CogVLM2系列模型:多模态理解新突破,开源生态持续升级
 项目地址: https://ai.gitcode.com/zai-org/cogvlm2-llama3-chinese-chat-19B
项目地址: https://ai.gitcode.com/zai-org/cogvlm2-llama3-chinese-chat-19B 👋 欢迎加入我们的 微信交流群 💡 立即体验 CogVLM2图像理解 💡 立即体验 CogVLM2-Video视频分析 📍前往 开放平台 探索更大规模的CogVLM模型能力
最新动态
- 🔥 重要发布:
2024/8/30:CogVLM2研究论文已正式上线arXiv平台,论文编号2408.16500。 - 🔥 功能更新:
2024/7/12:CogVLM2-Video在线演示系统已开放,用户可通过官方体验地址测试视频理解功能。 - 🔥 模型发布:
2024/7/8:推出CogVLM2-Video视频理解模型,采用关键帧提取技术实现动态画面解析,支持最长60秒视频处理。更多技术细节可查阅专题博客。 - 🔥 性能优化:
2024/6/8:发布CogVLM2 TGI优化版本模型权重,适配Hugging Face TGI推理框架,推理效率显著提升。部署代码可参考开源仓库。 - 🔥 轻量化版本:
2024/6/5:发布GLM-4V-9B模型,基于CogVLM2相同训练体系,采用GLM-4-9B作为语言基座,移除视觉专家模块后模型总参数量降至13B。详细说明见GLM-4项目主页。 - 🔥 资源优化:
2024/5/24:推出Int4量化版本模型,显存占用低至16GB即可运行推理任务,大幅降低硬件门槛。 - 🔥 核心发布:
2024/5/20:CogVLM2基础模型正式发布,基于llama3-8b架构开发,在多项评测中展现出与GPT-4V相当甚至更优的性能表现!
技术架构与优势
新一代CogVLM2系列模型基于Meta-Llama-3-8B-Instruct开源基座构建,相比上一代CogVLM模型实现四大突破:
- 核心指标全面提升,在TextVQA、DocVQA等权威评测中刷新开源模型纪录
- 文本处理能力扩展至8K上下文长度,支持长文档理解
- 图像分辨率支持提升至1344×1344像素,细节识别能力增强
- 提供原生中英文双语版本,满足多语言场景需求
模型矩阵概览
| 模型名称 | cogvlm2-llama3-chat-19B | cogvlm2-llama3-chinese-chat-19B | cogvlm2-video-llama3-chat | cogvlm2-video-llama3-base |
|---|---|---|---|---|
| 基础架构 | Meta-Llama-3-8B-Instruct | Meta-Llama-3-8B-Instruct | Meta-Llama-3-8B-Instruct | Meta-Llama-3-8B-Instruct |
| 支持语言 | 英文 | 中文、英文 | 英文 | 英文 |
| 核心功能 | 图像理解,多轮对话 | 图像理解,多轮对话 | 视频理解,单轮对话 | 视频理解,基座模型(无对话功能) |
| 下载地址 | 🤗 Huggingface 🤖 ModelScope 💫 Wise Model | 🤗 Huggingface 🤖 ModelScope 💫 Wise Model | 🤗 Huggingface 🤖 ModelScope | 🤖 ModelScope 🤗 Huggingface |
