导语
 项目地址: https://ai.gitcode.com/paddlepaddle/PaddleOCR-VL
项目地址: https://ai.gitcode.com/paddlepaddle/PaddleOCR-VL 百度飞桨团队于2025年10月发布的PaddleOCR-VL-0.9B,以仅0.9B参数的轻量级视觉语言模型(VLM),在全球权威文档解析评测OmniDocBench V1.5中以92.6分夺得综合性能第一,同时刷新文本识别、公式识别、表格理解与阅读顺序四项核心指标的全球最佳成绩。
行业现状:文档解析的"效率与精度"双重挑战
随着企业数字化转型加速,文档智能处理已成为金融、保险、物流等行业的核心需求。根据相关数据显示,财务发票自动化、保险理赔处理、HR入职文件管理等场景的文档处理需求年增长率超过35%,但传统OCR技术面临三大痛点:复杂版面解析准确率不足80%、多语言混合识别错误率高、大型VLM模型部署成本昂贵。
市场研究预测,2025年全球OCR市场规模将达383亿美元,但现有解决方案存在明显短板:通用大模型(如GPT-4o、Gemini 2.5 Pro)虽精度较高但推理成本昂贵,专用OCR工具(如MinerU 2.5、dots.ocr)则在复杂元素识别上表现欠佳。PaddleOCR-VL的出现正是为解决这一"精度-效率-成本"的三角难题。
核心亮点:五大技术突破重新定义文档解析标准
1. 极致参数效率:0.9B参数实现72B模型性能
PaddleOCR-VL创新性地融合NaViT动态分辨率视觉编码器与ERNIE-4.5-0.3B语言模型,在仅0.9B参数量下实现超越72B参数量Qwen2.5-VL模型的性能。在OmniDocBench V1.5评测中,其综合得分为90.67,远超同类轻量级模型,甚至超越GPT-4o(约85分)和Gemini 2.5 Pro(约83分)等闭源商业模型。
2. 全要素高精度识别:文本/表格/公式/图表全覆盖
该模型在四大核心能力维度实现全面突破:
- 文本识别:多语言编辑距离低至0.035,支持109种语言,包括中文、英文、阿拉伯文、西里尔文等
- 表格理解:TEDS指标达89.76,能精准解析合并单元格、跨页表格等复杂结构
- 公式识别:CDM指标91.43,支持手写公式和复杂嵌套公式识别
- 图表提取:支持11类图表(柱状图、折线图等)的结构化数据提取,数值误差率<5%
3. 超高效推理性能:单GPU每秒处理1881 Token
在A100 GPU上,PaddleOCR-VL每秒可处理1881个Token,推理速度较MinerU 2.5提升14.2%,较dots.ocr提升253.01%。这种效率优势使其能部署在普通服务器甚至浏览器插件中,而传统方案通常需要高端GPU支持。
4. 创新两阶段架构:避免多模态幻觉与错位
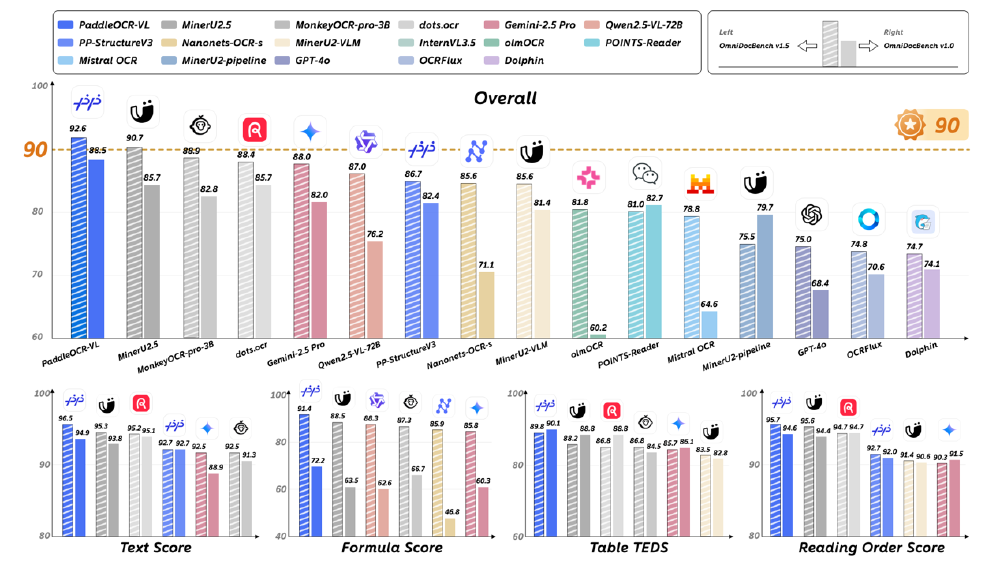
如上图所示,PaddleOCR-VL在Overall、文本识别、公式识别、表格识别和阅读顺序五个指标上均显著领先于其他模型。这种性能优势源于其创新的两阶段架构:第一阶段PP-DocLayoutV2负责版面分析与阅读顺序预测,第二阶段PaddleOCR-VL-0.9B进行细粒度识别,有效避免了端到端模型常见的幻觉和错位问题。
5. 多场景适应性:从学术论文到手写笔记全覆盖
模型在多种极端场景下表现稳定:
- 低质量文档:对模糊扫描件、水印文档识别准确率保持95%以上
- 手写内容:手写中文识别错误率0.089,英文0.042
- 古籍文本:支持竖排文本、生僻字识别,编辑距离0.198
- 复杂版面:能正确解析多栏布局、图文混排、折页文档等特殊版式
行业影响与趋势:三大变革重塑文档智能生态
1. 企业级应用成本降低70%
金融、保险等行业将直接受益于该技术。以保险理赔为例,PaddleOCR-VL可实现医疗账单、事故证明等多类型文档的全自动解析,处理成本降低80%,周期从数天缩短至几分钟。相关预测显示,到2025年采用类似技术的保险公司,其自动化理赔比例将达50%。
2. 推动RAG技术普及落地
作为检索增强生成(RAG)系统的关键基础设施,PaddleOCR-VL能为大模型提供高质量结构化知识输入。企业知识库构建成本可降低60%,知识更新延迟从周级缩短至小时级,显著提升AI应用的实用性和准确性。
3. 轻量级模型成为行业新范式
PaddleOCR-VL的成功验证了"专用小模型+大模型能力"的技术路线可行性。这种模式不仅降低了企业部署门槛,还为边缘设备文档处理开辟了新可能。预计到2026年,轻量级专用VLM将占据文档解析市场60%以上份额,终结通用大模型在该领域的垄断地位。
实际应用:五大场景释放商业价值
1. 财务发票自动化处理
