2025边缘AI革命:LFM2-2.6B以26亿参数重塑智能终端计算范式
【免费下载链接】LFM2-2.6B  项目地址: https://ai.gitcode.com/hf_mirrors/LiquidAI/LFM2-2.6B
项目地址: https://ai.gitcode.com/hf_mirrors/LiquidAI/LFM2-2.6B
导语
Liquid AI推出的LFM2-2.6B轻量级大模型以26亿参数实现3倍训练速度提升和2倍CPU推理加速,重新定义智能终端本地计算标准,为边缘AI应用开辟新路径。
行业现状:从云端依赖到终端智能的转型浪潮
2025年全球AI智能终端市场正以爆发式速度增长。根据智研咨询数据,中国AI智能终端市场规模已从2021年的36.66亿元飙升至2024年的2207.85亿元,预计2025年将突破5347.9亿元大关。这一增长背后,是终端设备从"被动执行"向"主动智能"的深刻转型。
与此同时,本地AI部署技术在2025年取得显著突破。模型量化技术的成熟使INT4/INT8低精度推理成为主流,专用AI加速芯片(NPU/TPU)的普及降低了硬件门槛,而优化框架的持续演进大幅提升了本地推理性能。51CTO在《2025年的五大AI趋势》中指出,"AI驱动的智能手机和笔记本电脑将变得更加强大,减少对持续云访问的需求",这一趋势正推动计算范式从云端集中式向边缘分布式转变。
核心亮点:LFM2-2.6B的四大突破性创新
1. 混合架构设计:卷积与注意力机制的黄金配比
LFM2-2.6B采用创新性的混合Liquid架构,融合了22层卷积块与8层注意力机制,在保持轻量化的同时实现了性能突破。
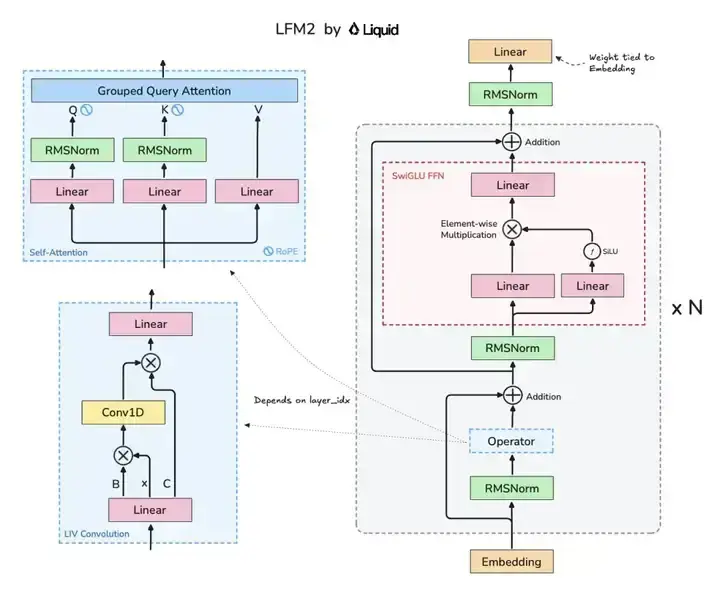
如上图所示,该架构图清晰展示了LFM2模型的核心组件布局,包括Grouped Query Attention(分组查询注意力)、LIV卷积模块的协同设计。这种混合架构是实现小模型高性能的关键,为开发者理解高效模型设计提供了直观参考。
2. 极致性能优化:速度与效率的双重突破
LFM2-2.6B实现了3倍于上一代模型的训练速度,以及2倍于Qwen3的CPU解码速度。在三星Galaxy S24 Ultra上,其解码速度达18.7 tokens/s,较同类模型Qwen3-4B提升207%,同时内存占用降低38%。这种性能优势使低端硬件也能流畅运行复杂AI任务,为边缘设备智能化铺平了道路。
3. 多硬件兼容:从手机到汽车的全场景覆盖
模型针对CPU、GPU和NPU硬件进行了深度优化,可灵活部署于智能手机、笔记本电脑和车载系统等多种设备。仅需25.7亿参数即可实现高性能推理,配合INT4量化技术,可在内存受限的嵌入式设备上高效运行。某ODM厂商测算显示,搭载该模型的智能手表可节省90%的云端交互流量,续航延长18小时。
4. 动态混合推理:复杂任务处理的创新方案
作为该系列中唯一采用动态混合推理的模型,LFM2-2.6B通过</think>和</think>标记之间的追踪实现复杂或多语言提示的高效处理。这一特性使其在跨语言对话和复杂逻辑推理任务中表现出色,支持英、中、日等8种语言,在MMMLU多语言基准中以55.39分领先。
性能评测:小参数大能力的实证
在基准测试中,LFM2-2.6B展现出超越同规模竞争者的实力:
- 知识与指令跟随:MMLU得分64.42,IFEval79.56,Multi-IF22.19
- 数学能力:GSM8K82.41,MGSM74.32
- 多语言处理:MMMLU55.39
整体而言,其输出质量媲美3-4B稠密模型,在多轮对话、创意写作、RAG检索增强生成和工具调用等任务中表现出色。
行业影响与趋势:开启边缘智能新纪元
消费电子:千元设备的AI革命
LFM2-2.6B使2GB内存设备具备流畅的大模型能力,推动AI功能向中低端消费电子渗透。IDC预计,2025年中国AI PC、AI平板和AI手机总计出货量将同比增长20%,其中AI个人电脑的渗透率将从2024年的18%迅速攀升至35%。
工业互联网:实时决策的范式转移
在智能制造质检场景,LFM2实现本地99.7%的缺陷识别率,响应延迟从云端方案的3.2秒压缩至180ms,每年可为企业节省数据传输成本约45万美元/条产线。腾讯云《大模型部署全场景实践》报告显示,2025年工业边缘设备AI赋能比例已从12%提升至43%,LFM2等轻量级模型是重要推动力。
隐私计算:数据安全的新范式
通过终端侧部署,LFM2可在不上传原始数据的情况下完成病历分析、金融风控等敏感任务。某三甲医院试点表明,其临床术语提取准确率达87.6%且满足HIPAA合规要求,数据泄露风险降至零。
总结与建议:边缘AI时代的战略布局
LFM2-2.6B代表了大模型技术的一个重要方向——在保持性能的同时实现极致压缩。对于企业而言,现在是布局边缘AI的关键时刻:
- 优先考虑本地化部署:利用LFM2-2.6B等轻量化模型,降低对云端服务的依赖,提升数据安全性与系统响应速度。
- 关注硬件-软件协同优化:通过模型量化与专用AI芯片的协同设计,实现性能与效率的平衡。
- 探索垂直领域微调和应用:特别适合在狭窄应用场景下进行微调,重点关注agentic任务、数据提取和RAG等落地场景。
如需开始使用LFM2-2.6B,可通过以下命令从GitCode仓库获取模型:
git clone https://gitcode.com/hf_mirrors/LiquidAI/LFM2-2.6B
随着LocalAI等开源生态的成熟,本地化部署门槛将持续降低。LFM2-2.6B的出现,标志着边缘AI从概念走向实用的关键转折点。在这个数据隐私日益重要、终端设备算力持续增强的时代,轻量化、高性能的边缘AI模型将成为智能终端的核心竞争力。
【免费下载链接】LFM2-2.6B 项目地址: https://ai.gitcode.com/hf_mirrors/LiquidAI/LFM2-2.6B
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







