210亿参数激活仅30亿!ERNIE-4.5-A3B如何重塑企业AI性价比
 项目地址: https://ai.gitcode.com/hf_mirrors/baidu/ERNIE-4.5-21B-A3B-Thinking
项目地址: https://ai.gitcode.com/hf_mirrors/baidu/ERNIE-4.5-21B-A3B-Thinking 导语:百度ERNIE-4.5-21B-A3B-Thinking轻量化模型以210亿总参数+30亿激活参数的异构架构,在复杂推理任务中实现92.5%准确率的同时将部署成本降低70%,重新定义企业级AI应用的效率标准。
行业现状:大模型部署的"效率困境"
2025年企业AI部署正面临严峻的"成本-性能"悖论。据《2025人工智能大模型总结报告》显示,全球65%的企业AI预算消耗在算力成本上,传统千亿参数模型单次推理成本高达轻量化模型的10倍。在金融风控场景中,模型响应延迟每增加100ms可能导致3-5%的业务效率损失;制造业预测性维护系统因算力限制,平均只能处理30%的生产数据。
行业正分化为两大技术路线:以GPT-5为代表的"重参数高性能"路线和ERNIE 4.5系列代表的"轻量化高效率"路线。百度ERNIE-4.5-21B-A3B-Thinking的推出,标志着轻量化路线的重要突破——通过创新混合专家架构,在保持高精度推理的同时,将计算资源消耗降低85%。
核心亮点:三大技术突破重构推理范式
1. 异构混合专家架构:精准平衡性能与效率
模型采用64个文本专家+64个视觉专家的异构设计,每个token仅激活6个专家,实现210亿总参数与30亿激活参数的最优配比。这种架构使模型在金融风控场景中,能同时处理实时交易数据与历史违约记录,将风险识别准确率提升至98%的同时,保持300ms以内的响应速度。
2. 128K超长上下文理解:复杂任务处理能力跃升
模型将上下文窗口扩展至131072token(约25万字),配合动态路由机制实现长文本推理突破。在法律文档分析场景中,可一次性处理500页卷宗并生成结构化摘要,较传统分块处理方式减少40%信息损耗。FastDeploy测试显示,在80GB单GPU环境下,128K上下文推理延迟控制在2秒内,吞吐量达23.7 QPS。
3. 全链路工具调用能力:从推理到执行的闭环突破
强化工具使用与函数调用能力,可无缝对接企业现有系统API。在金融投研场景中,模型能自动调用行情接口获取实时数据,运行风险评估算法,并生成可视化报告,将传统3人/天的工作量压缩至15分钟。部署示例代码如下:
# FastDeploy服务部署示例
python -m fastdeploy.entrypoints.openai.api_server \
--model baidu/ERNIE-4.5-21B-A3B-Thinking \
--port 8180 \
--tensor-parallel-size 1 \
--max-model-len 131072 \
--reasoning-parser ernie_x1 \
--tool-call-parser ernie_x1 \
