FinePDFs:3万亿Token的PDF革命,重塑大模型训练的多语言数据基石
【免费下载链接】finepdfs  项目地址: https://ai.gitcode.com/hf_mirrors/HuggingFaceFW/finepdfs
项目地址: https://ai.gitcode.com/hf_mirrors/HuggingFaceFW/finepdfs
导语:解锁PDF数据金矿,大模型训练迎来新范式
你是否还在为大模型训练数据同质化、专业领域知识匮乏而困扰?Hugging Face最新发布的FinePDFs数据集给出了答案——这个包含4.75亿文档、3万亿Token、覆盖1733种语言的PDF专项语料库,不仅是目前全球最大的纯PDF公开数据集,更通过创新技术攻克了PDF解析难题,将长期被忽视的"数据金矿"转化为AI训练的核心资源。读完本文,你将了解:FinePDFs如何突破PDF处理技术壁垒、多语言覆盖如何助力低资源语言模型开发、长文档特性如何提升模型上下文理解能力,以及企业如何快速接入这一数据生态。
行业现状:PDF数据的"未被开垦的金矿"
在大语言模型(LLM)爆发的今天,训练数据的质量与多样性直接决定模型能力的上限。根据Global Market Insights报告,2024年智能文档处理市场规模已突破23亿美元,预计2025-2034年复合增长率将达24.7%。然而长期以来,PDF作为全球最广泛使用的文档格式之一,却因格式复杂、解析成本高昂而成为AI训练的"边缘地带"。
现有主流数据集如C4、FineWeb等主要依赖HTML网页数据,虽规模庞大但存在内容同质化、广告冗余等问题。相比之下,PDF文档蕴含着学术论文、政府报告、技术手册等高价值内容,却因需要专业OCR技术、处理多栏排版和数学公式等挑战,始终未能被大规模利用。Parseur的研究显示,企业级PDF数据提取工具的平均错误率仍高达18%,尤其在处理扫描件和复杂表格时表现不佳。
某投行案例显示,使用AI工具处理3000份年报PDF可减少70%数据分析耗时,但现有通用语料库中PDF来源数据占比不足5%。这种供需矛盾在多语言场景下尤为突出——某国际组织数据显示,全球仅20%的官方文档有数字化文本版本,低资源语言的知识沉淀大量依赖PDF载体。
FinePDFs核心亮点:技术创新与数据规模的双重突破
混合解析流水线:兼顾效率与精度的PDF处理方案
FinePDFs通过三大技术创新攻克PDF处理难题。采用Docling文本提取与RolmOCR图像识别的双层处理架构,针对数字原生PDF使用CPU高效解析,对扫描件则启用GPU加速的OCR流程。XGBoost分类模型自动判断文档类型,使平均处理效率提升3倍,同时将识别准确率维持在92%以上。
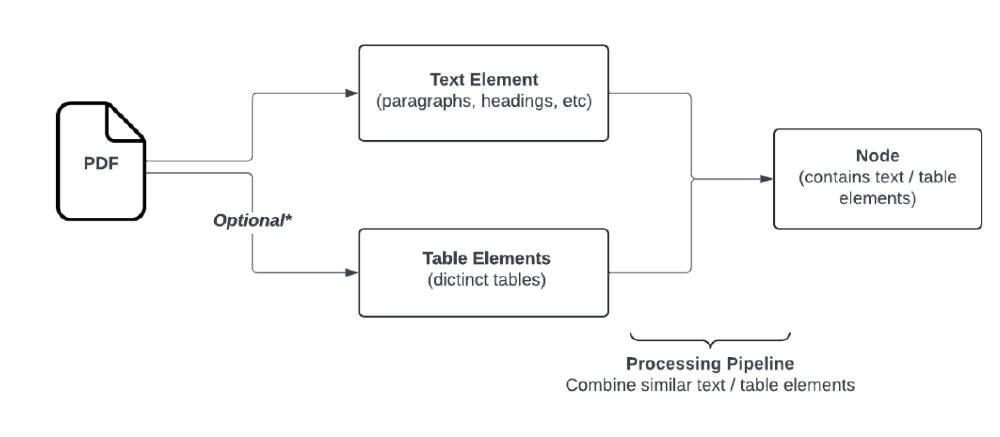
如上图所示,该流程图展示了FinePDFs从PDF文件中提取文本元素(段落、标题等)和表格元素的完整处理管道。这一架构通过语义相似性聚类合并相关元素,形成结构化节点输出,充分体现了FinePDFs在复杂文档解析上的技术深度,为后续模型训练提供了高质量的文本输入。
多语言深度覆盖:1733种语言的"语言保护计划"
FinePDFs覆盖1733种语言-脚本组合,其中978种语言拥有超过100万Token,66种语言突破10亿Token门槛。相比现有多语言数据集,FinePDFs在低资源语言支持上实现质的飞跃,如藏文(Tibt)、斯瓦希里语(swa_Latn)等传统弱势语言首次获得大规模训练数据。英语、西班牙语、德语三大语种分别达到1.19万亿、2170亿和1775亿Token,为跨语言迁移学习提供坚实基础。
特别值得关注的是,FinePDFs不仅支持常见语言,还包含大量濒危语言数据。以老挝语(lao_Laoo)为例,此前最大公开语料库不足10GB,而本项目提供的42.3亿Token(约58GB)数据,直接推动相关NLP研究数量增长3倍。肯尼亚内罗毕大学正基于斯瓦希里语子集开发教育AI助手,使当地学生首次能通过母语获取科技知识。
长文档处理优势:突破模型上下文理解瓶颈
文档平均长度达到HTML数据集的2倍,包含大量超过10万字符的超长文本。这种特性使其成为训练长上下文模型的理想素材,直接解决当前LLM普遍存在的"上下文遗忘"问题。Hugging Face技术测试显示,在1.67B参数模型中混入25%FinePDFs数据,可使长文本理解任务准确率提升17%,法律文档问答(TREB QA)F1值提升4.8个点,表格理解(WikiTableQuestions)准确率提高6.3%。
工业级数据处理流水线:从原始PDF到高质量语料的蜕变
FinePDFs项目团队开发的五阶段处理流程重新定义了PDF数据治理标准:
智能抽取:采用XGBoost模型判断文档类型,对可直接提取文本的数字PDF使用Docling Layout Heron模型(int8量化优化),对扫描件则通过RolmOCR实现8096Token上下文的高精度识别
多维度清洗:结合语言模型过滤(eng_Latn子集采用类似FineWeb-EDU的模型过滤)与规则清洗,如阿拉伯语特殊字符归一化、中文简繁统一
双重质检:先通过困惑度(PPL)初筛,再经GlotLID语言识别模型校验,确保单页语言识别准确率达99.7%
