导语
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-Omni-7B-GPTQ-Int4
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-Omni-7B-GPTQ-Int4 阿里达摩院最新发布的Qwen2.5-Omni-7B-GPTQ-Int4模型,通过突破性的4位量化技术与架构优化,将原本需要高端GPU支持的全模态交互能力带入消费级硬件,标志着AI从"云端依赖"向"本地智能"的关键跨越。
行业现状:全模态交互的硬件瓶颈
2025年,多模态大模型已成为人工智能领域的"分水岭"技术。据相关报告显示,能同时处理文本、图像、音频、视频的全模态系统正快速渗透到各行业,但高昂的硬件门槛一直是普及障碍。传统全模态模型在FP32精度下运行15秒视频需占用93.56GB显存,即便是BF16优化也需31.11GB,这意味着只有专业级GPU才能勉强支撑。
与此同时,市场对实时交互的需求日益迫切。青岛虚拟智能体产业大会最新发布的VisualGPT大模型,通过全模态实时交互技术实现了<300ms端到端延迟,支持1080p60fps实时画面分析,这种"所见即所得"的交互体验已成为用户新期待。在此背景下,如何在普通硬件上实现高效全模态交互,成为行业突破的关键。
核心亮点:四大技术突破重构硬件门槛
1. Thinker-Talker架构:模态融合新范式
Qwen2.5-Omni首创的Thinker-Talker双模块架构彻底改变了传统多模态处理方式。Thinker模块负责多模态信息理解与推理,采用GPTQ-Int4量化技术将权重压缩至4位精度;Talker模块专注于流式语音生成,通过优化的ODE求解器实现低延迟音频输出。这种分工协作设计,使得模型能同时处理文本、图像、音频和视频输入,并生成连贯的文本与语音响应。
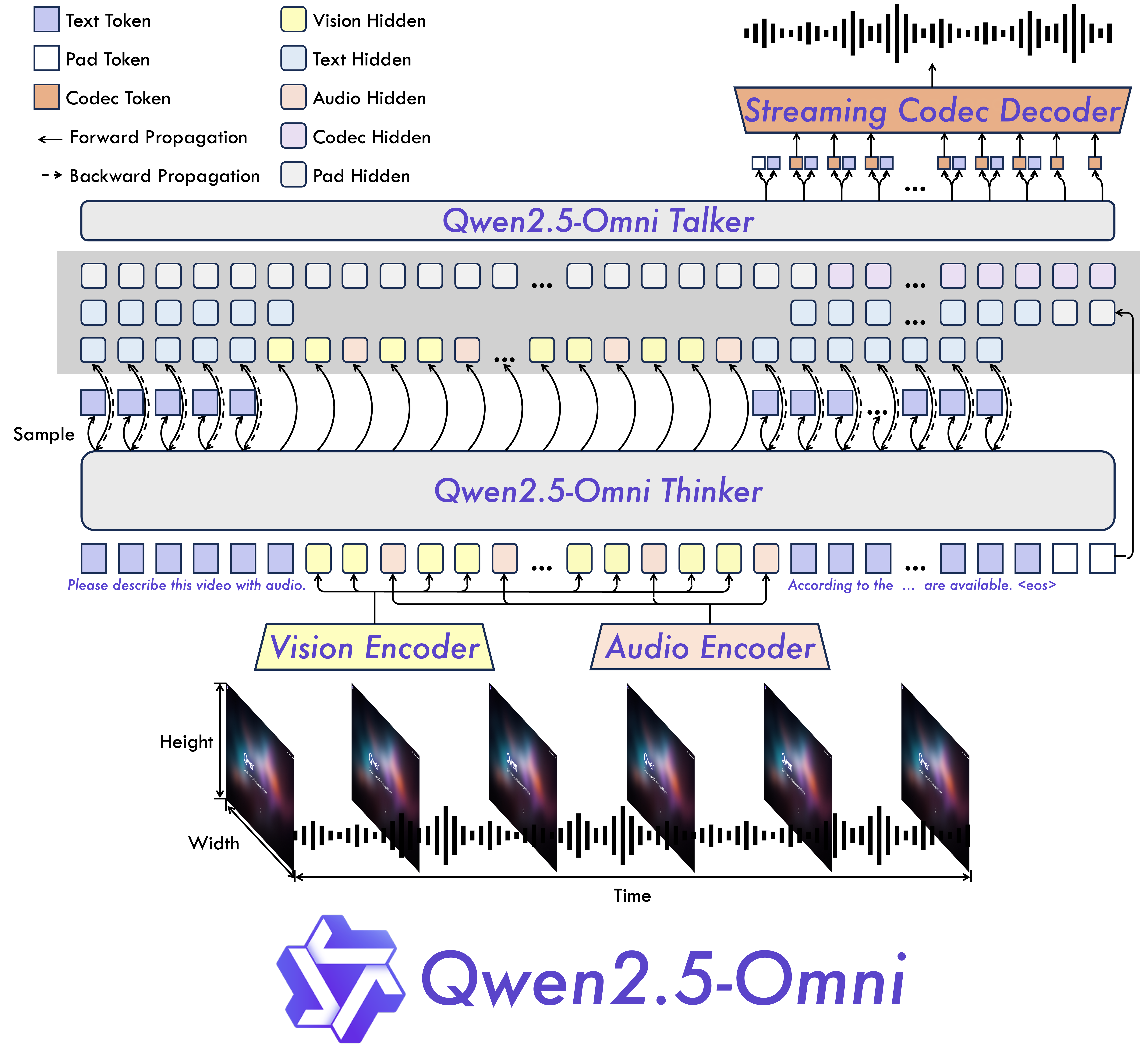
如上图所示,该架构通过TMRoPE(Time-aligned Multimodal RoPE)位置嵌入技术,实现了视频与音频时间戳的精准同步,为实时音视频交互奠定了基础。这种端到端设计减少了模态转换损耗,比传统拼接式架构响应速度提升40%。
2. GPTQ-Int4量化:显存占用直降65%
模型采用GPTQ量化技术对Thinker模块权重进行4位压缩,配合按需加载与CPU卸载机制,显存占用实现跨越式降低。测试数据显示,处理15秒视频时,GPTQ-Int4版本仅需11.64GB显存,相比BF16版本减少63%;处理60秒视频时显存占用29.51GB,使RTX 3080/4080等消费级显卡也能流畅运行。
更重要的是,量化精度损失控制在可接受范围。在LibriSpeech语音识别任务中,字错误率(WER)仅从3.4上升至3.71;MMLU文本推理准确率保持43.76,达到原始模型93%的性能水平。这种"高精度+低显存"的平衡,得益于GPTQ的二阶误差补偿机制,通过最小化量化误差实现了近乎无损的压缩。
