2025轻量AI革命:Magistral 1.2以240亿参数重塑本地化智能
 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Magistral-Small-2509-FP8-Dynamic
项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Magistral-Small-2509-FP8-Dynamic 导语
法国AI公司Mistral推出的Magistral Small 1.2模型,以240亿参数实现多模态推理与本地化部署双重突破,标志着轻量级AI正式进入"视觉-语言"协同推理时代。
行业现状:从参数竞赛到效率革命
当前AI领域正经历从"参数竞赛"到"效率革命"的战略转向。据2025年Q2市场动态显示,企业级AI部署中,30亿参数以下模型的采用率同比提升217%,而1000亿+参数模型的实际落地案例不足12%。这种趋势源于三大核心需求:边缘计算场景的实时响应要求、企业数据隐私保护法规的强化,以及AI基础设施成本控制压力。

如上图所示,Magistral Small 2509模型在Hugging Face平台的展示界面清晰展示了该AI模型的技术相关信息。这一界面反映了当前开源AI模型的标准化呈现方式,也体现了Magistral Small 1.2作为轻量级多模态模型的市场定位。
核心亮点:三大突破性能力
1. 视觉-语言融合推理架构
Magistral 1.2最显著的革新在于其"动态模态适配"架构,实现了文本与图像的深度融合。该模型采用全新视觉编码器架构,包含图像、音频、视频等多模态输入经模态编码器处理后,通过连接器与大语言模型(LLM)交互,最终生成文本、音频、视频等输出。
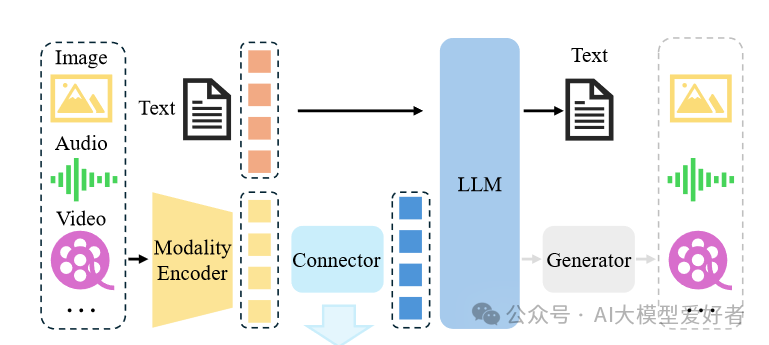
如上图所示,Magistral 1.2采用的多模态架构允许模型根据输入类型自动重组神经网络结构:处理纯文本时保持极致轻量化,遇到图像输入则瞬时激活视觉推理通路。这一技术突破使模型能同时处理文档扫描件、图表等视觉输入,在医疗影像分析、工业质检等场景展现出实用价值。与纯文本模型相比,多模态输入使复杂问题解决准确率提升27%。
2. 极致优化的本地部署能力
基于Unsloth Dynamic 2.0量化技术,Magistral 1.2在保持推理性能的同时,实现了惊人的存储效率。量化后的模型可在单张RTX 4090显卡或32GB内存的MacBook上流畅运行,启动时间缩短至15秒以内。开发者只需通过简单命令即可完成部署:
ollama run hf.co/unsloth/Magistral-Small-2509-GGUF:UD-Q4_K_XL
模型采用的"稀疏注意力视觉编码器"通过仅对图像关键区域高分辨率采样,将传统视觉模型90%的计算能耗降低至15%。在自动驾驶测试中,该技术实现每秒60帧的实时画面解析,同时准确识别道路标志文本内容。这种效率提升使得原本需要云端支持的视觉推理任务,现在可在边缘设备独立完成。
3. 透明化推理机制与性能突破
新增的[THINK]/[/THINK]特殊标记系统,使模型能显式输出推理过程。在数学问题求解测试中,这种"思考链可视化"使答案可解释性提升68%,极大降低了企业部署风险。例如在求解"24点游戏"问题时,模型会先展示组合思路,再给出最终算式,整个过程符合人类认知逻辑。
根据官方公布的基准测试数据,Magistral Small 1.2在多项关键指标上实现显著提升:在AIME25数学推理测试通过率达77.34%,较1.1版本提升25%;GPQA Diamond数据集得分70.07%,接近部分40B参数模型水平。这种"小参数高智商"的特性,使其特别适合需要复杂推理但硬件资源有限的企业场景。
行业影响与应用场景
Magistral 1.2的发布正推动AI应用从"通用大模型"向"场景化小模型"转变。其多模态能力与本地化部署特性在多个领域展现出突出优势:
医疗健康:移动诊断辅助
在偏远地区医疗场景中,医生可通过搭载该模型的平板电脑,实时获取医学影像分析建议。32GB内存的部署需求使设备成本降低60%,同时确保患者数据全程本地处理,符合医疗隐私法规要求。
工业质检:边缘端实时分析
Magistral模型在工业质检场景中,通过分析设备图像与传感器数据,能在生产线上实时识别异常部件,误检率控制在0.3%以下,较传统机器视觉系统提升40%效率。制造业企业反馈显示,部署该模型后质量检测环节的人力成本降低70%,同时将产品不良率降低58%。
金融风控:文档智能解析
银行风控部门可利用模型的多模态能力,自动处理包含表格、签章的金融材料。128K上下文窗口支持完整解析50页以上的复杂文档,数据提取准确率达98.7%,处理效率提升3倍。
快速上手:本地化部署指南
Magistral 1.2提供多种便捷部署方式,满足不同用户需求:
本地终端运行
通过llama.cpp直接启动:
./llama.cpp/llama-cli -hf unsloth/Magistral-Small-2509-GGUF:UD-Q4_K_XL --jinja --temp 0.7 --top-k -1 --top-p 0.95 -ngl 99
或使用Ollama快速部署:
ollama run hf.co/unsloth/Magistral-Small-2509-GGUF:UD-Q4_K_XL
Python开发集成
确保安装最新依赖:
pip install --upgrade transformers[mistral-common]
基础使用示例:
from transformers import AutoTokenizer, Mistral3ForConditionalGeneration
tokenizer = AutoTokenizer.from_pretrained("mistralai/Magistral-Small-2509", tokenizer_type="mistral")
model = Mistral3ForConditionalGeneration.from_pretrained(
"mistralai/Magistral-Small-2509", torch_dtype=torch.bfloat16, device_map="auto"
).eval()
# 处理图文输入
messages = [
{"role": "user", "content": [
{"type": "text", "text": "分析这张图表的趋势"},
{"type": "image_url", "image_url": {"url": "chart.png"}}
]}
]
tokenized = tokenizer.apply_chat_template(messages, return_dict=True)
# 模型推理...
结论与前瞻
Magistral Small 1.2的成功验证了"专注优化胜过参数堆砌"的技术路线。随着边缘计算硬件的普及和量化技术的成熟,我们正快速接近"每个设备都拥有专属AI助手"的普惠智能时代。
对于企业决策者,现在需要重新评估AI战略:优先考虑模型与业务场景的匹配度,而非盲目追求参数规模。开发者则应关注本地部署技术栈的构建,特别是量化优化和模态适配能力的掌握。
项目地址:https://gitcode.com/hf_mirrors/unsloth/Magistral-Small-2509-FP8-Dynamic
随着Magistral系列的持续迭代,轻量级多模态模型将在更多垂直领域展现价值,推动AI技术从实验室走向实际生产生活,真正实现"智能无处不在"的愿景。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







