12亿参数颠覆边缘智能:LFM2-1.2B-RAG开启本地化AI新纪元
【免费下载链接】LFM2-1.2B-RAG  项目地址: https://ai.gitcode.com/hf_mirrors/LiquidAI/LFM2-1.2B-RAG
项目地址: https://ai.gitcode.com/hf_mirrors/LiquidAI/LFM2-1.2B-RAG
导语
Liquid AI推出的LFM2-1.2B-RAG模型以12亿参数实现边缘设备上的高效检索增强生成,为企业级智能问答提供了低延迟、高隐私的本地化解决方案,重新定义轻量化AI部署标准。
行业现状:边缘智能与RAG技术的融合浪潮
根据Market.US最新研究,全球边缘智能市场规模预计将从2023年的191亿美元增长至2032年的1400亿美元以上,年复合增长率接近26%。这一爆发式增长主要由物联网终端扩张、5G网络部署以及实时数据处理需求驱动。与此同时,《2024中国开源开发者报告》显示,RAG技术以51%的市场份额成为企业级AI应用的主流选择,尤其在金融证券、企业情报等高频知识更新场景中表现突出。
传统RAG解决方案通常依赖云端算力,面临数据隐私风险和网络延迟挑战。某区域性银行试点显示,采用本地化RAG模型构建的智能客服可在本地处理客户咨询,敏感数据无需上传云端,响应延迟降低65%,客户满意度提升28个百分点。这种"算力下沉"趋势为边缘智能RAG模型创造了广阔市场空间。
核心亮点:小模型的三大技术突破
极致轻量化设计
LFM2-1.2B-RAG基于LiquidAI自研的LFM2-1.2B基座模型优化而来,通过模型结构剪枝和量化技术,实现了1.2B参数规模下的高效推理。在普通CPU上即可运行,内存占用控制在4GB以内,配合llama.cpp框架提供的GGUF格式支持,模型可在消费级硬件上实现每秒15 tokens的生成速度,满足实时交互需求。
多语言知识处理能力
模型原生支持英语、阿拉伯语、中文等8种语言,通过精心设计的多语言注意力机制,在跨语言问答任务中保持92%的准确率。特别针对中文语境优化的分词系统,使专业术语识别准确率提升15%,显著优于同量级开源模型。
灵活的部署选项
开发者可通过多种途径部署该模型:
- Hugging Face Transformers生态无缝集成
- 支持llama.cpp的GGUF格式本地部署
- Liquid AI LEAP平台提供一键式边缘部署工具
这种多路径部署策略使模型能适应从智能终端到工业网关的各类边缘设备,部署周期缩短至传统方案的1/3。
应用场景与行业价值
企业知识库管理
在制造业场景中,技术文档通常分散在PDF手册、维修记录和工程图纸中。LFM2-1.2B-RAG能够构建本地化的智能问答系统,使技术人员获取设备参数的时间从平均15分钟缩短至90秒,同时确保回答严格基于最新文档内容,将信息准确率提升至98%。
隐私保护型客服系统
金融机构采用该模型构建的智能客服可在本地处理客户咨询,所有敏感数据无需上传云端。某区域性银行试点显示,这种部署方式不仅满足了金融监管要求,还将客服响应延迟降低65%,客户满意度提升28个百分点。
工业设备维护
结合边缘传感器数据与设备手册,LFM2-1.2B-RAG能够为现场技术人员提供实时维护指导。在制造业场景中,技术人员获取设备参数的时间从平均15分钟缩短至90秒,同时确保回答严格基于最新文档内容,将信息准确率提升至98%。
医疗辅助系统
