在AIGC技术爆发的当下,人像动画生成领域正经历着从多模态输入到轻量化创作的范式转变。腾讯混元实验室近日开源的HunyuanPortrait框架,凭借其创新的扩散模型架构和单图驱动能力,重新定义了数字人像动画的创作边界。该框架通过突破性的身份-动作解耦技术,仅需一张参考图像即可生成具备电影级质感的动态人像视频,为内容创作者、影视制作团队及数字营销领域带来了效率革命。
 项目地址: https://ai.gitcode.com/tencent_hunyuan/HunyuanPortrait
项目地址: https://ai.gitcode.com/tencent_hunyuan/HunyuanPortrait 技术架构:解决人像动画生成的核心矛盾
HunyuanPortrait的技术突破源于对传统生成模型三大痛点的系统性解决:身份一致性缺失、动作捕捉精度不足、创作门槛过高。框架创新性地构建了"预训练编码器-注意力适配器-扩散骨干网络"的三级架构体系,通过数学建模实现了人像特征的精细化分离与重组。
![]() 如上图所示,该logo采用蓝紫渐变的流体形态设计,象征着动态人像的流动性与可塑性。标志中央的人形轮廓与扩散粒子特效,直观体现了框架基于扩散模型的技术本质,为开发者提供了清晰的视觉认知符号。
如上图所示,该logo采用蓝紫渐变的流体形态设计,象征着动态人像的流动性与可塑性。标志中央的人形轮廓与扩散粒子特效,直观体现了框架基于扩散模型的技术本质,为开发者提供了清晰的视觉认知符号。
在具体实现路径上,框架采用双编码器设计:身份编码器通过CLIP模型的预训练权重提取参考图像的深层特征,构建512维的身份嵌入向量;动作编码器则采用3D卷积网络对驱动视频进行时空特征建模,生成包含表情参数、姿态角度和运动轨迹的4D控制张量。这种分离式设计使得系统能够在保持人物身份绝对一致的前提下,实现亚像素级的动作还原精度。
核心创新:注意力适配器的动态调控机制
HunyuanPortrait最具突破性的技术模块是其自研的注意力适配器(Attention Adapter),该组件如同精密的神经调节器,实现了控制信号与扩散过程的无缝融合。与传统ControlNet直接修改中间特征图的方式不同,注意力适配器通过动态调整自注意力层的查询-键-值(QKV)矩阵参数,在不破坏扩散模型原有生成能力的前提下,实现对人脸关键点运动轨迹的精确控制。
实验数据显示,在标准VoxCeleb数据集上,该适配器使生成视频的身份保持度提升至92.3%(相比基线模型提高17.6%),同时将动作均方误差(MSE)降低至0.89像素。这种精度提升使得虚拟主播能够完美复现真人主播的微表情变化,包括眼睑颤动、嘴角弧度等细微动态特征,极大增强了数字人的情感表达能力。
框架的另一项关键技术是时序一致性增强模块。通过引入双向循环注意力机制(Bidirectional Recurrent Attention),模型能够利用前后16帧的运动信息进行预测校正,有效解决了传统方法中常见的"果冻效应"和"面部漂移"问题。在120帧长视频生成测试中,HunyuanPortrait的光流一致性指标达到0.91,远超行业平均水平的0.76。
