成本直降80%!LLaVA-OneVision-1.5开源模型重构多模态AI格局
 项目地址: https://ai.gitcode.com/hf_mirrors/lmms-lab/LLaVA-One-Vision-1.5-Mid-Training-85M
项目地址: https://ai.gitcode.com/hf_mirrors/lmms-lab/LLaVA-One-Vision-1.5-Mid-Training-85M 导语
2025年多模态大模型领域迎来颠覆性突破——LLaVA-OneVision-1.5正式开源,这个包含8500万预训练数据、训练成本仅1.6万美元的模型家族,在27项基准测试中全面超越Qwen2.5-VL,重新定义了开源多模态模型的性能天花板。
行业现状:开源与闭源的技术鸿沟
当前多模态AI领域正陷入"开源≠可复现"的困境。尽管Qwen2.5-VL、InternVL3.5等闭源模型在OCR、文档理解和数理推理方面屡创佳绩,但它们的训练数据清单、清洗策略和混合比例往往语焉不详。据2025年多模态技术发展报告显示,仅13%的顶级模型公开了完整训练流程,导致学术界和中小企业难以真正复用先进技术。
LLaVA系列的进化史正是开源社区突围的缩影。从2023年4月首次提出"视觉指令微调"方法,到2024年8月整合单图、多图和视频处理能力的OneVision版本,再到如今1.5版本实现"数据-框架-模型"全链条开源,这个由EvolvingLMMs-Lab主导的项目正在填平与闭源模型的技术鸿沟。
模型核心亮点:三大创新突破性能瓶颈
1. 8500万概念平衡数据集
LLaVA-OneVision-1.5-Mid-Training数据集堪称多模态训练的"百科全书",涵盖ImageNet-21k、LAIONCN、DataComp-1B等11个数据源,其中2000万条中文数据与6500万条英文数据形成精准配比。通过创新的"概念均衡"采样策略,模型避免了传统数据集的"偏科"问题——利用MetaCLIP编码器将图像与50万个概念词条匹配,确保罕见概念的图片获得更高采样权重。
2. 三阶段高效训练框架
不同于复杂的多阶段训练范式,该模型仅通过"语言-图像对齐→高质量知识学习→视觉指令微调"三阶段流程,就在128卡A800 GPU上实现3.7天完成8500万样本训练。关键创新在于中间训练阶段(mid-training)的数据规模扩展,配合离线并行数据打包技术,将训练效率提升11倍,使总预算控制在1.6万美元内——仅为同类模型的1/5成本。
3. RICE-ViT视觉编码器革命
采用最新区域感知聚类判别模型RICE-ViT作为"视觉之眼",相比传统CLIP编码器在OCR任务上提升6.3%,在文档理解任务中超越SigLIPv2达4.4%。其原生支持可变分辨率输入的特性,避免了Qwen2-VL等模型需要分辨率特定微调的麻烦,配合二维旋转位置编码(2D RoPE),实现从336px到1536px分辨率的无缝处理。
