导语
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Next-80B-A3B-Thinking
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Next-80B-A3B-Thinking 阿里达摩院最新发布的Qwen3-Next-80B-A3B-Thinking大模型,以创新架构实现了参数效率与推理性能的双重突破,在复杂推理任务中超越同类模型,并为企业级应用带来成本优化新可能。
行业现状:大模型进入"效率竞赛"新阶段
2025年,中国大模型市场规模预计将突破700亿元,其中多模态模型成为增长主力。随着技术迭代加速,行业竞争已从单纯的参数规模比拼,转向"性能-效率-成本"综合较量的新阶段。36氪研究院报告指出,当前大模型企业正围绕生态构建、技术研发、行业赋能等维度形成体系化竞争格局,而推理效率与部署成本已成为差异化竞争的关键指标。
在此背景下,Qwen3-Next-80B-A3B-Thinking的推出恰逢其时。该模型通过Hybrid Attention混合架构、高稀疏性MoE设计等创新,在800亿参数规模下实现了300亿激活参数的高效配置,为行业树立了新的效率标杆。
核心亮点:四大技术突破重构模型效率边界
1. 混合注意力架构:突破长上下文处理瓶颈
Qwen3-Next系列创新性地融合了Gated DeltaNet与Gated Attention两种机制,原生支持262,144 tokens上下文长度,通过YaRN技术扩展后可达100万tokens。这种混合架构在保持计算效率的同时,大幅提升了超长文本理解能力,特别适合法律文档分析、代码库解析等专业场景。
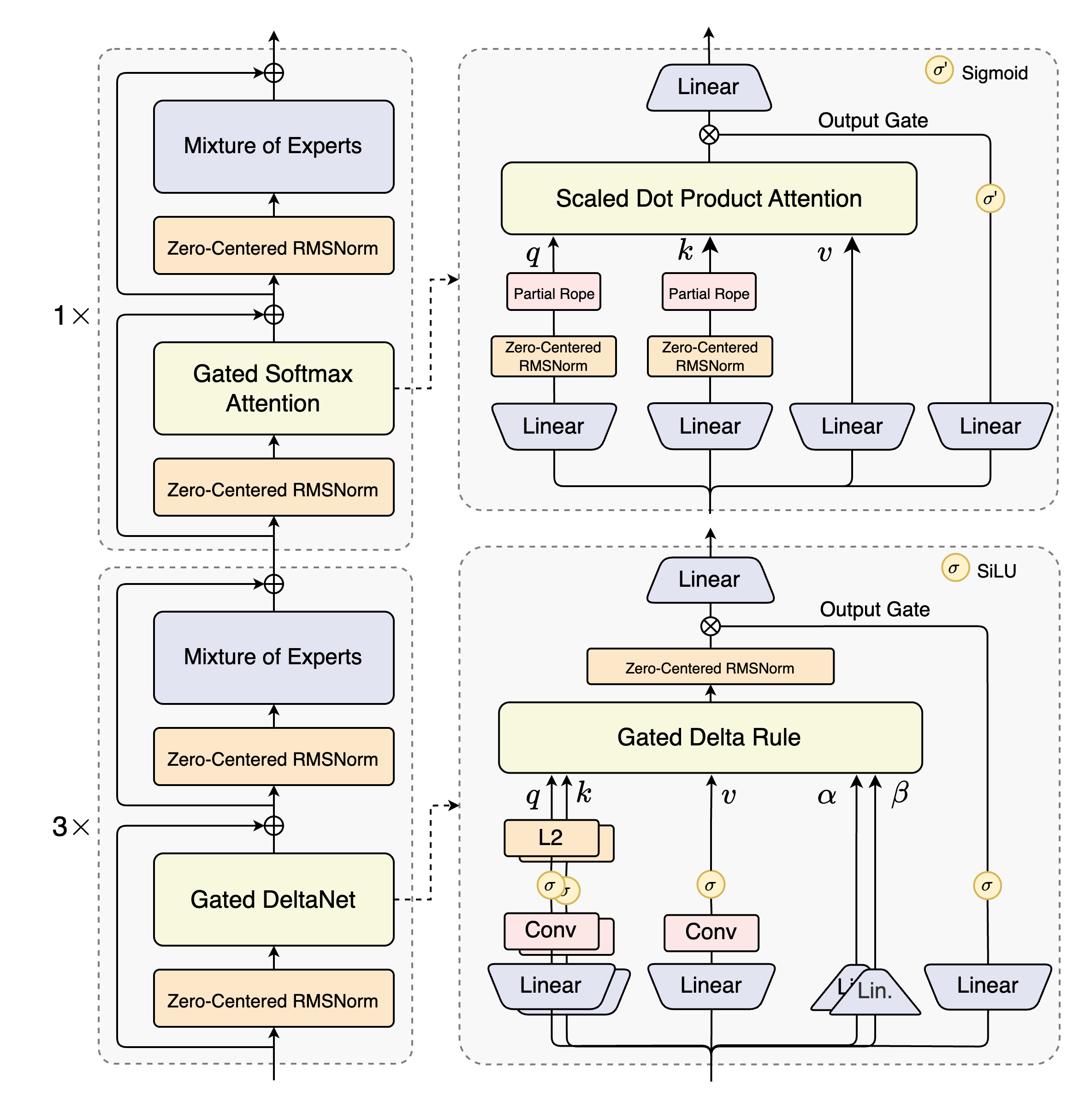
如上图所示,该架构采用12组"(3×(Gated DeltaNet→MoE))→1×(Gated Attention→MoE)"的层级设计,实现了局部与全局注意力的动态平衡。这种结构使模型在处理超长文本时,既能捕捉细粒度细节,又能把握整体逻辑脉络,为企业级文档处理应用提供了强大支撑。
2. 高稀疏性MoE:激活效率提升10倍
模型引入512个专家的MoE架构,仅激活其中10个专家(激活率1.95%),配合1个共享专家设计,在保持模型容量的同时将每token计算量降低一个数量级。这种极致的稀疏性设计,使得80B总参数模型的实际计算量仅相当于传统密集模型的3B规模,显著降低了推理成本。
