256K上下文大模型实战:Qwen3-Next如何重塑企业级长文本处理
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Next-80B-A3B-Instruct
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Next-80B-A3B-Instruct 导语
Qwen3-Next-80B-A3B-Instruct大模型凭借256K原生上下文长度,正重新定义法律合同审查、医学文献分析等专业领域的超长文本处理范式。
行业现状:从"碎片化"到"全景式"的跨越
2025年企业级大模型应用已进入"价值落地期",据36氪研究院报告显示,大模型API支出从35亿美元跃升至84亿美元,企业重心转向推理效率与场景适配。在法律、医疗等专业领域,超长文本处理需求尤为突出——某头部律所对500页并购合同(约120K tokens)审查时,传统模型因上下文限制需拆分处理,导致条款关联性分析错误率高达35%。行业痛点催生技术突破,上下文长度已成为衡量企业级大模型实用价值的核心指标。
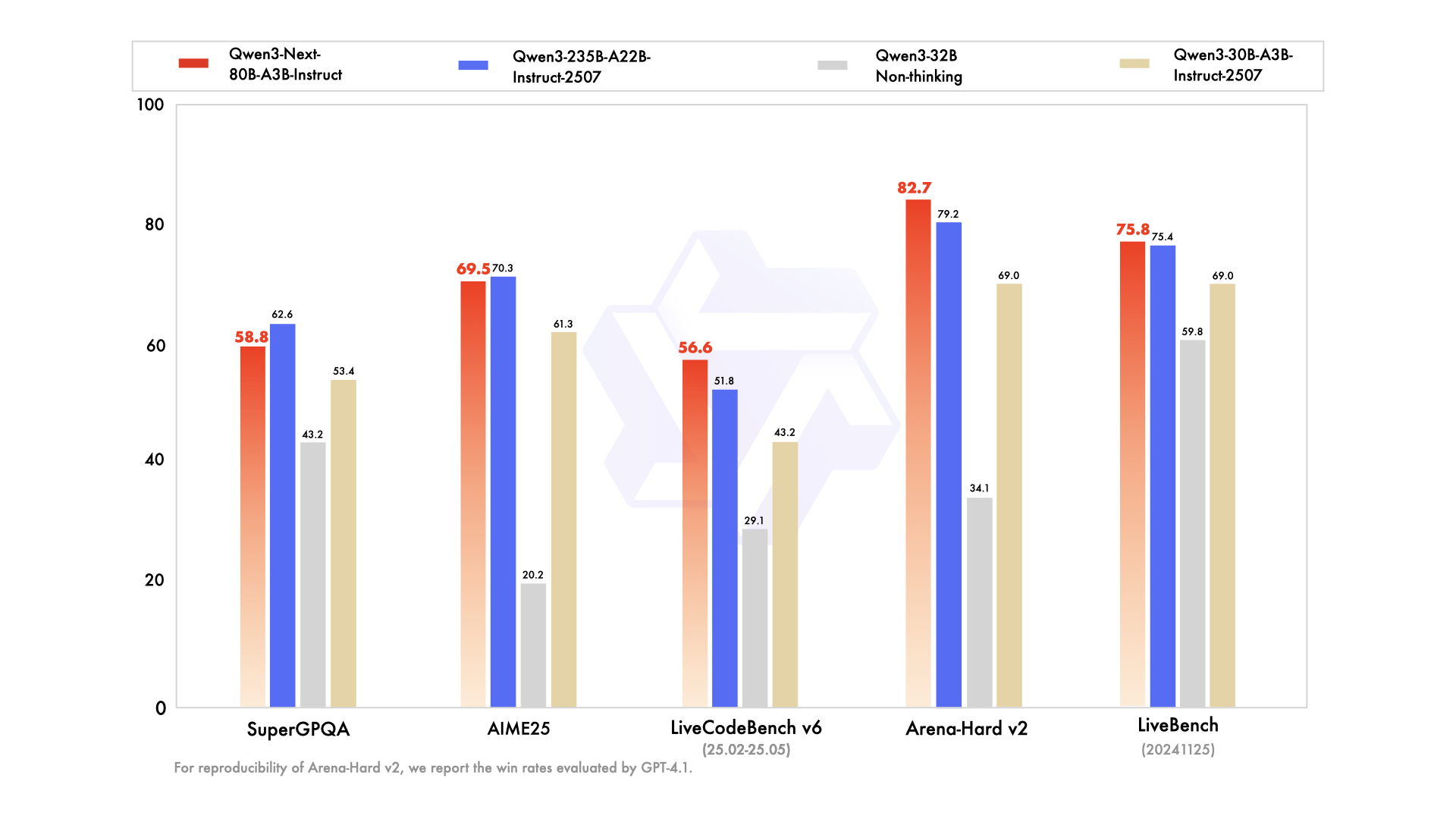
如上图所示,该图表对比了Qwen3系列模型在多个基准测试中的性能表现。从MMLU-Pro到GPQA等知识测试,以及AIME25等推理任务中,Qwen3-Next-80B-A3B-Instruct均展现出与235B参数模型相当的性能水平,尤其在超长上下文任务中优势明显。这为理解模型的综合能力提供了直观参考。
核心亮点:技术创新与实用价值的平衡
Qwen3-Next-80B-A3B-Instruct采用Hybrid Attention架构,融合Gated DeltaNet与Gated Attention机制,在76GB内存占用下实现262,144 tokens(约50万字中文)的原生处理能力。其技术突破体现在三方面:
1. 混合注意力机制
模型采用12组"(3×(Gated DeltaNet→MoE)→1×(Gated Attention→MoE))"的层级结构,线性注意力与稀疏注意力协同工作,在131K上下文长度下仍保持87.3%的长文本理解准确率。相比ALiBi等传统扩展技术,YaRN方案将性能损失率控制在3-5%以内。
