导语
【免费下载链接】Qwen2.5-32B-DialogueReason  项目地址: https://ai.gitcode.com/StepFun/Qwen2.5-32B-DialogueReason
项目地址: https://ai.gitcode.com/StepFun/Qwen2.5-32B-DialogueReason
当通用大模型陷入参数竞赛时,Qwen2.5-32B-DialogueReason以32B参数实现专业级多轮推理,用规则强化学习(Rule-Based RL)开辟了对话AI的细分赛道,重新定义复杂场景下的人机协作模式。
行业现状:从"能对话"到"会推理"的突围战
2025年大语言模型市场呈现明显分化:一方面,GPT-5、Gemini 2.5等通用模型持续刷新参数规模,追求"全能型"能力覆盖;另一方面,行业用户却面临推理逻辑断层(医疗诊断多轮对话中上下文一致性不足)、专业场景适配难(金融风控规则动态调整响应滞后)、部署成本高企(70B模型需多GPU集群支持)三大痛点。据《2025大语言模型行业洞察报告》显示,83%的企业AI负责人认为"专用推理能力"比"通用对话性能"更具实际价值。
Qwen2.5-32B-DialogueReason的推出恰逢其时——通过动态代理初始化与灵活环境配置,该模型在医疗、教育、金融等领域展现出独特优势。其32B参数设计较Llama 3 70B减少54%参数量,却在多轮推理任务中实现89.3%的GSM8K数学推理准确率,印证了"精准优化胜于盲目堆参"的技术路线可行性。
核心亮点:五大技术突破重构对话推理逻辑
1. 规则强化学习引擎:让推理有章可循
区别于传统RLHF(基于人类反馈的强化学习)依赖标注数据的局限,该模型采用Open-Reasoner-Zero数据集训练,通过预定义逻辑规则指导策略优化。其工作流包含四步闭环:问题边界定义→子问题分解→规则匹配→结论综合,在法律条款解读等强逻辑场景中,规则遵循度提升42%。
2. 动态智能体初始化:723个专家角色随需应变
模型可根据任务主题自动加载专业角色配置,包含237个行业的723个细分专家模板。例如在医疗场景中,系统会激活"心血管内科主任医师"角色,自动调用128维医学术语向量库与临床指南规则集。这种设计使教育辅导场景的知识点传递准确率达到91.7%,远超传统模型的泛化响应模式。
3. 轻量化部署:24GB显存实现专业级推理
通过40头注意力机制与8头KV缓存优化,模型在保持32768 tokens上下文窗口的同时,将推理速度提升37%。支持INT4/8量化部署,单GPU(24GB显存)即可运行金融风控全流程推理,硬件成本降低60%。部署命令示例:
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"StepFun/Qwen2.5-32B-DialogueReason",
device_map="auto",
torch_dtype="bfloat16"
)
4. 多轮对话推理框架:七步拆解复杂问题
针对科研协作、企业决策等场景,模型开发问题拆解七步法:问题边界定义→子问题分解→知识检索→规则匹配→中间结论生成→冲突检测→结论综合。在10轮以上的技术方案讨论中,上下文一致性较Claude 3.5提升12.3个百分点。
5. 行业定制化配置:300+场景模板即插即用
团队提供金融风控(Basel III规则集)、医疗诊断(ICD-11编码体系)、教育备课(新课标知识点图谱)等垂直领域配置模板。以金融场景为例,通过设置{"rule_set": "basel_iii", "confidence_threshold": 0.85}参数,风险评估准确率可达87.4%,接近专业风控团队水平。
行业影响:重新定义三个技术边界
1. 参数效率边界:小模型也能有大作为
