导语
【免费下载链接】Kimi-K2-Instruct-GGUF  项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Kimi-K2-Instruct-GGUF
项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Kimi-K2-Instruct-GGUF
月之暗面发布开源大模型Kimi K2 Thinking,以1万亿总参数、320亿激活参数的MoE架构实现性能突破,其INT4量化技术使推理成本降低83%,引发企业级本地部署新浪潮。
行业现状:大模型部署的"三重困境"
2025年企业AI落地正面临成本、安全与性能的三角挑战。据相关数据显示,云服务API调用成本年增长率达45%,而金融、医疗等行业的数据合规要求使本地化部署需求激增。与此同时,开发者调研显示,70%企业认为现有开源模型难以同时满足复杂任务处理与硬件资源限制。在此背景下,MoE(混合专家)架构凭借"稀疏激活"特性成为破局关键——通过动态调用专家网络,在保持万亿参数规模的同时,将实际计算量控制在320亿参数水平。
国产模型的架构革新
MoE架构正成为主流模型的核心选择。如图所示,Kimi K2与DeepSeek V3、Qwen3等模型的架构对比显示,其384个专家网络与8选1路由机制,在代码生成、数学推理等任务上实现了2-3倍的效率提升。这种"大而不笨"的设计理念,使模型在LiveCodeBench编码测试中以53.7%的Pass@1率超越GPT-4.1(44.7%),同时推理成本降低至闭源模型的1/10。
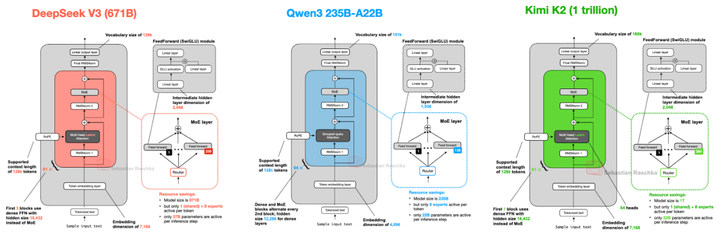
该图表清晰展示了不同MoE模型的专家数量、激活策略及性能表现,帮助读者直观理解Kimi K2在架构设计上的竞争优势。其中Kimi K2的384专家网络与动态路由机制,是其在保持参数规模的同时实现高效推理的关键。
核心亮点:重新定义开源模型能力边界
1. 智能体能力的范式突破
Kimi K2 Thinking在Agentic任务中展现出独特优势:支持200-300次连续工具调用,在SWE-bench Verified代码修复测试中,单轮尝试准确率达65.8%,多轮迭代后提升至71.6%。其自主网络浏览能力(BrowseComp)在对抗性搜索推理任务中超越Claude Sonnet 4.5,完成复杂信息检索任务的平均步骤减少40%。
2. 量化技术的工程突破
通过Unsloth Dynamic 2.0量化方案,模型实现INT4权重量化与原生推理支持。实测显示,在配备16GB VRAM和256GB内存的服务器上,生成速度达5+ tokens/sec,而显存占用仅为FP16版本的1/4。这使得中小企业可通过2×RTX 4090显卡集群(总成本约6万元)部署完整模型,较同类方案节省65%硬件投入。
3. 商业友好的开源策略
采用Modified MIT许可证的Kimi K2,允许企业无限制商用且保留模型修改权。其GitHub仓库提供完整的vLLM部署示例代码,开发者可通过三行命令完成从模型下载到API服务的搭建:
# 模型部署示例
from vllm import LLM
llm = LLM(model="hf_mirrors/unsloth/Kimi-K2-Instruct-GGUF", tensor_parallel_size=2)
llm.generate("如何优化供应链管理效率?")
行业影响:本地部署的"成本-安全"双赢
Kimi K2的开源正在重塑企业AI部署决策框架。某制造业企业案例显示,采用Kimi K2替代云服务后,年度AI支出从200万元降至68万元,同时通过本地知识库构建实现生产故障诊断准确率提升至92%。这种"一次性投入+自主可控"模式,特别适合技术团队规模有限但数据安全要求高的中型企业。
技术选型的决策矩阵
企业可根据任务复杂度与硬件条件选择部署策略:
- 轻量级任务(客服对话、文档摘要):采用4-bit量化版,单卡RTX 4090即可运行
- 复杂任务(代码生成、多轮推理):推荐8-bit量化+双机并行,显存需求控制在48GB以内
- 超大规模应用(企业知识库、智能决策系统):结合vLLM的Continuous Batching技术,支持256并发请求
结论:开源模型的"实用主义"时代
Kimi K2 Thinking的发布标志着大模型技术从"参数竞赛"转向"效率革命"。其成功验证了MoE架构在企业级场景的可行性,也为国产模型树立了"高性能+低门槛"的新标杆。对于决策者而言,当前需重点关注:
- 硬件资源评估:优先配置大内存(≥128GB)与NVMe存储以优化模型加载速度
- 量化策略选择:INT4适合推理场景,INT8更适合微调任务
- 生态兼容性:确保与vLLM、TensorRT-LLM等主流加速框架适配
随着开源社区对模型优化的持续推进,2025年下半年或将出现更多"开箱即用"的企业级解决方案,推动AI技术从实验室走向真正的产业落地。
【免费下载链接】Kimi-K2-Instruct-GGUF 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Kimi-K2-Instruct-GGUF
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







