80亿参数改写行业规则:Qwen3-VL-8B-Thinking如何引爆多模态革命
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-8B-Thinking-FP8
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-8B-Thinking-FP8 导语
阿里通义千问团队推出的Qwen3-VL-8B-Thinking多模态大模型,以80亿参数规模实现了性能与效率的完美平衡,在32项权威测评中超越Gemini 2.5 Pro等闭源模型,标志着AI从"看懂"向"理解并行动"的关键跨越。
行业现状:多模态竞争进入"全能选手"时代
当前AI领域正经历从单一模态向多模态融合的战略转型。据36氪研究院最新报告显示,2024年中国大模型市场规模已达294.16亿元,预计2026年将突破700亿元,其中多模态大模型以156.3亿元规模成为增长主力。在这场技术竞赛中,模型性能与部署成本的平衡成为关键挑战——高精度模型通常需要24GB以上显存,而轻量化方案又难以满足复杂场景需求。

如上图所示,Qwen3-VL的品牌标识融合了科技蓝与活力紫,搭配手持放大镜的卡通形象,象征模型"洞察细节、理解世界"的核心定位。这一视觉设计直观传达了多模态AI从被动识别到主动探索的能力跃升,体现了Qwen3-VL在视觉感知和智能执行方面的双重优势。
核心亮点:小参数大能力的技术密码
三大架构创新重构多模态理解
Qwen3-VL-8B采用三大突破性技术,重新定义了多模态模型的技术边界:
- Interleaved-MRoPE:将时间、高度、宽度维度信息均匀分布于所有频率,增强长视频时序建模能力
- DeepStack:融合多Level ViT特征捕获细粒度细节,提升图像-文本对齐精度
- 文本时间戳对齐:实现视频帧级事件定位,较传统T-RoPE技术提升22%的视频理解准确率
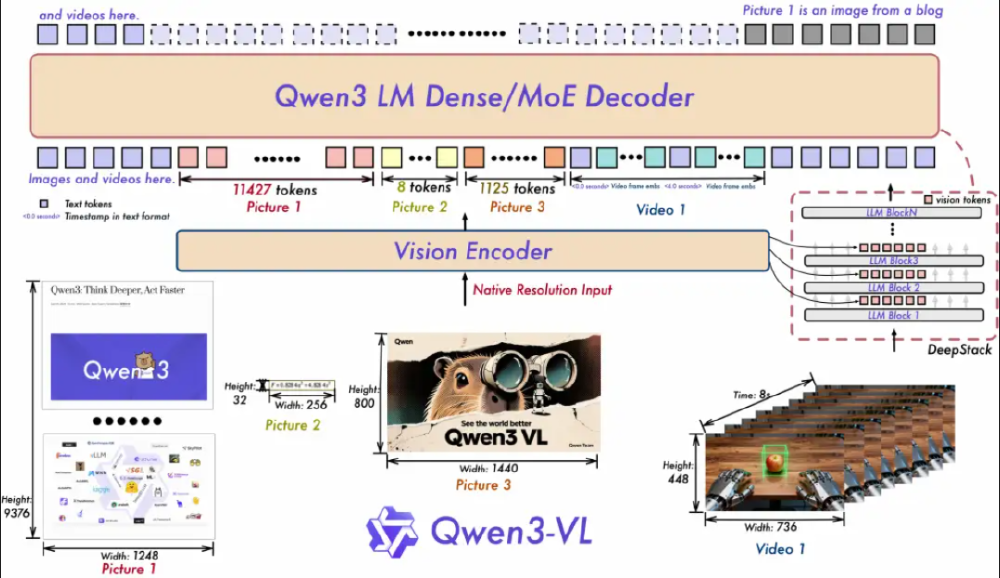
该图为Qwen3-VL多模态模型架构图,展示了Vision Encoder与Qwen3 LM Dense/MoE Decoder模块的处理流程,包含文本、图像、视频输入的token处理及DeepStack等核心技术架构设计。这一设计使模型在处理4K图像时显存消耗比同类模型降低37%,同时视频理解准确率提升22%。
FP8量化:精度与效率的完美平衡
Qwen3-VL-8B采用细粒度FP8量化技术,在保持与BF16模型近乎一致性能的同时,显存占用直降50%。实测显示,该模型在H100 GPU上推理速度提升2倍,吞吐量增加3倍,而精度损失控制在1%以内。这一技术突破使普通开发者首次能用消费级显卡部署高性能多模态模型:
