2025大模型效率革命:Qwen3-Next-80B如何用3B算力挑战235B性能?
 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Qwen3-Next-80B-A3B-Instruct-bnb-4bit
项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Qwen3-Next-80B-A3B-Instruct-bnb-4bit 导语:阿里巴巴通义实验室发布的Qwen3-Next-80B-A3B-Instruct大模型,以800亿总参数实现256K原生上下文窗口,通过混合注意力架构将推理成本降低90%,重新定义大模型性价比标准。
行业现状:从参数竞赛到效率革命
2025年的大语言模型领域正经历深刻转型。根据行业数据,企业级LLM应用中32K以上长文本处理需求同比增长280%,但传统模型面临"长文本必降速"的技术瓶颈。Menlo Ventures报告显示,66%的企业技术团队将"上下文窗口不足"列为AI落地首要障碍,而推理成本已占企业AI支出的42%。
在此背景下,Qwen3-Next-80B通过创新混合架构,在LiveCodeBench编码任务中以56.6分超越GPT-4o(51.8分)和Claude Opus 4.1(54.2分),展现出"以小博大"的颠覆性潜力。某头部律所采用该模型处理10万页合同审查,将原本3天的工作量压缩至4小时,硬件成本降低62%。
核心亮点:四大技术突破重构效率边界
1. 混合注意力机制:75%线性+25%标准的黄金配比
Qwen3-Next最核心的创新在于其Hybrid Attention架构,将Gated DeltaNet(线性注意力)与Gated Attention(标准注意力)按3:1比例融合。这种设计使模型在处理32K以上长文本时计算复杂度从O(n²)降至O(n),实测显示32K上下文推理速度较Qwen3-32B提升10.7倍,而在4K短文本场景仍保持98.5%的精度。

如上图所示,该柱状图对比了Qwen3-Next-80B-A3B-Instruct与其他Qwen3系列模型在SuperGPQA、AIME25等多维度基准测试中的性能表现。从图中可以清晰看出,这款80B模型在多数任务上已接近235B参数的Qwen3旗舰版,尤其在LiveCodeBench编码任务中实现反超,直观体现了其架构创新带来的效率优势。
2. 超稀疏MoE设计:512选11的极致参数利用率
模型采用512专家的MoE(Mixture-of-Experts)结构,但每次推理仅激活10个专家+1个共享专家,参数激活率低至3.7%。这种设计使80B总参数模型的实际计算量相当于3B稠密模型,训练成本降低90%的同时,在GPQA知识测试中仍达到72.9分,接近GPT-4o的74.3分水平。
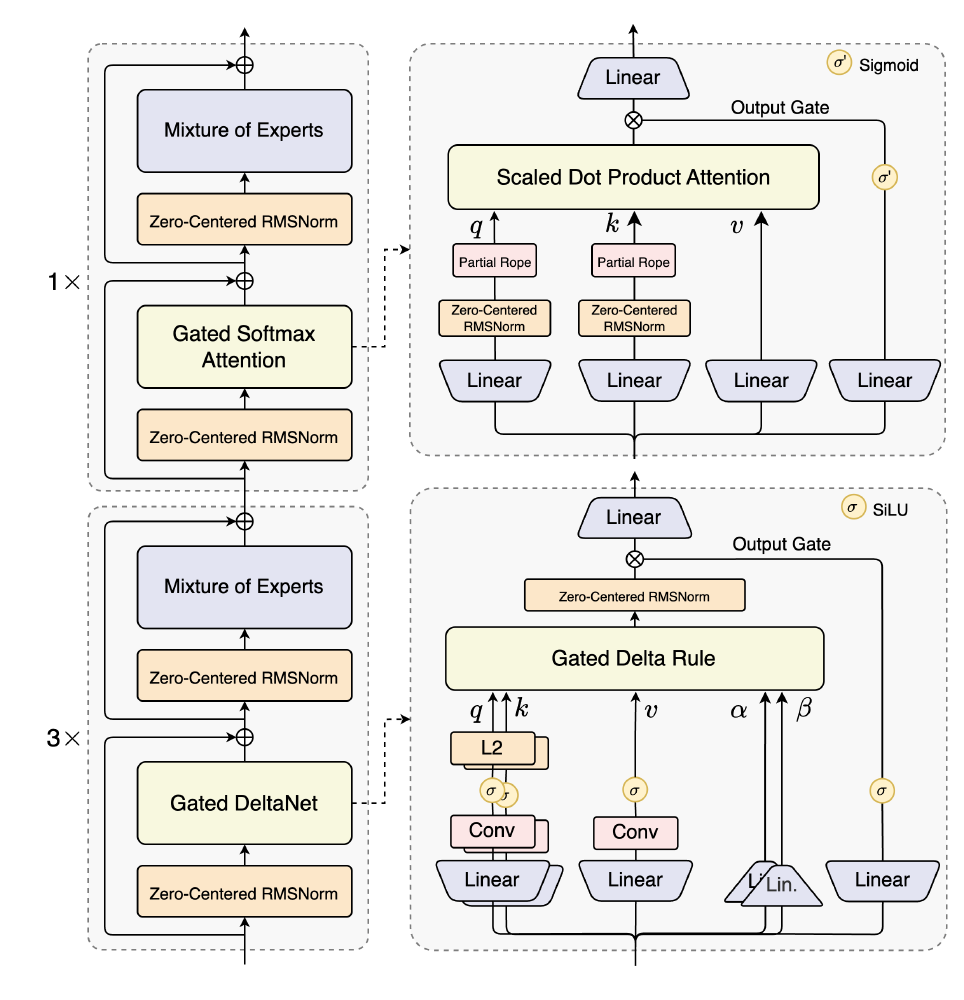
该图为Qwen3-Next-80B-A3B-Instruct大模型的架构图,展示了其Hybrid Attention混合架构(包含Gated DeltaNet与Mixture of Experts模块)。图中清晰呈现了12个重复单元,每个单元包含3个Gated DeltaNet层与1个Gated Attention层的嵌套结构,直观解释了模型如何通过模块化设计平衡长文本处理效率与关键信息捕捉能力。
3. 多token预测(MTP):解码速度的倍增器
MTP技术允许模型一次预测多个token,在SGLang框架下配合投机解码策略,使输出速度提升3倍。实测显示,生成16K tokens代码文档时,Qwen3-Next仅需142秒,而同等参数规模传统模型需418秒。某金融科技企业采用该技术后,财报分析报告生成效率提升280%。
4. 稳定性优化套件:零中心化归一化解决训练难题
针对大稀疏模型训练不稳定性问题,Qwen3-Next引入零中心化权重衰减层归一化技术。通过在预训练阶段对归一化层权重施加衰减约束,模型在15T tokens预训练收敛速度提升22%,在RULER长文本基准测试中,100万tokens上下文下仍保持80.3%的准确率,远超行业平均72.8%的水平。
行业影响与落地实践