| 在线演示 | 📙 Official Page | 📙 Official Page 🤖 ModelScope | 📙 Official Page 🤖 ModelScope | / |
| 量化版本 | 🤗 Huggingface 🤖 ModelScope 💫 Wise Model | 🤗 Huggingface 🤖 ModelScope 💫 Wise Model | / | / |
| 文本处理长度 | 8K | 8K | 2K | 2K |
| 视觉输入规格 | 1344×1344像素 | 1344×1344像素 | 224×224像素(视频,取前24帧) | 224×224像素(视频,平均采样24帧) |
性能评测
图像理解能力
CogVLM2在主流多模态评测集上表现卓越,部分指标超越闭源模型。所有测试均采用纯视觉输入方式("only pixel"),未使用外部OCR工具辅助。
| 模型名称 | 开源性 | 语言模型规模 | TextVQA | DocVQA | ChartQA | OCRbench | MMMU | MMVet | MMBench |
|---|---|---|---|---|---|---|---|---|---|
| CogVLM1.1 | ✅ | 7B | 69.7 | - | 68.3 | 590 | 37.3 | 52.0 | 65.8 |
| LLaVA-1.5 | ✅ | 13B | 61.3 | - | - | 337 | 37.0 | 35.4 | 67.7 |
| Mini-Gemini | ✅ | 34B | 74.1 | - | - | - | 48.0 | 59.3 | 80.6 |
| LLaVA-NeXT-LLaMA3 | ✅ | 8B | - | 78.2 | 69.5 | - | 41.7 | - | 72.1 |
| LLaVA-NeXT-110B | ✅ | 110B | - | 85.7 | 79.7 | - | 49.1 | - | 80.5 |
| InternVL-1.5 | ✅ | 20B | 80.6 | 90.9 | 83.8 | 720 | 46.8 | 55.4 | 82.3 |
| QwenVL-Plus | ❌ | - | 78.9 | 91.4 | 78.1 | 726 | 51.4 | 55.7 | 67.0 |
| Claude3-Opus | ❌ | - | - | 89.3 | 80.8 | 694 | 59.4 | 51.7 | 63.3 |
| Gemini Pro 1.5 | ❌ | - | 73.5 | 86.5 | 81.3 | - | 58.5 | - | - |
| GPT-4V | ❌ | - | 78.0 | 88.4 | 78.5 | 656 | 56.8 | 67.7 | 75.0 |
| CogVLM2-LLaMA3(本项目) | ✅ | 8B | 84.2 | 92.3 | 81.0 | 756 | 44.3 | 60.4 | 80.5 |
| CogVLM2-LLaMA3-Chinese(本项目) | ✅ | 8B | 85.0 | 88.4 | 74.7 | 780 | 42.8 | 60.5 | 78.9 |
视频理解能力
CogVLM2-Video在三大视频评测基准上展现优异性能:MVBench、VideoChatGPT-Bench及零样本VideoQA数据集(MSVD-QA、MSRVTT-QA、ActivityNet-QA)。