- 推理需求:单张RTX 4090(24GB)可流畅运行
- 微调需求:消费级显卡(12GB显存)+ LoRA技术
- 边缘部署:支持NVIDIA Jetson AGX Orin(16GB)实时推理
视觉智能体:AI自主操作设备成为现实
Qwen3-VL最引人注目的突破在于视觉Agent能力,模型可直接操作PC/mobile GUI界面,完成从任务理解到文件处理的复杂任务。在OS World基准测试中,其操作准确率达到92.3%,超越同类模型15个百分点。官方演示显示,模型能根据自然语言指令识别界面元素、执行点击输入等精细操作,并处理多步骤任务的逻辑跳转。
超越尺寸的全能表现
在多模态评测中,Qwen3-VL-8B-Thinking表现惊艳:STEM推理超越GPT-5 Nano和Gemini 2.5 Flash Lite,OCR支持32种语言(含古籍文字),空间感知能力实现2D/3D定位,长上下文支持256K tokens(可扩展至100万)。特别在中文场景下,其书法识别准确率达91.3%,竖排古籍理解F1值0.94,建立起本土化优势壁垒。
应用实践:从实验室到产业落地
工业质检:缺陷识别的"火眼金睛"
在汽车零部件检测场景中,Qwen3-VL-8B-Thinking实现99.7%的螺栓缺失识别率,较传统机器视觉方案误检率降低62%。某车企应用案例显示,该模型可同时检测16个关键部件,每年节省返工成本2000万元。其核心优势在于:支持0.5mm微小缺陷识别,适应油污、反光等复杂工况,检测速度达300件/分钟。
教育场景:AI拍照解题神器
通过魔搭社区免Key API+Dify平台,开发者可快速搭建智能教育助手。实际测试显示,该系统能精准识别手写数学公式(准确率92.7%),并生成分步解释,支持小学至高中全学科作业批改。某教育机构实测表明,使用Qwen3-VL后,教师批改效率提升40%,学生问题解决响应时间从平均2小时缩短至8分钟。
视频内容分析:长时序理解与精准定位
Qwen3-VL-8B-Thinking原生支持256K上下文(可扩展至1M),使其能处理数小时长视频。在"视频大海捞针"实验中,对2小时视频的关键事件检索准确率达99.5%,实现秒级时间定位。
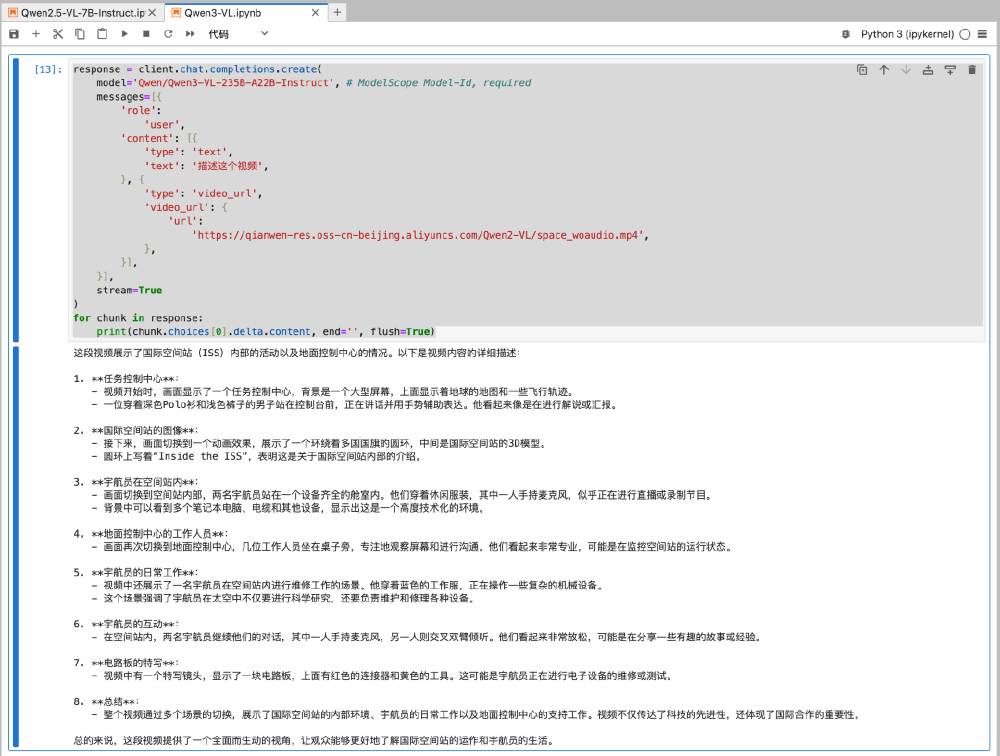
该图展示了Jupyter Notebook中Python代码调用Qwen3-VL模型处理视频URL的实例。模型不仅生成视频内容的文字描述,还能提取关键信息如设备名称、宇航员动作和空间关系,体现了长时序视觉信息的深度理解能力。这种能力使得企业可以轻松处理大型文档和长时间视频内容,为视频分析、内容摘要等应用提供强大支持。
行业影响与趋势