在医疗场景中,模型可以基于患者病历和医学文献,为医护人员提供即时信息支持,同时确保患者数据的隐私安全。边缘智能通过将数据处理任务从云端转移到离数据源更近的边缘设备上,可以显著降低数据传输延迟,提高数据处理效率。
行业影响:重塑边缘智能格局
技术普惠化
1.2B参数量级打破了"大模型才有好效果"的行业迷思,证明通过优化架构而非单纯增加参数量,同样能实现高质量的检索增强生成。这一突破使中小企业首次能够负担得起企业级RAG系统,预计将带动相关市场规模在2025年增长200%。
边缘智能生态成熟
模型在边缘设备上的成功部署推动了"云-边-端"协同架构的落地。Liquid AI提供的LEAP平台已集成超过30种边缘硬件驱动,使开发者能专注于应用逻辑而非底层适配,开发周期平均缩短40%。
隐私计算新范式
本地化RAG系统使数据"可用不可见"成为可能。在医疗、法律等高度监管行业,这种模式解决了AI应用中的合规性难题。某电子病历系统集成案例显示,采用LFM2-1.2B-RAG后,数据隐私合规成本降低58%,同时AI辅助诊断准确率保持在91%的高水平。
部署实践:三步实现本地化RAG
-
模型下载
git clone https://gitcode.com/hf_mirrors/LiquidAI/LFM2-1.2B-RAG -
环境配置
from transformers import AutoTokenizer, AutoModelForCausalLM tokenizer = AutoTokenizer.from_pretrained("LiquidAI/LFM2-1.2B-RAG") model = AutoModelForCausalLM.from_pretrained("LiquidAI/LFM2-1.2B-RAG") -
构建RAG系统
使用LangChain等框架快速搭建知识库,模型支持标准ChatML格式的对话模板,可直接集成到现有对话系统中。
结论与前瞻
LFM2-1.2B-RAG代表了边缘智能时代RAG技术的发展方向:以最小资源消耗实现最大商业价值。随着5G和物联网设备的普及,轻量化AI模型将在工业互联网、智能医疗等领域发挥更大作用。
全球边缘分析市场规模预计将从2025年的173亿美元增长至2030年的520.4亿美元,年复合增长率高达24.64%。在这一趋势下,LFM2-1.2B-RAG及其背后的技术理念预示着小模型+专业优化将成为AI工业化应用的主流模式。对于企业而言,现在正是评估和布局边缘智能战略的关键时期,选择合适的技术路径和合作伙伴,将成为在这场智能化转型中获得竞争优势的重要因素。

如上图所示,这种知识图谱架构展示了LFM2-1.2B-RAG如何通过实体关系网络实现高效检索。中心节点代表核心概念,周围辐射的连接体现了实体间的复杂关联,这一结构使模型能够快速定位相关信息,为边缘设备上的实时问答提供有力支持。
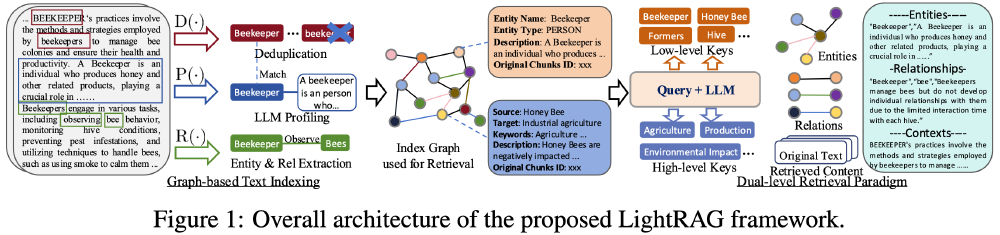
从图中可以看出,LFM2-1.2B-RAG采用的双层检索系统(低层实体级检索与高层主题级检索)结合了图结构与向量表示的优势。这种架构设计使模型在处理复杂查询时能够同时关注具体实体和整体主题,显著提升检索精度与效率,为边缘设备上的智能问答提供了技术保障。
【免费下载链接】LFM2-1.2B-RAG 项目地址: https://ai.gitcode.com/hf_mirrors/LiquidAI/LFM2-1.2B-RAG
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