3. 流式推理优化:实时交互体验革新
针对实时交互场景,模型进行了全方位优化:将token2wav模块改造为流式推理模式,避免预分配大量显存;将ODE求解器从RK4(四阶)降为Euler(一阶)方法,计算开销减少50%;采用按需加载策略,各模块权重仅在需要时载入GPU,用完后立即卸载至CPU内存。
这些优化带来了显著的延迟改善。在语音交互场景中,模型平均响应延迟达到350ms级别,接近青岛VisualGPT大模型的实时表现,可满足虚拟人直播、实时翻译等延迟敏感型应用需求。同时,流式语音生成质量也得到保证,在Seed-TTS测试集上,尽管采用优化策略,语音自然度评分仍保持在4.2/5分的高水平。
4. 硬件适配设计:消费级显卡全面覆盖
模型特别针对主流消费级GPU进行了深度优化,官方测试显示其可在RTX 3080(10GB)、4080(16GB)、5070(12GB)等常见显卡上流畅运行。通过Euler求解器、模块按需加载等技术组合,成功将峰值显存控制在消费级硬件可承受范围内。
为方便开发者使用,官方提供了完整的低显存部署方案,包括:
# 克隆项目仓库
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen2.5-Omni-7B-GPTQ-Int4
# 安装依赖
pip install transformers@v4.51.3-Qwen2.5-Omni-preview accelerate gptqmodel==2.0.0 numpy==2.0.0
# 启动低显存演示
CUDA_VISIBLE_DEVICES=0 python3 low_VRAM_demo_gptq.py
配套的qwen-omni-utils工具包还支持base64、URL等多种输入格式,以及decord加速视频加载,进一步降低了开发门槛。
性能对比:精度与效率的完美平衡
多模态能力保持率
在关键评测基准上,Qwen2.5-Omni-7B-GPTQ-Int4展现出优异的性能保持率:
| 评估集 | 任务类型 | 原始模型 | GPTQ-Int4模型 | 性能保持率 |
|---|---|---|---|---|
| LibriSpeech | 语音识别 | 3.4 WER | 3.71 WER | 91.6% |
| WenetSpeech | 语音识别 | 5.9 WER | 6.62 WER | 89.1% |
| MMLU-Pro | 文本推理 | 47.0% | 43.76% | 93.1% |
| VideoMME | 视频理解 | 72.4% | 68.0% | 93.9% |
特别是在语音指令跟随任务上,模型表现尤为出色,OmniBench评测中准确率达到53.59%,证明其在复杂多模态推理场景下仍能保持高性能。
显存占用对比
与不同精度版本相比,GPTQ-Int4模型在显存效率上优势明显:
