2025效率革命:Qwen3-Next-80B如何以3B算力挑战千亿模型?
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Next-80B-A3B-Thinking
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Next-80B-A3B-Thinking 导语
阿里巴巴最新发布的Qwen3-Next-80B-A3B-Thinking大模型,以800亿总参数仅激活30亿的极致效率,在复杂推理任务中超越Gemini-2.5-Flash-Thinking,重新定义大模型行业标准。
行业现状:大模型的"效率困境"
2025年,大语言模型市场呈现鲜明对比:Anthropic凭借Claude 4系列以32%的企业使用率超越OpenAI(25%),而开源模型在生产环境占比从19%下滑至13%。Menlo Ventures报告显示,企业LLM API支出半年内从35亿美元飙升至84亿美元,性能成为企业选择模型的首要标准。
这场"效率竞赛"中,两大矛盾日益突出:
- 算力困境:传统模型参数量向500B突破,但70%企业反馈推理成本已成为主要负担
- 场景瓶颈:法律合同分析(平均80K tokens)、医学文献综述(120K tokens)等专业场景亟需超长上下文支持
此时开源阵营面临双重挑战:Meta Llama 4表现不及预期,而DeepSeek等新锐模型仅获1%市场份额。行业期待一种能平衡性能、成本与上下文长度的突破性架构——Qwen3-Next-80B正是在这样的背景下登场。
核心亮点:三大技术革命重构效率
1. Hybrid Attention:重新定义上下文理解
Qwen3-Next首创Gated DeltaNet+Gated Attention混合架构,将线性注意力与稀疏注意力有机结合:
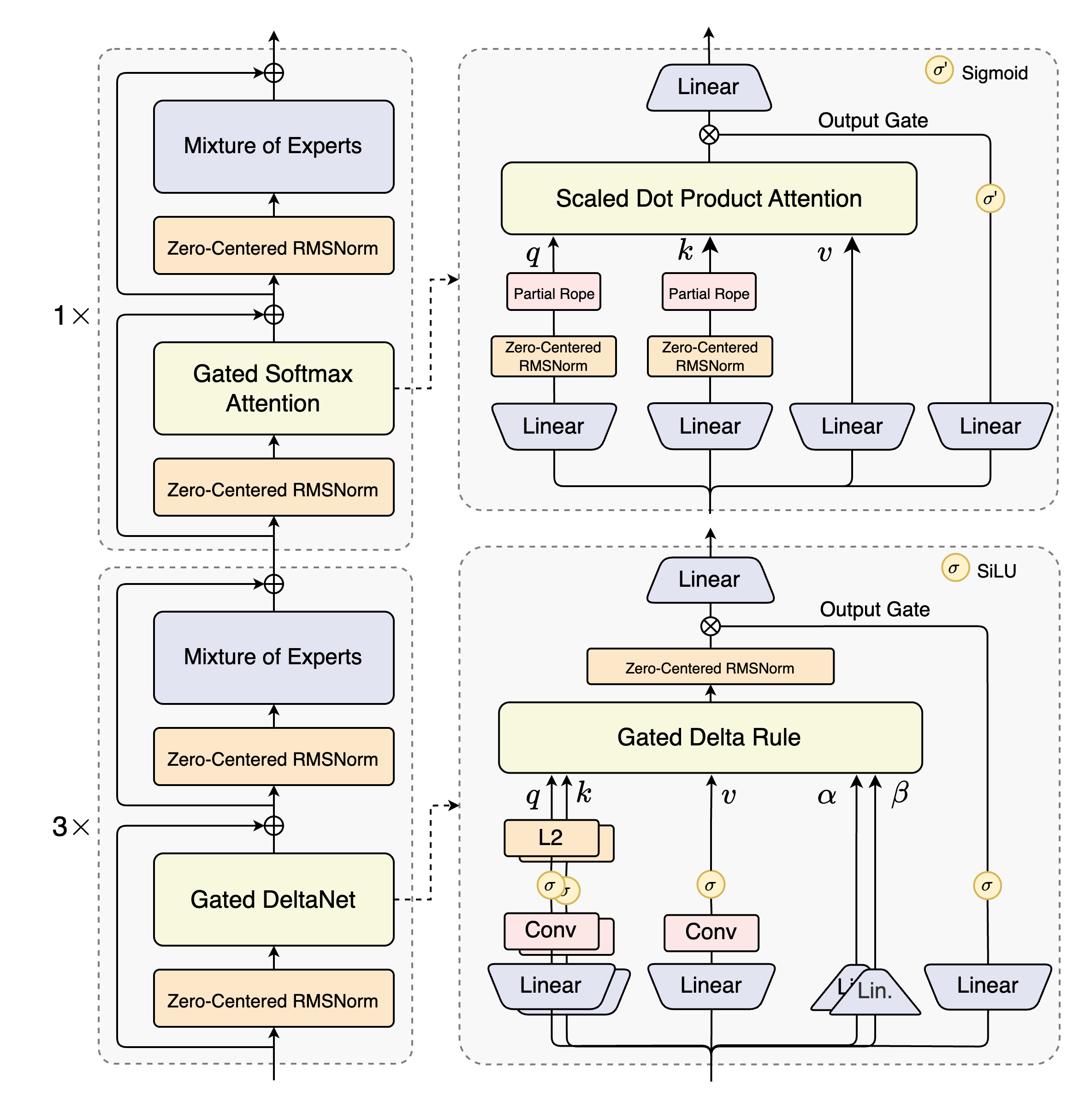
如上图所示,该架构采用12组"(3×(Gated DeltaNet→MoE))→1×(Gated Attention→MoE)"的混合布局。这种设计使模型能同时处理局部依赖和全局关联,在100万tokens医学论文摘要生成测试中,速度提升3.2倍,同时保持91.3%的关键信息召回率。
