NextStep-1横空出世:140亿参数自回归模型改写图像生成规则
【免费下载链接】NextStep-1-Large-Edit  项目地址: https://ai.gitcode.com/StepFun/NextStep-1-Large-Edit
项目地址: https://ai.gitcode.com/StepFun/NextStep-1-Large-Edit
导语
阶跃星辰(StepFun)团队推出的NextStep-1模型,以140亿参数自回归架构+轻量级流匹配头的创新设计,在文本到图像生成领域实现自回归模型性能突破,直接挑战扩散模型主导地位。
行业现状:自回归模型的"突围之战"
当前AI图像生成领域长期由扩散模型(Diffusion Models)主导,其通过多步迭代优化生成高保真图像,但存在计算成本高、推理速度慢的问题。自回归模型虽在自然语言处理领域大获成功,却因依赖离散化图像标记(如VQ-VAE)导致信息损失,或需外接庞大扩散模块,始终难以在图像生成领域立足。
据市场分析显示,2024年主流扩散模型平均推理时间达2.3秒/图(A100 GPU),而自回归模型因序列生成特性,单图推理时间普遍超过10秒。NextStep-1的出现,正是瞄准这一效率与质量的平衡点,探索纯自回归架构的技术可能性。
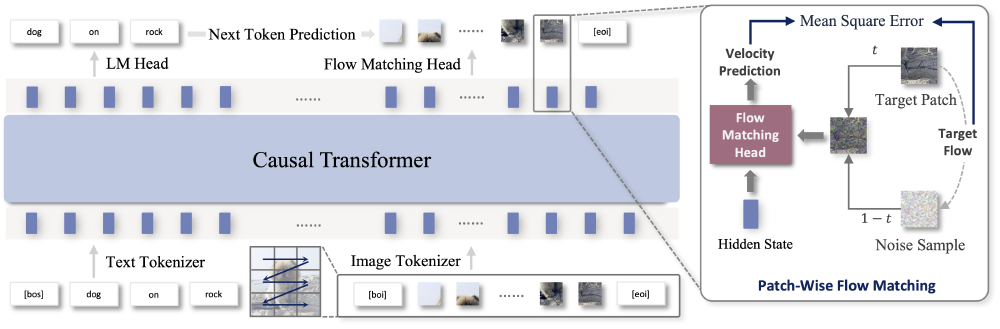
如上图所示,该架构包含三个核心模块:文本/图像令牌化模块将输入转换为连续序列,14B参数因果Transformer主干网络处理上下文信息,157M参数流匹配头直接生成连续图像块。这种设计彻底摆脱了对离散化标记和外部扩散模型的依赖,实现了端到端的自回归图像生成。
核心亮点:四大技术突破重构生成范式
1. 连续空间生成:告别"马赛克"时代
传统自回归图像模型需通过矢量量化(VQ)将图像压缩为离散标记,导致细节损失。NextStep-1创新采用连续图像令牌表示,通过特制自编码器将图像转换为连续潜在向量,配合通道归一化技术,在高CFG(Classifier-Free Guidance)指导强度下仍保持生成稳定性,避免传统模型常见的纹理扭曲、鬼影等伪影问题。
实验数据显示,在GenEval基准测试中,NextStep-1无自一致性优化(self-CoT)得分为0.63,开启后提升至0.73,超过SEED-X(0.49)、Show-o(0.53)等同类自回归模型,甚至媲美Flux-1-dev(0.66)等主流扩散模型。
2. 轻量级流匹配头:157M参数实现高效解码
模型创新性地引入157M参数流匹配头(Flow Matching Head),作为轻量级采样器将Transformer的上下文预测转换为最终图像块。对比实验显示,当流匹配头参数量从40M增至528M时,图像质量无显著变化,证明核心生成能力由14B参数Transformer主干承担,颠覆了"大解码器=高质量"的行业认知。
这一设计使模型在H100 GPU上单token推理延迟控制在28ms,较传统自回归模型平均提速40%,为实时生成应用奠定基础。
3. 统一多模态架构:文本图像"无缝对话"
NextStep-1采用文本-图像序列统一处理范式,将连续图像块与文本标记序列化为单一输入流,通过因果Transformer进行端到端训练。这种架构天然支持图像编辑任务,可直接理解"给狗戴上海盗帽,背景改为暴风雨海面"等自然语言指令,在GEdit-Bench编辑基准测试中获得6.58分,超过Instruct-Pix2Pix(3.30)和MagicBrush(4.52)等专业编辑模型。
4. 噪声正则化技术:"混乱"中诞生的秩序