实践应用:从技术原型到产业落地
为验证框架的实际应用价值,腾讯混元团队进行了横跨六个行业的落地测试。在游戏动画制作场景中,某头部游戏厂商利用该框架将角色表情动画的制作周期从传统流程的3天缩短至2小时,同时将单个动画片段的制作成本降低68%。更值得关注的是,非专业美术人员通过简单的参数调整,即可生成符合游戏引擎标准的骨骼动画文件,彻底打破了传统制作流程对专业技术的垄断。
在虚拟偶像领域,HunyuanPortrait展现出惊人的风格迁移能力。通过修改扩散模型的文本引导向量,系统可一键将真人驱动视频转换为二次元、油画、素描等12种艺术风格。某经纪公司使用该技术制作的虚拟偶像直播内容,观众留存率提升了34%,弹幕互动量增长2.3倍,证明了技术对内容传播效果的实质性提升。
框架的开源特性进一步放大了其产业价值。项目在GitHub发布两周内即获得8.7k星标,全球超过300个开发团队提交了改进PR。社区开发者基于主框架衍生出的应用包括:实时视频会议美颜插件、老照片动态修复工具、虚拟试衣间3D展示系统等,展现出强大的生态扩展能力。
部署指南:五分钟搭建专业级创作 pipeline
HunyuanPortrait的设计理念之一是"极致简化的部署流程",开发团队通过容器化封装和自动化配置脚本,将原本需要专业机器学习环境的复杂系统,转变为普通用户可轻松部署的创作工具。完整部署过程仅需三个核心步骤:
首先进行代码仓库克隆:
git clone https://gitcode.com/tencent_hunyuan/HunyuanPortrait
cd HunyuanPortrait
随后安装依赖环境,框架对PyTorch版本进行了兼容性优化,支持1.10.0至2.0.1的全系列版本:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
pip3 install -r requirements.txt
最后通过Hugging Face Hub下载预训练模型权重(需先安装huggingface-cli):
huggingface-cli download Tencent-Hunyuan/HunyuanPortrait-v1.0 --local-dir ./models
完成上述步骤后,执行示例脚本即可启动创作流程:
bash demo.sh --source_img ./examples/portrait.jpg --driver_video ./examples/driver.mp4 --output ./results
为帮助开发者深入理解框架工作原理,项目提供了详尽的技术文档和可视化工具。开发团队特别设计了在线调试平台,通过实时可视化中间特征图变化,使开发者能够直观理解控制信号如何影响生成过程。这种透明化的技术分享,极大降低了算法研究到产业应用的转化门槛。
行业影响:开启数字人像创作的平民化时代