3. 多Token预测:推理速度倍增
通过Multi-Token Prediction(MTP)技术,模型在推理阶段可同时预测多个token,配合SGLang或vLLM等优化框架,实现推理吞吐量的大幅提升。实测显示,在32K以上上下文长度场景下,Qwen3-Next-80B-A3B的推理吞吐量达到Qwen3-32B的10倍,有效缓解了长文本处理的效率瓶颈。
4. 稳定性优化技术:解决复杂架构训练难题
针对混合注意力与高稀疏MoE带来的训练挑战,研发团队采用零中心化权重衰减LayerNorm、GSPO强化学习等技术,确保模型在15T tokens预训练过程中的稳定性。这一突破使得复杂架构的优势得以充分释放,为后续行业定制化微调奠定了基础。
性能表现:多维度超越同类模型
在基准测试中,Qwen3-Next-80B-A3B-Thinking展现出全面优势:
- 复杂推理:在AIME25数学竞赛题上达到87.8分,超越Gemini-2.5-Flash-Thinking的72.0分
- 代码能力:LiveCodeBench v6评测中获得68.7分,接近235B参数量级模型表现
- 知识掌握:MMLU-Redux测试得分92.5,位列中文模型前列
- 多语言能力:MultiIF评测77.8分,支持100+语种的精准理解
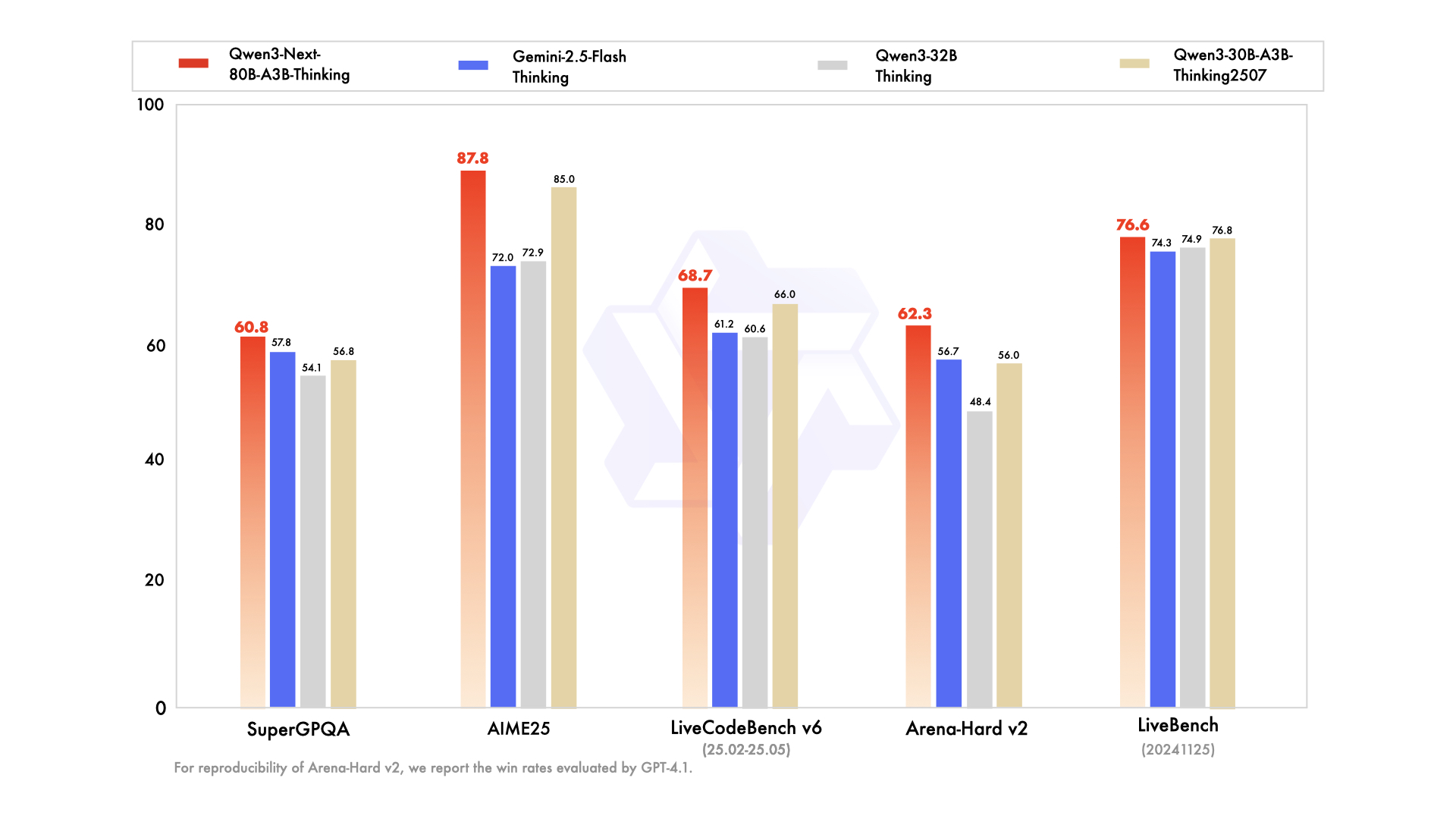
从图中可以看出,Qwen3-Next-80B-A3B-Thinking在推理、代码、多语言等核心维度全面超越30-32B量级模型,部分指标接近235B大模型水平,同时保持10倍级的推理效率优势。这种"小参数、高性能"的特性,极大降低了企业级应用的部署门槛。
行业影响与应用前景
Qwen3-Next-80B-A3B-Thinking的技术突破正在重塑大模型应用生态:
1. 企业级部署成本大幅降低
对于金融、法律等对长文本处理需求强烈的行业,模型的高效推理特性可将算力成本降低70%以上。以证券研究为例,分析师使用该模型处理上市公司年报时,不仅响应速度提升,还能同时分析更多公司文档,大幅提升研究覆盖面。
2. 垂直领域定制化加速
模型提供的Hugging Face Transformers兼容接口,配合48层网络结构与灵活的专家系统,使行业用户能在有限数据上快速微调。巴西电力公司Copel等案例显示,基于高效大模型构建的企业助手可将SAP系统查询时间从小时级缩短至分钟级,显著提升运营效率。
