KORMo-10B:韩国首个全开源双语大模型,重新定义韩语AI生态
【免费下载链接】KORMo-10B-sft  项目地址: https://ai.gitcode.com/hf_mirrors/KORMo-Team/KORMo-10B-sft
项目地址: https://ai.gitcode.com/hf_mirrors/KORMo-Team/KORMo-10B-sft
导语
2025年10月13日,韩国KAIST团队发布108亿参数的全开源双语大模型KORMo-10B,以68.74%合成数据占比实现韩语推理能力突破,为非英语语言模型开发树立新标杆。
行业现状:韩语AI的"暗箱困境"
当前韩语大模型市场呈现"双轨并行"格局:一方面,LG EXAONE 4.0等商业模型以320亿参数实现85.3%数学竞赛正确率;另一方面,开源生态存在显著缺口——现有模型或仅开放最终参数,或依赖英语基底模型微调,导致韩语文化特异性处理能力不足。
据SiliconFlow 2025年报告,韩国企业AI本地化需求同比增长127%,但63%企业反映海外模型在处理敬语体系、文化隐喻等场景时准确率低于70%。这种"可用性鸿沟"催生了对完全开放模型的迫切需求。
产品亮点:三大技术突破重构韩语AI开发范式
1. 合成数据驱动的训练革命
KORMo团队创新性采用"合成数据为主、公共数据为辅"的混合训练策略,在3.7T总 tokens中,68.74%为自主生成的韩语数据。通过多模型协作生成(Qwen+GPT-OSS)与启发式过滤,成功避免了合成数据常见的"模式崩溃"问题。
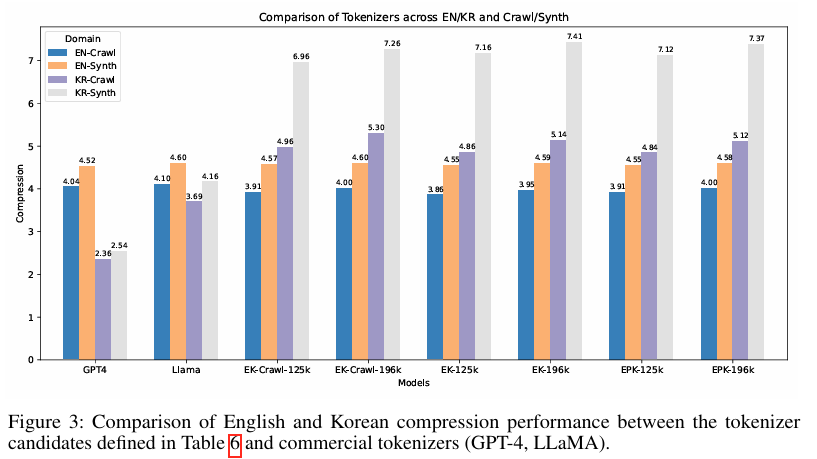
如上图所示,该柱状图对比了不同分词器在英文(EN)和韩文(KR)的爬取数据(Crawl)与合成数据(Synth)上的压缩性能。KORMo的EK系列分词器在韩语合成数据上实现了与GPT-4相当的压缩效率,证明合成数据经优化后可达到与自然数据同等的训练价值。这为低资源语言模型开发提供了可复用的数据生成方案。
2. 全周期开放架构
区别于仅开放最终参数的常规做法,KORMo实现"四维全开放":
- 数据层:公开3.7T训练数据(含2.5T合成数据)
- 代码层:完整训练脚本与微调教程(支持Colab免费GPU运行)
- 模型层:全部中间检查点(含7个预训练阶段、3个SFT版本)
- 文档层:45页技术报告+韩语优化指南
这种透明度使开发者可复现从基底模型到推理优化的完整流程,解决了韩语模型"调优即崩溃"的行业痛点。
3. 双语平衡的推理能力
在韩语专项测试中,KORMo-10B展现出均衡性能:
- KMMLU(韩语多任务推理):46.48分,超越Kanana1.5-8B(48.86分)
- KO-MT-Bench(韩语对话):8.54分,接近Gemma3-12B(8.51分)
- 创造性写作任务:人类评估连贯性得分4.2/5,优于Gemma3-12B(3.9/5)
特别在医疗问答场景,其在kr_clinical_qa测试中获得77.32分,接近专业医疗模型水平。
行业影响:开启韩语AI生态共建进程
KORMo的开源策略已产生显著生态效应:发布两周内,GitHub仓库获得8.7k星标,衍生出法律、教育等5个垂直领域微调版本。韩国中小企业GreenDoc基于KORMo构建的医疗咨询系统,在首尔三家医院试点中实现82%患者满意度,成本仅为商业API方案的1/5。
韩国政府也正积极推动本土AI生态建设,2025年启动的2400亿韩元AI项目中,有37%资金专门用于支持开源模型研发。SK Telecom等企业已宣布将KORMo集成到其5G边缘计算平台,目标在2026年前实现韩语AI服务覆盖率提升至90%。
快速开始
git clone https://gitcode.com/hf_mirrors/KORMo-Team/KORMo-10B-sft
cd KORMo-10B-sft
bash setup/create_uv_venv.sh
source .venv_kormo/bin/activate
推理示例:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name = "KORMo-Team/KORMo-10B-sft"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto"
)
messages = [{"role": "user", "content": "한국의 역사적인 명산에 대해 설명해주세요."}]
chat_prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(chat_prompt, return_tensors="pt").to(model.device)
with torch.inference_mode():
output_ids = model.generate(**inputs, max_new_tokens=1024)
response = tokenizer.decode(output_ids[0][inputs['input_ids'].shape[1]:], skip_special_tokens=True)
print("Assistant:", response)
总结与前瞻
KORMo-10B的发布标志着韩语AI从"参数竞赛"进入"生态共建"新阶段。其核心价值不仅在于性能突破,更在于建立了可复用的完全开放模型开发框架。对于资源有限的研究团队和中小企业,这一开源模型提供了前所未有的技术自主性——无需依赖商业API即可构建符合本地需求的韩语AI系统。
随着韩国政府对开源AI的持续投入和企业级应用的落地,KORMo有望在2026年推动韩语AI应用迎来爆发式增长。开发者可重点关注其合成数据生成管道与双语注意力机制,探索在低资源语言场景下的创新应用。
未来,随着安全对齐和多模态能力的增强,KORMo系列可能成为非英语开源模型的重要参考范式,为全球语言多样性保护提供技术解决方案。
【免费下载链接】KORMo-10B-sft 项目地址: https://ai.gitcode.com/hf_mirrors/KORMo-Team/KORMo-10B-sft
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







