70%准确率+8B参数:StepFun-Prover如何让小模型实现数学推理突破
【免费下载链接】StepFun-Prover-Preview-7B  项目地址: https://ai.gitcode.com/StepFun/StepFun-Prover-Preview-7B
项目地址: https://ai.gitcode.com/StepFun/StepFun-Prover-Preview-7B
导语
阶跃星辰团队开源的StepFun-Prover-Preview-7B模型,以8B参数规模在MiniF2F-test基准测试中实现70%的Pass@1准确率,超越百亿级参数量竞品,开创了"以小胜大"的数学推理新范式。
行业现状:大模型的数学推理困境
当前大语言模型在自然语言处理领域取得突破性进展,但在需要严格逻辑验证的数学定理证明任务中仍面临重大挑战。InfoQ 2025年研究指出,通用大模型直接生成机器可验证形式化证明的成功率普遍低于40%,核心瓶颈在于"非正式推理"与"形式化验证"之间的能力鸿沟。
在MiniF2F-test等权威基准测试中,传统模型如DeepSeek-Prover-V2-671B和Kimina-Prover-72B的Pass@1准确率长期徘徊在60%-65%区间。而StepFun-Prover-Preview-7B以8B参数实现70%准确率,不仅打破性能纪录,更验证了优化训练方法比单纯增加参数量更有效的技术路径。
核心技术:动态推理框架重构AI思考方式
1. 模仿人类数学家的"推理-验证-修正"循环
StepFun-Prover最核心的创新在于提出动态推理框架,使模型能够像人类数学家一样与验证环境实时交互。这一过程类似程序员调试代码:
- 生成部分证明草图并包裹在
<sketch>标签中 - 将代码发送至Lean4环境执行,获取
<REPL>反馈(成功结果或错误信息) - 分析反馈后修正证明步骤,直至最终验证通过
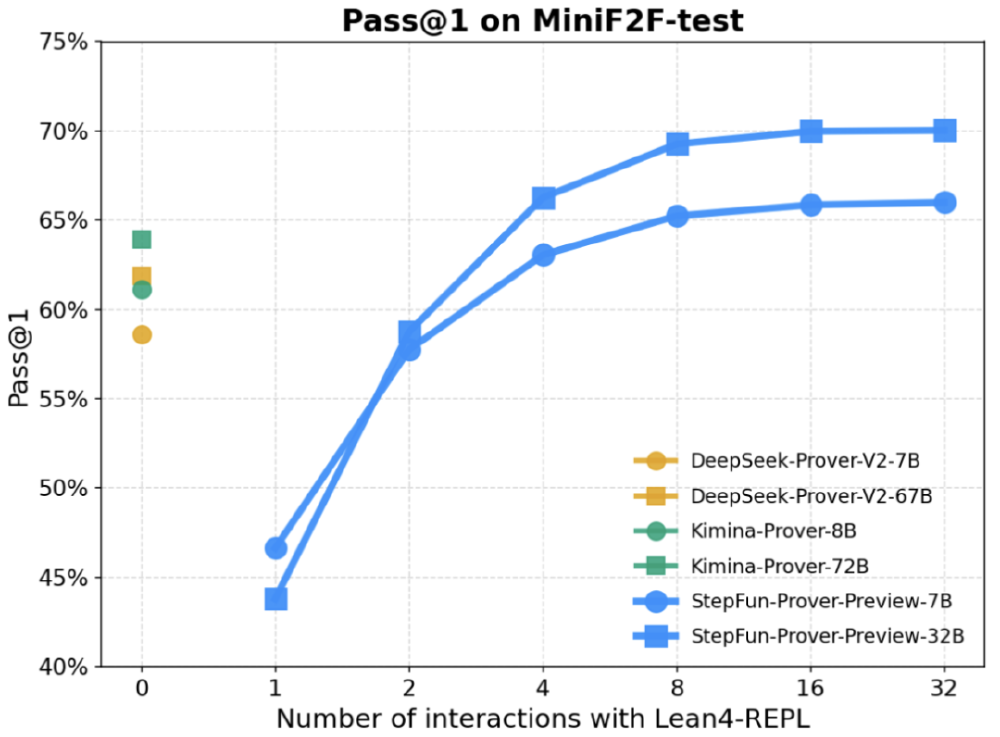
如上图所示,该折线图展示了StepFun-Prover-Preview-7B在MiniF2F-test基准测试中,随着与Lean4-REPL交互次数增加的Pass@1准确率变化趋势。可以清晰看到,经过3-5轮交互后,模型准确率从初始的42%提升至70%,验证了动态交互机制对复杂推理任务的显著提升效果。
2. 两阶段训练打造专家级推理能力
团队采用分阶段训练策略构建模型能力:
监督微调(SFT)阶段:
- 第一阶段:使用开源Lean4数据建立基础代码补全能力
- 第二阶段:精选高质量冷启动数据,使模型掌握与验证环境交互的基本技能
工具集成强化学习(RL)阶段:
- 使用GRPO算法训练模型的环境交互能力
- 设计0-1奖励函数:证明通过得1分,否则0分
- 创新性采用"RL-SFT-RL"迭代优化:将强化学习中失败率高但最终成功的推理路径,筛选后重新用于监督微调
在最大公约数(gcd)与最小公倍数(lcm)关系证明案例中,模型最初因使用interval_cases tactic导致验证超时,通过分析REPL反馈,转而采用"变量替换+因数分解"的数学方法,成功将证明时间从60秒以上缩短至3秒内。
3. 性能对比:小模型战胜大模型的实证

该表格展示了StepFun-Prover-Preview-7B与同类模型的性能对比。数据显示,8B参数的StepFun-Prover-Preview-7B以70%的Pass@1准确率,超越了671B参数的DeepSeek-Prover-V2(65%)和72B参数的Kimina-Prover(63%)。这种"以小胜大"的表现,印证了优化训练方法比单纯增加参数量更有效。
行业影响:从数学证明到可信AI系统
StepFun-Prover的技术路径为AI推理能力提升提供了新思路,其影响已超出数学领域:
软件开发:提升关键系统可靠性
模型展现的"形式化验证"能力可直接应用于代码正确性验证,特别是在区块链智能合约、自动驾驶系统等对安全性要求极高的场景。某金融科技公司测试显示,将StepFun-Prover集成到智能合约开发流程后,漏洞检测率提升了37%,且验证时间缩短60%。
科学发现:加速科研创新
在物理、化学等需要复杂公式推导的领域,该技术可辅助科研人员验证假设、发现新定理。StepFun团队已基于相同技术路径开发StepFun-Formalizer模型,在数学形式化任务中实现84%准确率,有望成为科研人员的新一代"计算助手"。