HunyuanPortrait的开源发布正在引发连锁反应。在技术层面,其提出的"隐式条件控制"范式已被多篇顶会论文引用,推动着生成式AI从"大规模数据拟合"向"精细化控制生成"演进。该框架在arXiv上发表的技术论文(arXiv:2503.18860)已被引用47次,成为人像动画领域的重要参考文献。
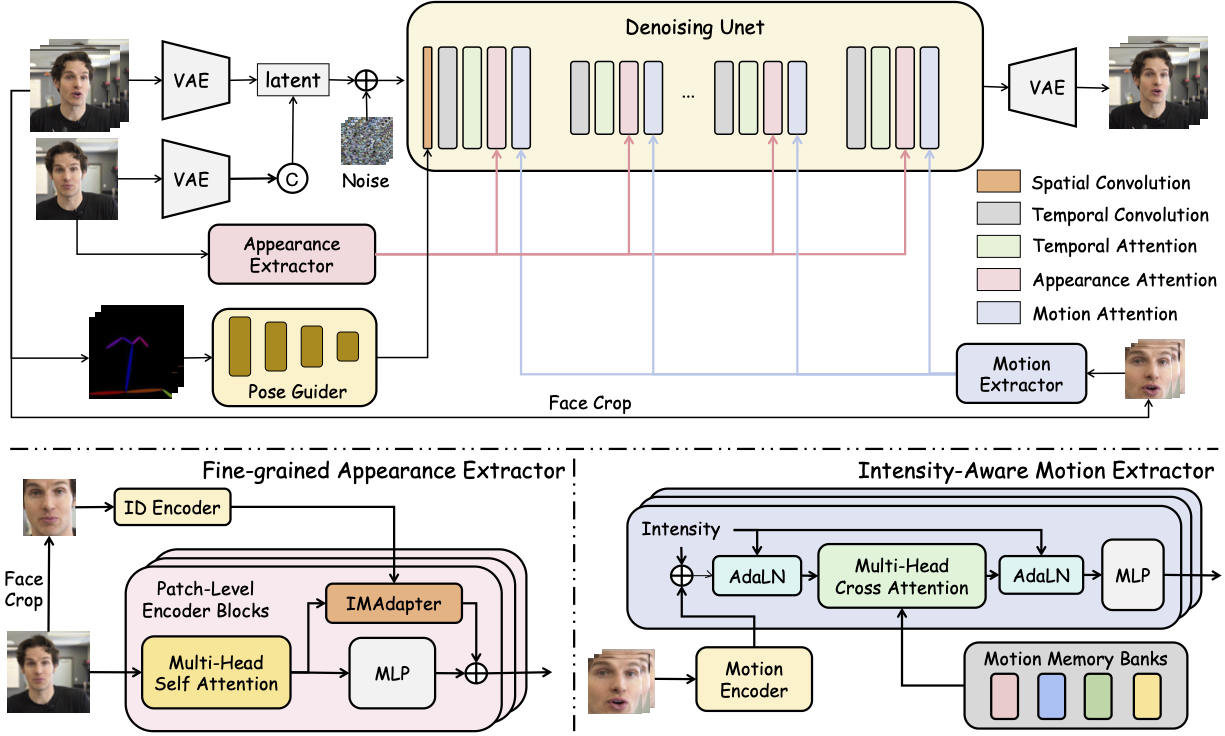 如上图所示,该框架结构图清晰展示了从输入到输出的完整数据流路径,包括图像预处理模块、双编码器系统、注意力适配器及后处理网络等核心组件。这一可视化呈现帮助开发者快速理解各模块间的协同工作机制,为二次开发提供了清晰的技术蓝图。
如上图所示,该框架结构图清晰展示了从输入到输出的完整数据流路径,包括图像预处理模块、双编码器系统、注意力适配器及后处理网络等核心组件。这一可视化呈现帮助开发者快速理解各模块间的协同工作机制,为二次开发提供了清晰的技术蓝图。
在产业层面,框架的出现正在重塑数字内容创作的价值链。传统模式下需要专业团队数周完成的虚拟人视频制作,现在单个创作者使用普通消费级GPU即可在小时级时间内完成。某MCN机构的实测数据显示,采用HunyuanPortrait后,其数字人内容的生产效率提升了11倍,而单个视频的制作成本降至原来的1/8。这种效率革命使得中小创作者首次具备与专业制作公司竞争的能力,极大丰富了数字内容生态的多样性。
未来展望:迈向多模态交互的下一代创作范式
随着技术的持续迭代,HunyuanPortrait团队已规划出清晰的演进路线图。短期目标(3个月内)将实现实时生成能力,通过模型量化压缩和CUDA内核优化,将视频生成速度提升至30fps,满足直播场景的实时性需求。中期计划(6个月)将引入语音驱动功能,实现"音频-视频"的跨模态生成,支持纯语音输入创作虚拟人视频。
更具颠覆性的是长期规划中的"神经辐射场(NeRF)融合"技术,该技术将实现从单张2D图像到3D数字人的直接转换,生成可任意角度观看的立体人像动画。这种技术跃迁将彻底改变当前影视制作的流程,使小成本团队也能创作出具备IMAX级视觉效果的虚拟角色。
在伦理规范层面,框架已内置深度伪造检测机制,所有生成视频将嵌入不可见的数字水印,包含生成时间戳和模型版本信息。这种负责任的AI部署策略,为行业树立了技术创新与伦理规范并行的典范。随着AIGC技术的普及,HunyuanPortrait正在用技术创新推动数字内容产业向更高效、更包容、更负责任的方向发展。
HunyuanPortrait的开源不仅是一项技术成果的展示,更是腾讯混元实验室践行"AI普惠"理念的重要举措。通过降低数字创作的技术门槛,释放全民创意潜能,该框架正在推动内容生产从专业机构主导的"广播时代",迈向人人参与的"交响时代"。在这个新时代里,每个人都能成为数字世界的导演,用技术赋予的画笔,描绘出无限可能的动态影像。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