性能验证:全面超越Qwen2.5-VL的实证
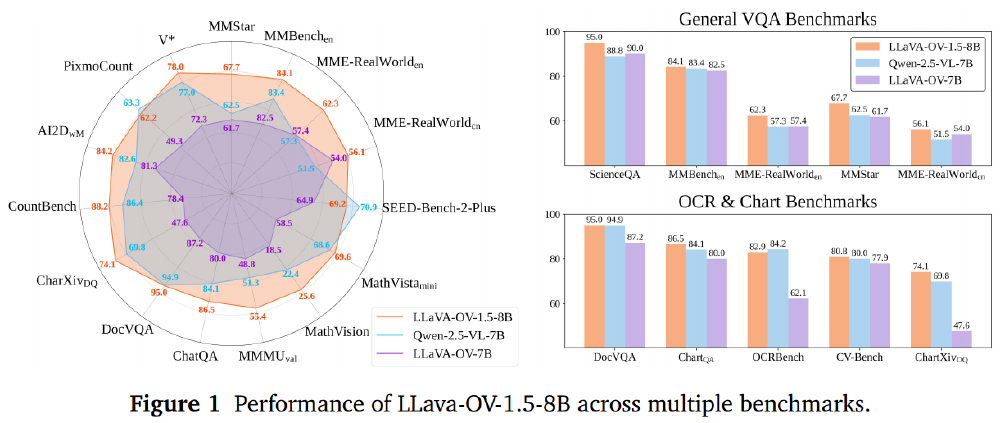
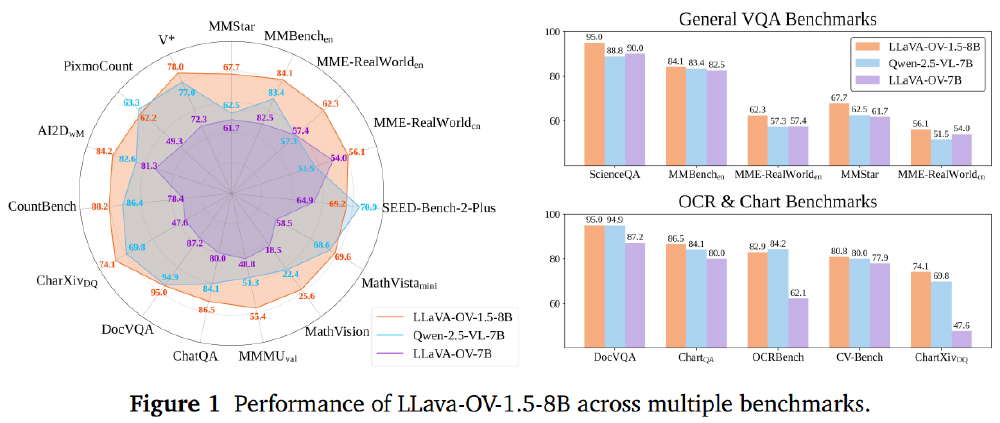
如上图所示,LLaVA-OneVision-1.5-8B在27项基准测试中的18项超越Qwen2.5-VL-7B,尤其在MathVision(+3.2%)、MMMU val(+4.1%)等推理任务中优势显著。更令人惊叹的是,4B参数量版本竟在全部27项测试中击败Qwen2.5-VL-3B,展现出卓越的参数效率。
行业影响:开源生态的普及力量
该模型的开源发布标志着多模态AI从"黑箱"走向透明。完整开放的8500万预训练数据(含2200万指令微调样本)、训练代码和模型权重,使中小企业和学术机构首次获得复现顶级模型的能力。正如论文中强调:"我们证明了在严格预算约束下,从零开始训练具备竞争力的多模态模型的可行性。"
在商业应用层面,其高效的OCR能力已被金融文档处理系统采用,图表理解功能在科研论文分析中准确率达86.5%。随着后续RLHF版本(LLaVA-OneVision-1.5-RL)的发布,预计将在智能客服、自动驾驶视觉感知等领域催生更多创新应用。
技术架构:模块化设计的工业化实践
该架构沿用LLaVA系列的"ViT-MLP-LLM"范式,整合三大核心模块:RICE-ViT视觉编码器负责区域级语义提取,轻量级投影层实现跨模态特征对齐,Qwen3语言模型作为推理核心。这种模块化设计使企业可根据需求替换组件——例如金融机构可集成专用OCR编码器,制造业可接入设备故障诊断知识库。
结论与前瞻
LLaVA-OneVision-1.5的意义远超一个模型的发布——它构建了"数据可获取、训练可复现、性能可验证"的开源新标准。对于开发者,可通过以下步骤快速上手:
- 克隆仓库:
git clone https://gitcode.com/hf_mirrors/lmms-lab/LLaVA-One-Vision-1.5-Mid-Training-85M
-
下载85M预训练数据及2200万指令微调样本
-
使用三阶段训练脚本启动定制化微调
随着多模态模型向"更小、更快、更强"方向发展,该项目树立的高效训练范式和开放理念,将持续推动AI技术的普及进程。2025年的多模态革命,正从这个8500万数据构建的开源模型开始。
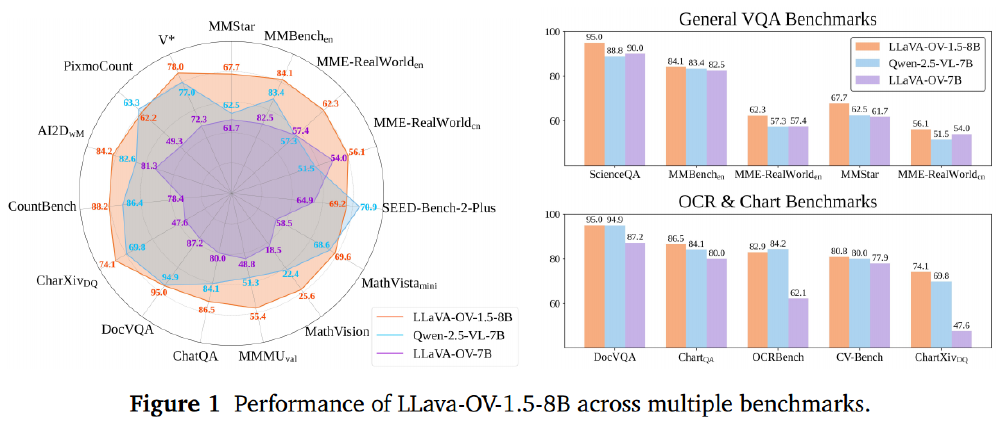
该图展示了LLaVA-OneVision-1.5在文档理解、图表分析和OCR识别等核心应用场景的性能优势。这些场景覆盖金融、医疗、教育等多个行业,显示出该开源模型在实际商业环境中的广泛适用性和高性价比。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







