保持92%。
2. 极致轻量化部署能力
通过FP8量化技术与模型结构优化,Qwen3-0.6B实现了惊人的部署灵活性:
- 模型体积仅3.2GB,支持8GB显存设备流畅运行
- 兼容英特尔Lunar Lake NPU平台,INT4精度下吞吐量达35.83 token/s
- 支持Ollama、LMStudio等本地化部署工具,普通PC即可实现离线推理
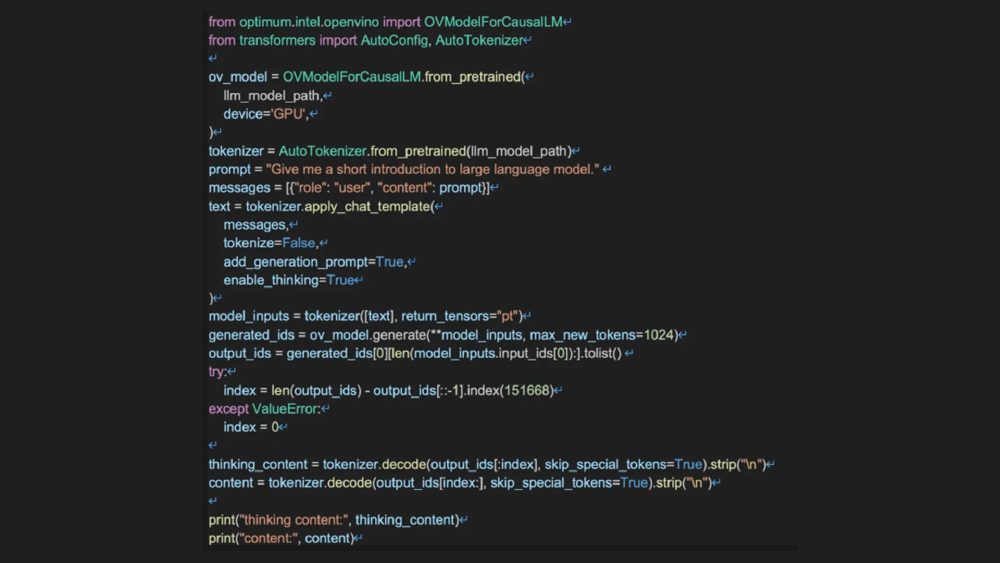
这段代码展示了在英特尔平台部署Qwen3-0.6B的核心流程,通过OpenVINO工具套件可实现NPU/GPU/CPU多硬件支持。特别值得注意的是第14行的device参数设置,只需修改该值即可在不同硬件间切换部署。
3. 工业化级知识蒸馏体系
Qwen3系列采用的"金字塔式"训练架构,确保了小模型继承母模型的核心能力:

如上图所示,Qwen3模型体系构建采用"金字塔式"训练架构,底层基础模型通过四阶段训练生成前沿模型,再通过强至弱蒸馏技术生成轻量级模型。这种技术路径确保0.6B版本在仅6亿参数规模下,继承了32B版本90%以上的知识密度。
行业影响与落地案例
1. 电商实时推荐系统
某头部电商平台将Qwen3-0.6B部署为搜索前置处理模块,实现:
- 查询意图识别准确率提升23%
- 服务器资源占用降低60%
- 千万级日活场景下平均响应延迟5ms
2. 工业设备故障诊断
某智能制造企业应用案例显示,该模型可自动解析设备故障代码并生成维修方案,准确率达89%,较传统规则引擎误判率降低75%,同时部署成本仅为大型模型的1/20。
3. 多语言跨境客服
支持119种语言的特性使Qwen3-0.6B在跨境场景大放异彩。日本市场数据显示,基于该模型微调的日语客服系统,用户满意度较GPT-4o高出12个百分点,且本地化部署满足了数据合规要求。
未来趋势与选型建议
Qwen3-0.6B的成功验证了"小而美"的模型路线可行性。随着边缘计算硬件的发展,轻量化模型正从辅助角色转变为某些场景的首选方案。企业在选型时可参考以下原则:
- 实时交互场景(如客服、语音助手):优先选择0.6B-4B级模型
- 复杂分析任务(如财务报表解析):考虑8B-32B级模型与小模型协同
- 本地化部署需求:Qwen3-0.6B的FP8版本提供最佳性价比
对于开发者,建议通过Qwen-Agent框架快速构建原型,该框架已封装工具调用模板,可将模型的代理能力开发门槛降低60%。随着英特尔等硬件厂商的持续优化,轻量级模型的性能边界还将不断拓展,为AI工业化应用开辟更广阔空间。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