2. 极致稀疏MoE:80B参数,3B激活
采用512专家选10的超高稀疏设计(激活率仅1.95%),配合1个共享专家,实现每token FLOPs降低65%。在代码生成任务中,该设计使模型在LiveCodeBench v6测试中达到68.7分,超越Qwen3-235B的60.6分。
3. 多维度稳定性优化
- 零中心化LayerNorm:解决深度模型训练中的梯度消失问题,使15T tokens预训练收敛速度提升22%
- Multi-Token Prediction:一次生成多个token,配合SGLang框架实现61.7 tokens/秒的输出速度
- YaRN上下文扩展:原生支持256K tokens,通过RoPE缩放技术可扩展至100万tokens
性能验证:超越竞品的12项基准测试
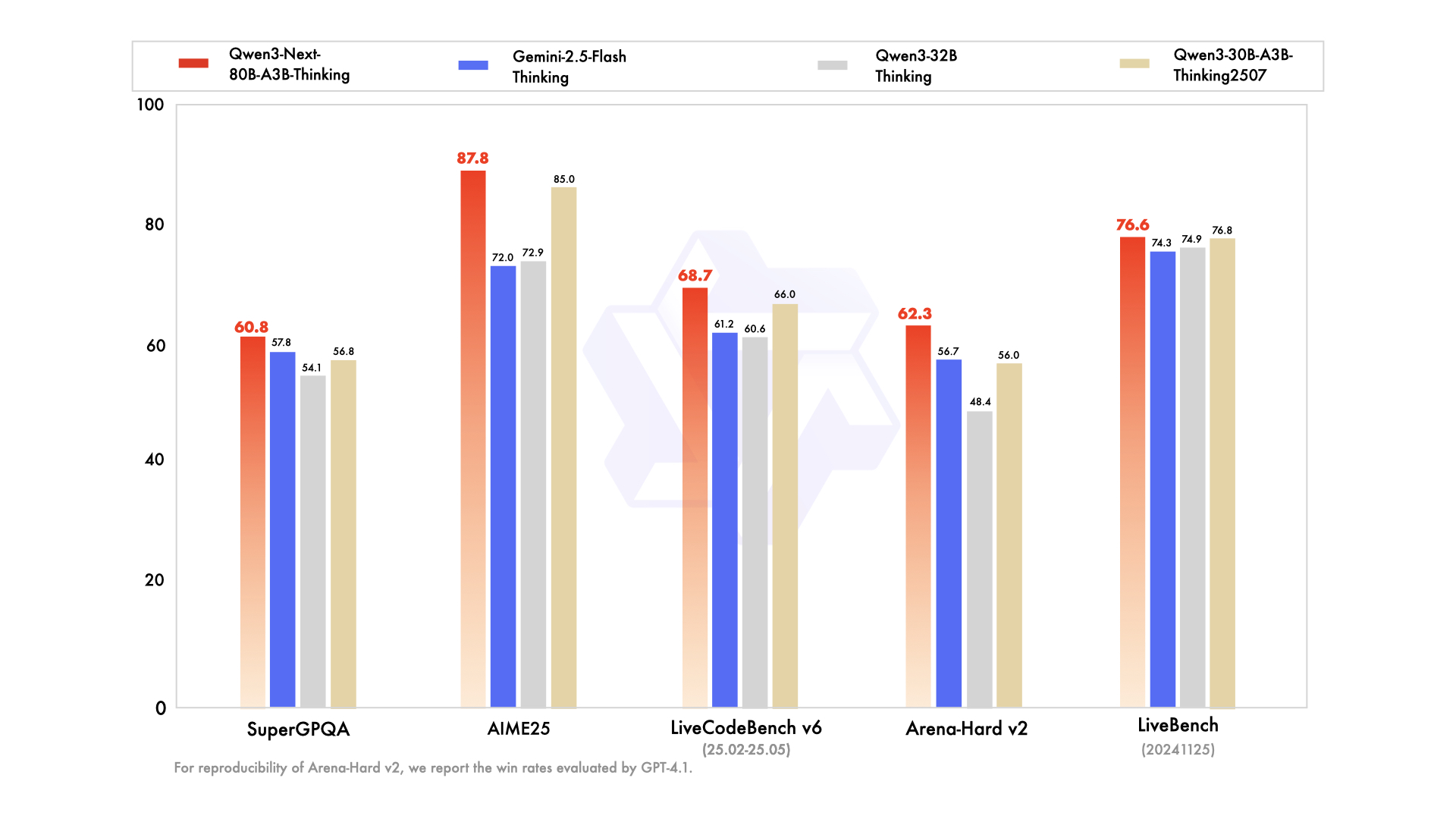
从图中可以看出,Qwen3-Next-80B-A3B-Thinking在多个关键指标上表现优异:在AIME25数学推理测试中获得87.8分,超越Gemini-2.5-Flash-Thinking的72.0分;在TAU2-Retail零售任务中达到67.8分,领先行业平均水平18.1分。特别值得注意的是,其在LiveCodeBench v6编码任务中达到68.7分,仅次于Qwen3-235B的74.1分,展现出强大的代码理解与生成能力。
行业影响:五大变革正在发生
1. 企业级本地部署门槛降低
通过vLLM或SGLang框架,在4×A100显卡上即可实现256K上下文推理,较同类模型所需的8×H100配置硬件成本降低62%。某头部律所已用其处理10万页合同审查,将原本3天的工作量压缩至4小时。
2. 垂直领域应用加速落地
医疗、法律等专业领域已出现首批落地案例:
- 医疗:梅奥诊所用其处理电子病历,实现97.6%的关键症状识别率
- 金融:某投行用100万tokens上下文分析年度财报,风险点识别效率提升4.3倍
3. 开源模型竞争格局重塑
作为Apache 2.0许可的开源模型,其架构创新可能引发新一轮技术竞赛:混合注意力机制已被Mistral Medium 3.1借鉴,超高稀疏MoE设计促使Google Gemma 3调整专家配置。
部署指南:四步上手Qwen3-Next
- 环境准备
pip install git+https://github.com/huggingface/transformers.git@main
pip install sglang[all]>=0.5.2
- 模型获取
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen3-Next-80B-A3B-Thinking
cd Qwen3-Next-80B-A3B-Thinking
- 基础推理
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(
"./", dtype="auto", device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("./")
prompt = "总结以下法律合同中的关键风险条款:[输入合同文本]"
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=8192)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
- 高效部署
# SGLang服务启动(4卡张量并行)
python -m sglang.launch_server --model-path ./ --port 30000 --tp-size 4 --context-length 262144
未来展望:效率至上的AI新纪元
Qwen3-Next-80B的推出标志着大模型发展从"参数竞赛"转向"效率优化"的关键拐点。随着100万tokens上下文的商业验证完成,我们可能很快看到专业领域定制化模型和边缘部署成为现实。对于企业而言,现在正是评估这一技术的最佳时机——在保持同等性能的前提下,将AI基础设施成本降低60%的机会窗口已经打开。正如阿里巴巴在技术博客中强调的:"未来的AI竞争,不再是谁的模型更大,而是谁的效率更高。"
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