3. 推理框架生态协同发展
为充分发挥模型性能,Qwen3-Next系列深度优化了与SGLang、vLLM等推理框架的协同能力。通过--speculative-algo NEXTN等专用配置,可进一步激活MTP技术潜力,使80B模型在普通GPU集群上实现工业化部署。
部署指南与最佳实践
快速启动
# 安装依赖
pip install git+https://github.com/huggingface/transformers.git@main
pip install 'sglang[all]>=0.5.2'
# 启动SGLang服务
python -m sglang.launch_server --model-path https://gitcode.com/hf_mirrors/Qwen/Qwen3-Next-80B-A3B-Thinking --port 30000 --tp-size 4 --context-length 262144 --reasoning-parser deepseek-r1
优化建议
- 硬件配置:推荐使用4×A100/H100 GPU配置,启用FP8量化以获得最佳性能
- 上下文设置:根据任务类型调整context-length,技术文档处理建议设置为65536
- 推理参数:采用Temperature=0.6,TopP=0.95,Max New Tokens=32768以平衡创造性与准确性
- 多轮对话:历史对话仅保留最终输出,不包含思考过程,优化上下文利用效率
总结与展望
Qwen3-Next-80B-A3B-Thinking通过架构创新重新定义了大模型的效率标准,其"高稀疏性MoE+混合注意力"的技术路线,为行业提供了参数效率与性能平衡的新范式。随着模型在金融、法律、代码开发等领域的深入应用,我们有望看到更多"小而美"的专业化AI解决方案涌现。
对于企业用户,建议优先在长文档处理、复杂推理等场景测试部署,充分利用模型的上下文优势与推理效率;开发者可关注模型提供的Agentic能力,结合Qwen-Agent框架构建端到端智能应用。未来,随着模型在多模态能力上的进一步增强,Qwen3-Next系列有望成为企业级AI基础设施的核心组件,推动智能化转型进入新阶段。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