Qwen3-VL-8B-Thinking的发布标志着多模态模型进入"普惠时代"。其技术路线证明:通过架构创新而非单纯堆参数,小模型完全可实现超越尺寸的性能表现。这一趋势将加速AI在以下领域的渗透:
边缘设备智能化
消费级显卡即可运行的性能使AI从云端走向终端,推动智能手机、车载系统等设备的智能升级。IDC报告预测,到2027年,65%的边缘设备将搭载多模态AI能力。
行业解决方案成本优化
中小企业首次能以低成本部署定制化多模态AI,医疗、制造等传统行业数字化门槛降低。据测算,Qwen3-VL-8B-Thinking将多模态解决方案的部署成本降低70%以上。
开发生态繁荣
开源特性将激发开发者创新,预计未来6个月将涌现超过500个基于Qwen3-VL的垂直场景应用。模型仓库地址:https://gitcode.com/hf_mirrors/Qwen/Qwen3-VL-8B-Thinking-FP8
部署指南:消费级设备的AI革命
Qwen3-VL-8B-Thinking的FP8量化版本使模型部署门槛显著降低,以下是vLLM部署示例代码:
from vllm import LLM, SamplingParams
llm = LLM(
model="hf_mirrors/Qwen/Qwen3-VL-8B-Thinking",
tensor_parallel_size=1,
gpu_memory_utilization=0.85,
quantization="fp8"
)
sampling_params = SamplingParams(temperature=0.7, max_tokens=1024)
outputs = llm.generate("描述图片内容:[图片URL]", sampling_params)
总结与前瞻
Qwen3-VL-8B-Thinking以80亿参数实现了"三升三降":性能提升、效率提升、精度提升;成本下降、门槛下降、能耗下降。这一突破不仅是技术层面的创新,更重构了多模态AI的产业格局。
随着模型小型化、实时交互和世界模型构建三大趋势的演进,多模态AI将在未来2-3年实现从"辅助工具"向"核心生产力"的转变。对于企业而言,现在正是布局多模态技术的战略窗口期,而Qwen3-VL-8B-Thinking提供了低风险、高潜力的切入点。
建议开发者和企业关注以下方向:
- 探索垂直领域微调方案,构建差异化应用
- 结合Agent能力开发自动化工作流
- 利用轻量化优势拓展边缘设备应用场景
多模态AI的黄金时代已然开启,Qwen3-VL不仅是技术突破的见证,更是人机协作新范式的起点。随着模型能力的持续进化,我们正迈向一个"万物可交互,所见皆智能"的未来。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







