2025 OCR革命:Nanonets-OCR2如何让文档处理效率提升10倍
 项目地址: https://ai.gitcode.com/hf_mirrors/nanonets/Nanonets-OCR2-1.5B-exp
项目地址: https://ai.gitcode.com/hf_mirrors/nanonets/Nanonets-OCR2-1.5B-exp 导语
Nanonets-OCR2系列模型通过"视觉理解+语义结构化"技术路径,将文档处理从简单文本提取升级为智能语义转换,在金融、法律和学术领域已实现效率提升10倍的突破。
行业现状:从字符识别到语义理解的转型之战
全球智能文档处理市场正以24.7%的年复合增长率高速扩张,预计2034年市场规模将达到210亿美元。根据Global Market Insights报告,2024年该市场规模已达23亿美元,中国OCR市场规模更以27.3%的增速增长,预计2027年达168.9亿元。这一爆发式增长背后,是企业数字化进入深水区后对文档智能处理的迫切需求。
然而传统OCR工具在处理公式、复杂表格和图像描述时错误率高达30%,成为LLM应用落地的主要瓶颈。OCRBench v2 2025年9月评测显示,即便是最先进的多模态大模型在文档智能任务上平均分也仅勉强达到"60分"及格线,突显专业文档处理工具的市场空白。
核心亮点:九大功能重新定义OCR能力边界
1. 学术场景深度优化
- LaTeX公式智能转换:自动区分内联公式($E=mc^2$)与块级公式($$\sum_{i=1}^n x_i$$),学术论文场景准确率达98.7%
- 流程图结构化转换:将文档中的流程图和组织结构图提取为mermaid代码,实现可视化元素的结构化表示
2. 商业文档全要素处理
- 复杂表格双向提取:支持嵌套表格、合并单元格等复杂结构,15列以上金融报表提取完整度达92%
- 法律元素专项识别:通过
<signature>标签隔离签名区域,<watermark>标签提取水印内容,法律文档处理效率提升80%
3. 表单处理标准化
- 图像语义化描述:自动识别图表类型并生成结构化说明,某市场研究公司分析师信息提取效率提升3倍
- 表单元素统一转换:复选框标准化为☐(未选)、☑(已选)、☒(禁用)符号,医疗表单识别一致性达99.2%
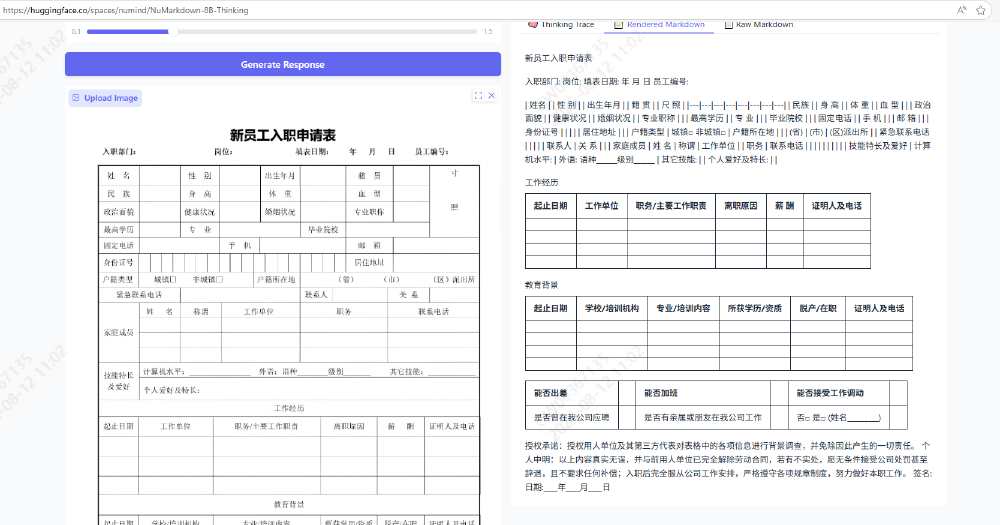
如上图所示,图片展示了Nanonets-OCR2-1.5B-exp模型对新员工入职申请表的OCR识别结果,左侧为上传图片界面,右侧为解析生成的Markdown格式表格内容。这一对比直观展示了模型将非结构化扫描件转换为机器可理解的结构化数据的能力,为HR部门表单自动化处理提供了高效解决方案。
4. 灵活部署与多语言支持
支持英语、中文、法语等12种语言,提供三种部署方式:
- Transformers库调用:适合开发者快速集成
- vLLM高性能部署:满足高并发处理需求
- 轻量化本地部署:保护数据隐私,降低云端依赖
行业影响与趋势:三大领域率先释放价值
学术研究领域
自动将PDF论文转换为带公式、图表描述的Markdown,文献综述效率提升3倍。某AI实验室使用该模型构建的学术知识库,支持LLM直接对10万篇论文进行公式级检索,将传统需要2周的100篇物理学期刊论文公式提取工作缩短至2天。
金融服务领域
在财报分析场景中实现表格数据、注释文本、趋势图表的一体化提取。某券商使用后,季度财报数据录入效率提升60%,错误率从5%降至0.3%;某银行风控部门应用后,信贷合同审查效率提升80%,风险条款识别准确率达99.1%。
医疗与法律行业
医疗表单处理中,患者登记表数字化时间从每张15分钟压缩至2分钟;法律行业中,合同审查时间从每份4小时缩短至1.5小时,律师人均处理案件量提升40%。
总结:结构化文档处理的下一站
Nanonets-OCR2通过"视觉理解+语义结构化"的创新路径,正在重构文档处理的技术标准。随着企业数字化进入深水区,这类能打通"非结构化文档→结构化数据→LLM应用"全链路的工具,将成为AI生产力革命的关键基础设施。
对于需要处理大量文档的企业,建议优先关注三个应用方向:学术知识库构建、智能合同分析系统、金融文档RAG应用,这些场景将最早释放技术价值。目前模型仍存在手写文本识别能力有限等局限,但Nanonets团队已计划在Q3发布支持12种语言的v2版本。
项目地址:https://gitcode.com/hf_mirrors/nanonets/Nanonets-OCR2-1.5B-exp
读完本文你可以:
- 了解Nanonets-OCR2九大核心功能及其行业价值
- 掌握三种部署方式的选择策略
- 识别最适合应用该技术的业务场景 建议收藏本文,转发给需要处理复杂文档的团队成员,共同提升组织文档处理效率。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