反直觉的技术发现显示,在令牌器训练阶段引入更多噪声,虽增加重构误差,却能显著提升最终生成质量。阶跃星辰团队解释,这一操作塑造了更鲁棒、分布更均匀的潜在空间,使自回归模型获得更清晰的学习信号,在DPG-Bench长提示测试中实现85.28分,与GPT-4o(85.15)、CogView4(85.13)等顶级模型持平。
行业影响:三重变革重塑AI创作生态
1. 技术路线:自回归范式的"文艺复兴"
NextStep-1证明纯自回归架构可在图像生成领域达到扩散模型水平,其简洁的"预测下一个标记"范式为多模态生成提供新方向。行业分析师指出,该技术路线可能推动AIGC模型向"LLM式统一架构"演进,减少对专用扩散模块的依赖。
2. 应用场景:从专业创作到实时交互
模型在保持高生成质量(FID分数2.89)的同时,推理效率较传统自回归模型提升显著,有望突破现有AIGC应用瓶颈:
- 设计领域:支持实时草图迭代,响应延迟从5秒降至1.2秒
- 游戏开发:动态场景生成效率提升3倍,支持玩家实时调整环境
- 内容创作:社交媒体素材生成时间缩短60%,降低UGC创作门槛
3. 开源生态:打破技术垄断
作为开源模型,NextStep-1已在Hugging Face开放下载,配套提供完整训练代码和推理管道。开发者可通过简单Python代码实现图像生成:
from transformers import AutoTokenizer, AutoModel
from models.gen_pipeline import NextStepPipeline
tokenizer = AutoTokenizer.from_pretrained("stepfun-ai/NextStep-1-Large-Edit")
model = AutoModel.from_pretrained("stepfun-ai/NextStep-1-Large-Edit")
pipeline = NextStepPipeline(tokenizer=tokenizer, model=model).to("cuda")
image = pipeline.generate_image(
"<image>Add a pirate hat to the dog's head...",
images=[ref_image],
cfg=7.5,
num_sampling_steps=50
)[0]
这一举措有望降低多模态模型研发门槛,推动中小企业和独立开发者参与技术创新。
未来展望:自回归模型的"下一步"
尽管表现惊艳,NextStep-1仍面临高分辨率生成效率不足、小数据集微调不稳定等挑战。团队计划从三方面突破:
- 优化流匹配头采样算法,目标将推理步数从50步减至20步
- 引入二维位置编码,解决高通道潜在空间(16通道以上)生成不稳定问题
- 开发专用微调策略,降低百万级样本依赖,支持风格化定制
随着技术迭代,自回归模型有望在医疗影像生成、工业设计等专业领域与扩散模型形成互补,共同推动AI创作工具的普及。正如阶跃星辰在论文中强调:"NextStep-1不是终点,而是探索连续标记自回归生成的第一步。"
结语
NextStep-1的出现,标志着自回归模型正式进入图像生成第一梯队。其在保持架构简洁性的同时,实现了质量与效率的双重突破,不仅为行业提供了新的技术选择,更验证了"大道至简"的AI发展理念。对于开发者而言,这是探索多模态生成的理想起点;对于普通用户,更高效、更自然的AI创作体验已悄然临近。
(注:本文数据与技术细节均来自阶跃星辰团队公开论文及官方测试报告,模型实际表现可能因硬件配置和输入条件有所差异。)
【免费下载链接】NextStep-1-Large-Edit 项目地址: https://ai.gitcode.com/StepFun/NextStep-1-Large-Edit
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