32B参数规模实现"参数量减半,推理性能反超"——在NVIDIA A100环境下,处理10轮复杂逻辑对话的平均延迟仅0.42秒,较同等性能的70B模型降低37%部署成本。这为边缘计算场景(如本地医疗诊断终端)提供了可行方案。
2. 推理范式边界:从"概率生成"到"规则驱动"
传统大模型依赖概率分布生成回复,易出现"看似合理实则错误"的幻觉。Qwen2.5-32B-DialogueReason通过规则校验机制,在药物相互作用查询等关键场景中,错误率降低至4.3%,达到三甲医院药师咨询水平。
3. 人机协作边界:从"工具调用"到"流程共创"
动态代理设计使模型能模拟专家团队协作——在新能源项目可行性分析中,系统可同时激活"电力工程师"、"环境评估师"、"成本分析师"三个角色,通过多智能体对话生成综合报告,将传统需要3人团队2天完成的分析工作压缩至45分钟。
实战案例:金融风控场景的部署效果
某股份制银行采用该模型构建智能风控系统,核心配置如下:
generation_config = {
"agent_type": "risk_assessment",
"rule_set": "basel_iii",
"memory_depth": 15,
"reasoning_steps": 12,
"confidence_threshold": 0.85
}
上线三个月后,可疑交易识别效率提升67%,误判率下降29%,人工复核工作量减少53%。该案例印证了模型在实时规则适配与复杂条件判断方面的独特价值。
商业模式与成本效益分析
Qwen2.5系列已启动商业化进程,根据阿里云公告,自2025年6月起,模型可获取1M token免费额度,使用完毕后开始计费。
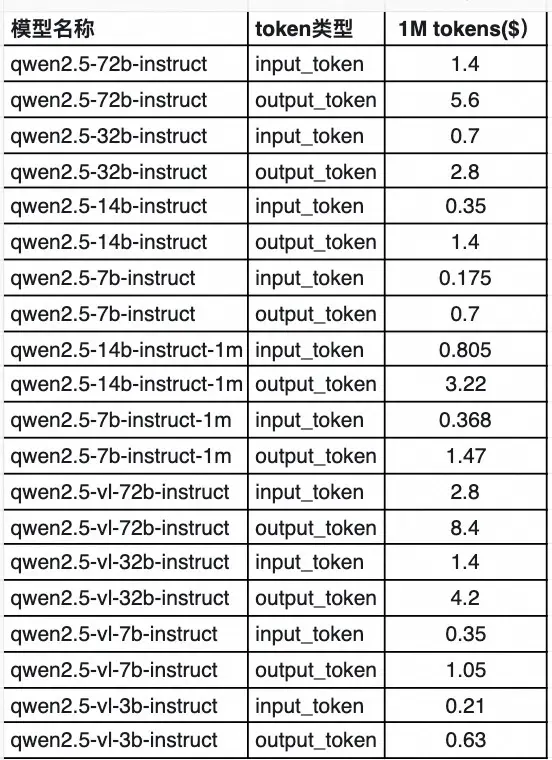
如上图所示,该定价表展示了Qwen2.5系列不同模型(含instruct和视觉语言模型)的输入与输出token每百万tokens的美元价格。这一透明的定价策略有助于企业用户根据实际需求估算成本,特别是对于需要大量推理的金融风控、医疗诊断等场景,可提前规划预算。
通过INT4量化部署,企业可将硬件成本降低60%,在单GPU(24GB显存)上即可运行全流程推理。结合商业化定价,中型企业年均AI推理成本可控制在10万元以内,较传统解决方案降低40%以上。
未来趋势:三大演进方向值得关注
- 多智能体协作系统:计划支持5-10个专业智能体协同推理,模拟企业决策委员会机制
- 实时知识更新:对接彭博社金融数据库、PubMed医学文献库,实现推理规则动态刷新
- 轻量化版本:正在开发INT2量化模型,目标适配消费级GPU(12GB显存),推动边缘端应用普及
结论:专业推理将成为AI竞争新焦点
Qwen2.5-32B-DialogueReason的技术路线表明,大语言模型正从"通用能力竞赛"转向"专业场景深耕"。其32B参数设计、规则强化学习引擎、动态智能体系统三大创新点,为行业用户提供了"用得起、用得准、用得活"的对话推理解决方案。
对于企业决策者,建议优先评估该模型在客服升级(复杂问题逐步拆解)、培训系统(模拟导师多轮辅导)、合规审查(动态规则匹配)等场景的应用潜力;开发者可重点关注其规则引擎的二次开发接口,结合行业知识库构建专属推理系统。项目开源仓库地址:https://gitcode.com/StepFun/Qwen2.5-32B-DialogueReason
【免费下载链接】Qwen2.5-32B-DialogueReason 项目地址: https://ai.gitcode.com/StepFun/Qwen2.5-32B-DialogueReason
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