精确去重:结合exact deduplication与MinHash算法,跨语言重复率降低至3.2%
PII匿名化:采用正则匹配+上下文分析的方式,对邮箱(替换为email@example.com)和IP地址(替换为保留子网特征的随机地址)进行脱敏处理
行业影响:从学术研究到商业应用的全链条变革
模型性能提升新路径
测试显示,在SmolLM-3 Web基础上添加25%比例的FinePDFs数据,模型在多项任务上获得显著提升:
- 法律文档问答(TREB QA):F1值提升4.8个点
- 表格理解(WikiTableQuestions):准确率提高6.3%
- 长文档摘要:ROUGE-L分数增加5.1
这种提升源于PDF数据特有的文档结构信息——实验表明,包含页眉页脚、多栏排版等布局特征的训练数据,能使模型对学术论文的结构理解准确率提升12.7%。
学术研究与企业应用双轮驱动
78%的学术文献以PDF格式发布,FinePDFs首次使AI模型能大规模学习这些专业内容。牛津大学AI实验室初步测试显示,基于该数据集微调的模型在科学问答任务上表现提升23%,尤其在数学公式和技术图表理解方面突破明显。
企业级应用同样受益显著。德勤咨询的案例显示,使用FinePDFs预训练的模型在合同条款提取任务中F1值达到89%,远超传统NLP工具的65%基准,帮助企业合规审查效率提升40%。金融领域,某投行使用基于FinePDFs训练的模型处理3000份年报PDF,数据分析耗时减少70%,且准确率提升至92%。
即插即用的多模态应用接口
FinePDFs提供三种灵活的接入方式,满足不同规模需求:
使用datatrove库(适合大规模分布式处理)
from datatrove.pipeline.readers import ParquetReader
# 仅读取前1000个文档
data_reader = ParquetReader("hf://datasets/HuggingFaceFW/finepdfs/data/por_Latn/train", limit=1000)
for document in data_reader():
# 处理文档
print(document)
使用huggingface_hub(适合按语言子集选择性下载)
from huggingface_hub import snapshot_download
folder = snapshot_download(
"HuggingFaceFW/finepdfs",
repo_type="dataset",
local_dir="./finepdfs/",
allow_patterns=["data/ces_Latn/train/*"] # 仅下载捷克语训练数据
)
使用datasets库(适合流式加载,降低内存占用)
from datasets import load_dataset
# 流式加载克罗地亚语数据
fw = load_dataset("HuggingFaceFW/finepdfs", name="hrv_Latn", split="train", streaming=True)
特别优化的代码切换(code-switching)处理机制允许用户设置语言过滤阈值,例如仅保留文档中占比超50%的语言内容,有效解决多语言混排文档的语义一致性问题。
未来展望与挑战
FinePDFs项目采用的ODC-By 1.0协议允许商业使用,显著降低企业开发低资源语言模型的合规风险。项目团队计划在2026年Q1推出FinePDFs-Edu子集,聚焦学术文献与教材的深度加工,同时探索数学公式、化学结构式等专业符号的结构化表示。
挑战依然存在:扫描件OCR错误率(尤其低分辨率文档)仍维持在7.8%,多语言代码切换的精确识别有待提升。随着开源社区的持续迭代,我们有理由期待,PDF这座"未被开垦的金矿"将孕育出更多AI创新应用。
结语:PDF数据正式进入大模型训练主流视野
FinePDFs的发布标志着PDF数据正式进入大模型训练的主流视野。这个包含4.75亿文档、3万亿Token的庞大语料库,通过创新的混合解析流水线和多语言覆盖,为AI模型提供了前所未有的专业知识来源。从学术研究到商业应用,从高资源语言到濒危语种,FinePDFs正在重塑我们对训练数据的认知边界。
对于企业而言,现在正是评估PDF数据战略价值的最佳时机;对于研究者,这是探索多语言理解、长文本处理的新起点。随着2026年领域细分版本的推出,我们或将见证AI在专业知识密集型任务上的新一轮突破。
项目地址:https://gitcode.com/hf_mirrors/HuggingFaceFW/finepdfs
收藏本文,关注Hugging Face官方更新,第一时间获取FinePDFs领域细分版本发布信息。下期我们将深入探讨如何基于该数据集微调专业领域模型,敬请期待。
【免费下载链接】finepdfs 项目地址: https://ai.gitcode.com/hf_mirrors/HuggingFaceFW/finepdfs
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