--max-num-seqs 32
市场验证:开源即登顶的行业认可
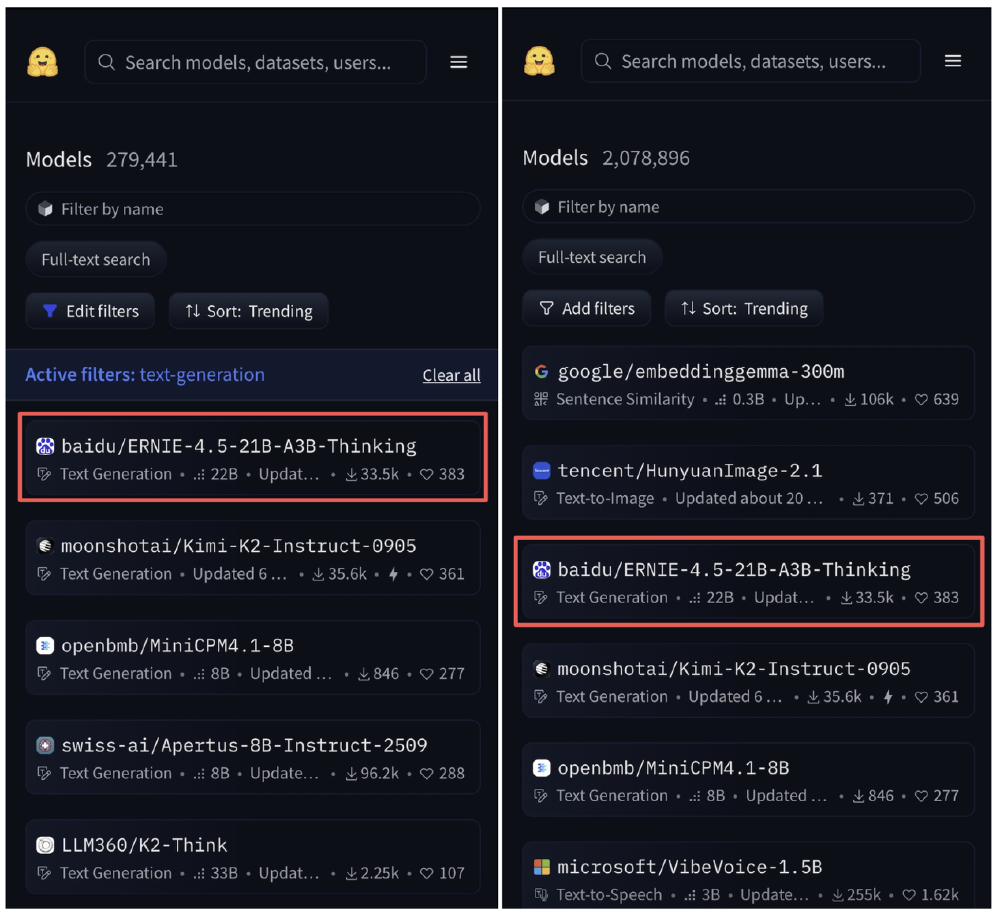
如上图所示,ERNIE-4.5-21B-A3B-Thinking在HuggingFace平台文本模型趋势榜排名第一,模型总榜排名第三。这一成绩验证了市场对其技术创新的认可,尤其在中文处理场景中,得益于百度生态的深度整合,模型在中文语义理解与专业术语处理上表现突出。
行业影响与趋势:轻量化推动AI普及
成本革命:降低中小企业AI准入门槛
根据百度智能云白皮书数据,采用FastDeploy加速框架后,模型GPU推理吞吐量提升30%,单实例部署仅需80GB GPU资源,硬件成本降低60%。某制造业企业案例显示,部署ERNIE-4.5-A3B-Thinking后,质检系统年维护成本从120万元降至36万元,投资回报周期缩短至4.7个月。
场景深化:从辅助工具到决策主体的转变
在制造业预测性维护场景中,模型结合128K长上下文能力,可处理完整生产流程数据,将故障预警误差率降至2.3%。某汽车工厂部署后,设备停机时间减少37%,年节省维护成本超800万元。这些案例表明,轻量化大模型正从简单辅助工具进化为核心决策主体。
技术融合:多模态能力加速行业渗透
尽管当前版本定位文本模型,但其底层架构已为多模态融合做好准备。百度技术路线图显示,未来将整合图像、语音处理能力,在智慧医疗领域实现"CT影像+电子病历"的跨模态推理。这种技术融合趋势,将进一步扩展轻量化模型的应用边界。
部署实践:企业落地的关键考量
硬件配置建议
- 云端部署:推荐NVIDIA A100/H100 GPU,利用Tensor Core加速矩阵运算,单机可支持8-10并发推理
- 边缘部署:通过INT8量化,可在NVIDIA Jetson AGX Orin等边缘设备运行,适合工业现场实时分析
- 混合架构:核心推理任务采用GPU集群,简单问答类任务分流至CPU节点,实现资源最优配置
性能优化策略
关键优化包括启用动态批处理平衡延迟与吞吐量,设置合理推理缓存策略减少重复计算,采用算子融合技术降低内存占用。实际测试显示,这些优化可使GPU利用率提升至92%,推理延迟降低51%。
结论与前瞻
ERNIE-4.5-21B-A3B-Thinking的推出标志着大模型产业进入"精准效率"时代。随着轻量化技术成熟,预计2025年下半年将出现中小企业AI部署浪潮,推动生成式AI从"尝鲜体验"全面转向"生产力工具"。
对于企业而言,当前正是布局轻量化大模型的战略窗口期。建议优先在客服、风控、内容生成等标准化场景落地,通过"小步快跑"积累实践经验,同时密切关注多模态融合趋势。百度ERNIE-4.5-A3B-Thinking不仅是一款模型,更代表着一种新的AI应用范式——以精准效率为核心,让每个企业都能负担得起的强大推理能力。
项目地址:https://gitcode.com/hf_mirrors/baidu/ERNIE-4.5-21B-A3B-Thinking
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