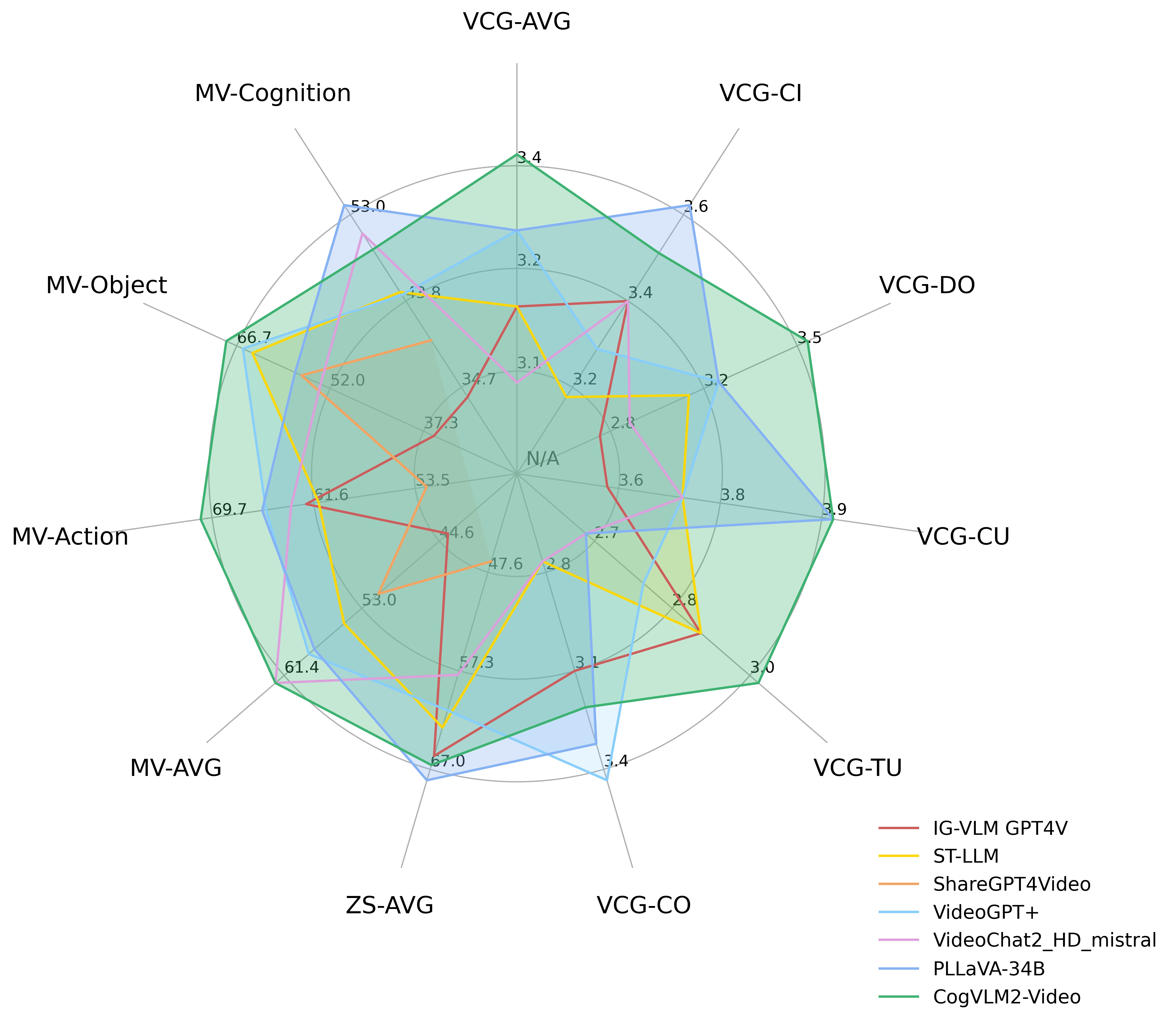 上图展示了CogVLM2-Video与主流视频理解模型的性能对比。图表中VCG代表VideoChatGPTBench数据集,ZS代表零样本VideoQA任务,MV-*系列为MVBench中的主要评测类别。该对比直观呈现了CogVLM2-Video在动态场景理解任务中的技术优势,为开发者选择视频AI解决方案提供参考依据。
上图展示了CogVLM2-Video与主流视频理解模型的性能对比。图表中VCG代表VideoChatGPTBench数据集,ZS代表零样本VideoQA任务,MV-*系列为MVBench中的主要评测类别。该对比直观呈现了CogVLM2-Video在动态场景理解任务中的技术优势,为开发者选择视频AI解决方案提供参考依据。
详细评测数据
VideoChatGPT-Bench与零样本VideoQA结果 | 模型名称 | VCG-AVG | VCG-CI | VCG-DO | VCG-CU | VCG-TU | VCG-CO | ZS-AVG | |----------------------|----------|----------|----------|----------|----------|----------|-----------| | IG-VLM GPT4V | 3.17 | 3.40 | 2.80 | 3.61 | 2.89 | 3.13 | 65.70 | | ST-LLM | 3.15 | 3.23 | 3.05 | 3.74 | 2.93 | 2.81 | 62.90 | | ShareGPT4Video | N/A | N/A | N/A | N/A | N/A | N/A | 46.50 | | VideoGPT+ | 3.28 | 3.27 | 3.18 | 3.74 | 2.83 | 3.39 | 61.20 | | VideoChat2_HD_mistral | 3.10 | 3.40 | 2.91 | 3.72 | 2.65 | 2.84 | 57.70 | | PLLaVA-34B | 3.32 | 3.60 | 3.20 | 3.90 | 2.67 | 3.25 | 68.10 | | CogVLM2-Video | 3.41 | 3.49 | 3.46 | 3.87 | 2.98 | 3.23 | 66.60 |
MVBench数据集评测结果 | 模型名称 | AVG | AA | AC | AL | AP | AS | CO | CI | EN | ER | FA | FP | MA | MC | MD | OE | OI | OS | ST | SC | UA | |----------------------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------| | IG-VLM GPT4V | 43.7 | 72.0 | 39.0 | 40.5 | 63.5 | 55.5 | 52.0 | 11.0 | 31.0 | 59.0 | 46.5 | 4
CogVLM2系列模型通过持续的技术创新和开源实践,正在构建完整的多模态AI应用生态。无论是科研机构还是企业开发者,都能通过开源社区获取先进的视觉语言模型能力,推动多模态智能在各行各业的创新应用。未来团队将继续优化模型性能,拓展应用场景,为AI技术的普惠化发展贡献力量。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