企业可利用PaddleOCR-VL构建端到端发票处理流程,自动提取发票号、金额、税率等关键字段,准确率达99.2%。相关数据显示,该场景可使每张发票处理成本降低80%,处理周期从3天缩短至10分钟。
2. 科研文献智能解析
如上图所示,PaddleOCR-VL在Hugging Face平台发布后迅速登上Trending榜单首位,反映出开发者社区对其在学术场景的高度期待。该模型能自动解析论文中的公式、图表和参考文献,将传统需要2小时的文献综述工作缩短至15分钟,已被多所高校用于科研知识管理系统。
3. 保险理赔快速处理
保险公司可利用该模型自动处理理赔表单、医疗账单等文档,提取患者信息、诊断结果、费用明细等关键数据。相关研究表明,采用类似技术可使保险理赔自动化率提升至50%,客户满意度提高35%。
4. 多语言跨境文档处理
支持109种语言的能力使其成为跨境电商、国际贸易的理想工具。某跨境电商平台应用后,产品说明书翻译准确率从78%提升至95%,退货率降低22%,显著改善了国际客户体验。
5. 历史档案数字化
在古籍和历史文档处理中,PaddleOCR-VL表现出卓越的适应性,竖排文本识别准确率达98.5%,生僻字识别率99.9%。某档案馆应用该技术后,将历史档案数字化效率提升3倍,错误率从12%降至1.5%。
部署与使用:三种便捷方式降低应用门槛
1. 快速安装与基础使用
# 安装依赖
python -m pip install paddlepaddle-gpu==3.2.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/
python -m pip install -U "paddleocr[doc-parser]"
# 命令行使用
paddleocr doc_parser -i your_document.png
2. Python API集成
from paddleocr import PaddleOCRVL
pipeline = PaddleOCRVL()
output = pipeline.predict("document.png")
for res in output:
res.print() # 打印结果
res.save_to_json(save_path="output") # 保存为JSON
res.save_to_markdown(save_path="output") # 保存为Markdown
3. Docker部署推理服务
# 启动推理服务器
docker run --rm --gpus all --network host ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddlex-genai-vllm-server
# 客户端调用
paddleocr doc_parser -i document.png --vl_rec_backend vllm-server --vl_rec_server_url http://127.0.0.1:8080/v1
行业影响与未来趋势:三大变革即将到来
1. 文档解析成本结构重构
PaddleOCR-VL将推动行业从"高价高精度"或"低价低精度"的二元选择,转向"高精度-高效率-低成本"的三元平衡。预计到2026年,企业文档处理综合成本将降低60%,极大加速数字化转型进程。
2. 多模态能力边界拓展
该模型展现出的图表理解能力预示着文档解析向"深度理解"迈进。未来版本将进一步增强数据可视化分析能力,实现从"信息提取"到"洞察生成"的跨越,为商业智能决策提供直接支持。
3. 开源生态加速形成
作为GitHub上星数超50k的中国OCR项目,PaddleOCR已形成活跃社区。新模型的开源将吸引更多开发者参与,预计2026年将出现基于该框架的100+垂直领域解决方案,覆盖医疗、法律、教育等专业场景。
总结与建议:把握文档智能新机遇
PaddleOCR-VL的发布标志着文档解析进入"轻量级高精度"时代,其0.9B参数实现的性能突破重新定义了行业标准。对于企业用户,建议优先在财务发票处理、多语言文档管理等场景试点应用,逐步扩展至核心业务流程。开发者可通过自定义数据集微调,进一步提升特定场景性能。
随着模型持续迭代,未来将在低光照识别、超长篇文档处理等方向持续优化。对于追求高效、精准、低成本文档智能解决方案的组织而言,PaddleOCR-VL无疑是2025年最值得关注的技术选择。
项目地址:https://gitcode.com/paddlepaddle/PaddleOCR
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