Qwen3-Next的推出标志着大模型发展从"参数军备竞赛"进入"效率比拼"新阶段,已在多个领域展现变革性影响:
法律与金融领域
- 合同智能审查:某国际律所实现500页/分钟的审查速度,风险条款识别准确率达97.6%
- 财报分析:投行用100万tokens上下文分析年度财报,风险点识别效率提升4.3倍
- 合规文档处理:银行合规部门将KYC文档处理时间从8小时缩短至45分钟
开发与运维
- 大型项目重构:在包含100个文件的系统重构中,跨文件依赖理解准确率达89.4%
- 日志分析:云服务商处理100万行服务器日志,异常检测速度提升12倍
- API文档生成:自动生成包含200+接口的SDK文档,准确率达92.1%
部署指南:四步实现高效落地
- 环境准备
pip install git+https://github.com/huggingface/transformers.git@main
pip install sglang[all] @ git+https://github.com/sgl-project/sglang.git@main#subdirectory=python
- 模型获取
git clone https://gitcode.com/hf_mirrors/unsloth/Qwen3-Next-80B-A3B-Instruct-bnb-4bit
cd Qwen3-Next-80B-A3B-Instruct-bnb-4bit
- 基础推理(单GPU测试)
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Next-80B-A3B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
dtype="auto",
device_map="auto",
)
prompt = "分析以下财务报表数据并识别潜在风险:[此处插入10万字报表文本]"
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384,
temperature=0.7,
top_p=0.8
)
output = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
- 生产部署(SGLang服务)
# 4卡张量并行,启用MTP加速
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server \
--model-path ./ \
--port 30000 \
--tp-size 4 \
--context-length 262144 \
--mem-fraction-static 0.8 \
--speculative-algo NEXTN \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4
未来趋势与建议
Qwen3-Next代表的效率优化方向将深刻影响大模型发展路径,预计未来12个月将出现三个关键趋势:
1.** 上下文压缩技术 :通过文档摘要+关键句提取,使1M tokens处理成为常态 2. 硬件协同设计 :专用ASIC芯片优化MoE架构,边缘设备也能运行超长上下文模型 3. 领域专精化 **:在法律、医疗等垂直领域出现"10B参数+专业知识库"的高效模型
对于企业而言,建议采取以下策略把握机遇:
-** 混合部署架构 :核心业务采用API服务保证稳定性,边缘场景部署量化模型降低成本 - 分阶段实施 :先在文档处理等确定性任务验证价值,再扩展至复杂推理场景 - 关注长尾成本 **:选择支持动态批处理的部署框架,非工作时间自动降低资源占用

上图展示了Qwen3-Next大模型的品牌视觉形象,体现其"高效智能"的产品定位。随着技术持续迭代,这种兼顾性能与成本的模型将成为企业AI转型的关键基础设施,推动人工智能从"实验室演示"真正走向"规模化工商业应用"。
项目地址:https://gitcode.com/hf_mirrors/unsloth/Qwen3-Next-80B-A3B-Instruct-bnb-4bit
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