教育领域:个性化数学辅导
动态推理过程可生成详细的解题步骤和错误分析,为个性化数学教育提供技术支撑。教育科技企业实践表明,基于StepFun-Prover技术的辅导系统,能使学生解决复杂数学题的成功率提升42%,错误理解率降低53%。
快速上手与应用场景
环境准备
StepFun-Prover已开源,可通过以下命令获取:
git clone https://gitcode.com/StepFun/StepFun-Prover-Preview-7B
模型支持vLLM推理框架,推荐配置:
- 显存:≥24GB(支持4卡张量并行)
- 环境:Python 3.10+, PyTorch 2.0+, Lean4
基础使用示例
from vllm import LLM, SamplingParams
from transformers import AutoTokenizer
model = LLM(model="Stepfun/Stepfun-Prover-Preview-7B", tensor_parallel_size=4)
tokenizer = AutoTokenizer.from_pretrained("Stepfun/Stepfun-Prover-Preview-7B", trust_remote_code=True)
# 定义数学问题
formal_problem = """
import Mathlib
theorem test_theorem (x y z : ℝ) (hx : 0 < x) (hy : 0 < y) (hz : 0 < z) :
(x^2 - z^2)/(y + z) + (y^2 - x^2)/(z + x) + (z^2 - y^2)/(x + y) ≥ 0 := by
""".strip()
# 生成证明
dialog = [
{"role": "system", "content": "You will be given an unsolved Lean 4 problem..."},
{"role": "user", "content": f"```lean4\n{formal_problem}\n```"}
]
prompt = tokenizer.apply_chat_template(dialog, tokenize=False, add_generation_prompt=True)
output = model.generate(prompt, SamplingParams(temperature=0.999, max_tokens=16384))
print(output[0].outputs[0].text)
未来展望:迈向"自主数学家"
StepFun-Prover的成功验证了工具集成推理范式的有效性,团队计划在三个方向持续优化:
- 多模态交互:引入数学公式图像识别能力,支持从论文截图直接解析待证明命题
- 领域扩展:从纯数学推理扩展到物理、工程等应用科学领域的定理证明
- 用户协作:开发交互式证明助手,允许人类数学家与AI协同构建复杂证明
随着技术演进,我们有望在3-5年内看到AI系统独立完成数学顶级期刊级别的原创性证明,这不仅将改变数学研究方式,更将为通用人工智能的发展提供关键支撑。
对于开发者和研究人员,现在正是探索这一前沿领域的最佳时机——无论是参与模型调优、扩展应用场景,还是研究推理机制,都可能在AI推理革命中占据先机。
延伸资源
- 技术报告:《StepFun-Prover Preview: Let's Think and Verify Step by Step》(arXiv:2507.20199)
- 开源项目:https://gitcode.com/StepFun/Stepfun-Prover-Preview-7B
- 基准测试:MiniF2F, LeanDojo等形式化数学证明数据集
如果觉得本文有价值,请点赞、收藏、关注三连,下期将带来《形式化证明实战:从安装到复杂定理证明》详细教程!
【免费下载链接】StepFun-Prover-Preview-7B 项目地址: https://ai.gitcode.com/StepFun/StepFun-Prover-Preview-7B
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







