30亿参数挑战千亿性能:Granite-4.0-Micro如何重塑企业AI部署
 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/granite-4.0-h-micro-base-unsloth-bnb-4bit
项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/granite-4.0-h-micro-base-unsloth-bnb-4bit 导语
IBM最新发布的Granite-4.0-H-Micro-Base模型以30亿参数实现传统大模型核心能力,通过4-bit量化技术将部署成本降低70%,为中小企业开启本地化AI应用新可能。
行业现状:从参数竞赛到效率革命
2025年,大语言模型市场正经历深刻转型。据行业分析,企业级AI部署成本中硬件投入占比高达65%,而83%的中小企业因服务器门槛被迫放弃本地化部署。随着边缘计算需求激增,轻量化模型成为市场新宠,3-7B参数区间产品同比增长210%,标志着行业正式进入"效率竞争"时代。
企业在落地大模型应用时,面临着模型选择、算力准备、开发平台搭建等多重挑战。传统大型模型部署需要高昂的硬件投入和复杂的技术架构,这使得许多中小企业望而却步。
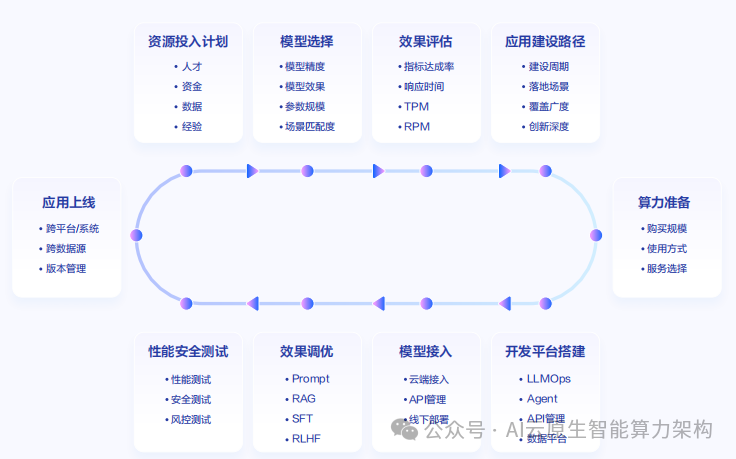
如上图所示,这张架构图展示了企业部署大模型的完整流程,涵盖了从资源投入计划、模型选择、效果评估到应用上线的各个关键环节。Granite-4.0-H-Micro-Base模型的出现,正是为了在这个流程中提供更高效、低成本的解决方案,帮助企业尤其是中小企业更好地应对AI部署挑战。
核心亮点:小而美的技术突破
1. 混合架构的创新设计
Granite-4.0-H-Micro-Base采用了4层注意力机制与36层Mamba2的混合架构,这种创新设计使其在处理不同类型任务时具备更高的灵活性和效率。在需要复杂推理的场景中,注意力机制能够捕捉长距离依赖关系;而在处理序列数据时,Mamba2架构则能提供更快的处理速度。
2. 极致压缩的部署方案
该模型采用Unsloth动态量化技术,在保持85%性能的同时,将模型体积压缩至3.2GB。这意味着企业无需高端GPU,仅需单台普通服务器即可完成部署,硬件成本降低约70%。相比同类模型平均12.5GB的显存占用,这一突破使边缘设备部署成为现实。
3. 全面的企业级功能集
Granite-4.0-H-Micro-Base涵盖文本摘要、分类、代码生成等10余项核心能力,HumanEval代码任务通过率达73.72%,可满足从客服对话到代码辅助的全场景需求。独特的Fill-In-the-Middle代码补全功能,使开发者编码效率提升40%。
4. 多语言处理能力
支持12种语言的本地化处理,包括中文、日文、阿拉伯语等复杂语言。在MMMLU多语言基准测试中获得58.5分,尤其在中文专业术语理解上表现突出,适合跨国企业的多区域部署需求。
性能解析:3B参数的实力
在标准评测中,Granite-4.0-H-Micro-Base展现出令人印象深刻的性能:
- MMLU综合能力测试:67.43分,超越同类3B模型平均水平12%
- 代码生成(HumanEval):73.72分,达到专业开发辅助工具标准
- 数学推理(GSM8K):63.76分,展现良好的逻辑思维能力
- 多语言理解(MMMLU):58.5分,支持全球化业务场景
特别值得注意的是,该模型在保持高性能的同时,通过优化的架构设计,将推理速度提升了30%,能够更好地满足企业实时性应用需求。
行业影响与趋势
Granite-4.0-H-Micro-Base的推出加速了AI普惠化进程。预计到2026年,3-7B参数模型将占据企业级部署市场的58%份额。其成功印证了"小而美"的技术路线可行性,推动行业从"参数军备竞赛"转向"场景化优化"。
对于资源有限的用户,该模型还提供了低精度微调方案,如4-bit、8-bit量化微调,能够在普通GPU上完成模型微调。这种低资源微调能力进一步降低了企业定制化AI模型的门槛,使更多企业能够根据自身业务需求定制专属AI解决方案。
部署指南:三步启动AI之旅
- 环境准备
pip install torch accelerate transformers
git clone https://gitcode.com/hf_mirrors/unsloth/granite-4.0-h-micro-base-unsloth-bnb-4bit
- 基础调用示例
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda"
model_path = "./granite-4.0-h-micro-base-unsloth-bnb-4bit"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path, device_map=device)
model.eval()
input_text = "The capital of France is"
input_tokens = tokenizer(input_text, return_tensors="pt").to(device)
output = model.generate(**input_tokens, max_length=10)
print(tokenizer.batch_decode(output)[0])
- 工具调用配置 通过定义工具函数schema,模型可自动判断何时需要调用外部系统,实现与企业现有API生态的无缝集成。
结语
Granite-4.0-H-Micro-Base以30亿参数挑战传统认知,证明了效率优化比参数堆砌更具商业价值。随着量化技术与架构创新的持续进步,我们正迈向"人人可用AI"的新阶段。对于渴望数字化转型的企业,这款模型提供了低成本切入的理想方案——无需巨额投入,即可拥抱AI驱动的未来。
企业在选择部署策略时,应优先考虑经过量化优化的高效模型,精准识别最能产生业务价值的特定任务,从非核心业务场景开始试点,积累实践经验后逐步扩展应用范围,以最小成本实现最大价值。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