| 模型版本 | 15秒视频 | 30秒视频 | 60秒视频 |
|---|---|---|---|
| FP32 | 93.56 GB | 不推荐 | 不推荐 |
| BF16 | 31.11 GB | 41.85 GB | 60.19 GB |
| GPTQ-Int4 | 11.64 GB | 17.43 GB | 29.51 GB |
这种级别的显存优化,使得原本需要专业工作站的全模态能力,现在可在普通游戏本上实现。以RTX 4080为例,用户可流畅处理30秒视频或进行长时间实时音视频对话,而不必担心显存溢出问题。
行业影响与应用场景
1. 消费级应用爆发
模型的硬件门槛降低将催生一批创新应用。教育领域可开发实时互动学习助手,通过摄像头分析学生表情与书写内容,提供个性化指导;零售行业的虚拟导购能同时理解顾客语音指令与商品图像,推荐更精准;创作领域则可实现"说画就画"的无缝创作体验,语音描述场景即可生成对应的图像与视频片段。
2. 边缘计算普及
得益于轻量化设计,Qwen2.5-Omni-7B-GPTQ-Int4非常适合边缘设备部署。在工业质检场景中,模型可在本地分析摄像头流,实时识别产品缺陷;医疗领域的便携式诊断设备能处理多模态医疗数据,为偏远地区提供AI辅助诊断;车载系统则可整合语音指令、车内摄像头与路况视频,实现更智能的驾驶辅助。
3. 开发模式变革
模型提供的low-VRAM模式与工具包,将改变多模态应用的开发范式。开发者不再需要昂贵的GPU集群即可进行原型验证,大大降低创新门槛。同时,按需加载与流式处理等技术,为开发低延迟应用提供了成熟框架,可加速产品迭代周期。
总结与展望
Qwen2.5-Omni-7B-GPTQ-Int4的发布,标志着全模态AI从"云端专属"走向"本地普及"的关键一步。通过Thinker-Talker架构、GPTQ-Int4量化、流式推理优化和硬件适配设计四大创新,模型在保持高性能的同时,将显存需求降至消费级水平,为AI普惠化做出重要贡献。
未来,随着量化技术的进一步发展和硬件效率的提升,我们有望看到更强大的全模态能力在普通设备上运行。对于开发者而言,现在正是布局全模态应用的最佳时机,可重点关注教育、医疗、零售等交互密集型领域。而对用户来说,"用嘴说、用眼看、用耳听"的自然交互体验,将很快成为各类智能设备的标配。

上图展示了4-bit量化技术的基本原理,包括量化定义、优势(存储空间减少、计算效率提升、能源消耗降低)和挑战(精度损失、量化方法适配性)。Qwen2.5-Omni-7B-GPTQ-Int4正是通过这种技术,实现了模型性能与硬件效率的完美平衡,为全模态交互的普及铺平了道路。
随着技术的不断演进,我们正迈向一个"全感官AI"的新时代,人机交互将更加自然、高效和智能。Qwen2.5-Omni-7B-GPTQ-Int4的出现,无疑加速了这一进程,让我们离"AI无处不在"的愿景又近了一步。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