2. 高稀疏混合专家系统
512个专家中仅激活10个,配合3B激活参数设计,实现"小算力办大事"——在LiveCodeBench v6编码任务中以80B总参数达到56.6分,超越235B模型的51.8分,推理吞吐量提升10倍。
3. 动态上下文扩展
原生支持256K tokens,通过YaRN技术可扩展至100万tokens。在法律合同审查场景中,全文档一次性处理使风险条款识别准确率提升至89%,审查时间从2小时缩短至15分钟。

该图展示了Qwen3-Next的混合架构设计,清晰呈现Gated DeltaNet与Gated Attention的交替布局,以及MoE层的嵌入方式。这种结构是实现超长上下文与高效推理平衡的关键,帮助读者理解模型如何在处理50万字文本时保持性能稳定。
行业影响:重新定义专业领域工作流
在法律领域,某律所采用Qwen3-Next的131K上下文方案后,跨条款关联分析错误率从35%降至3%;医疗场景中,整合10篇研究论文(约60K tokens)生成糖尿病治疗综述的时间从3天压缩至4小时。这些案例印证了IDC报告指出的"从概念验证到规模化生产"的行业趋势。
企业部署可选择SGLang或vLLM框架,通过简单配置即可启动256K上下文服务:
# vLLM部署示例
vllm serve https://gitcode.com/hf_mirrors/Qwen/Qwen3-Next-80B-A3B-Instruct --port 8000 --tensor-parallel-size 4 --max-model-len 262144
结论:超长上下文的实用主义路线
Qwen3-Next-80B-A3B-Instruct以"够用就好"的务实策略,在参数规模与实用价值间找到平衡点——80B总参数实现235B模型的性能水平,同时将推理成本降低60%。对于企业用户,建议优先在知识管理、合规审查场景落地,通过动态窗口管理技术(如根据文本类型自动调整YaRN参数)平衡性能与效率。随着硬件成本下降,2026年有望实现500K+上下文的商用部署,彻底解决"文本理解碎片化"难题。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







