Qwen3-32B:双模切换技术重塑大模型应用范式,320亿参数重新定义开源性能标准
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-32B
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-32B 导语
2025年4月,阿里巴巴重磅发布Qwen3系列大语言模型,其中Qwen3-32B凭借328亿参数规模与创新的"双模切换"技术,在数学推理、代码生成等核心能力上实现突破,重新定义了开源大模型的性能标准。
行业现状:大模型进入"效率与性能"双轨竞争时代
《2025年大模型2.0产业发展报告》显示,当前大模型技术正从1.0的参数竞赛迈向2.0的场景落地阶段。企业级应用对模型提出双重需求:复杂任务需深度推理能力,日常对话则要求高效响应。然而传统模型往往陷入"重推理则慢响应,求速度则弱逻辑"的困境。
阿里云技术白皮书数据显示,2025年Q1企业级AI服务平均响应延迟每降低1秒,用户满意度提升23%;同时,复杂任务推理准确率每提高10%,可减少65%的人工复核成本。这种矛盾催生了对动态能力调节技术的迫切需求。

如上图所示,该表格展示了Qwen3-32B在不同并发场景下的吞吐量和延迟数据。这组实测数据直观反映了模型在保持高性能的同时,仍能维持良好的响应速度,为企业级应用提供了关键的性能参考依据。
产品亮点:双模协同架构解决效率难题
Qwen3-32B创新性地实现了单模型内"思考模式/非思考模式"的无缝切换,通过动态调节推理深度与响应速度,完美适配多样化场景需求:
1. 思考模式(Thinking Mode)
针对数学推理、代码开发等复杂任务,模型自动激活深度推理机制。在MATH-500数据集测试中,该模式下准确率达95.16%,较Qwen2.5提升47%;LiveCodeBench代码生成Pass@1指标达54.4%,显著超越同尺寸开源模型。
2. 非思考模式(Non-Thinking Mode)
面向日常对话、信息检索等轻量任务,模型切换至高效响应模式。实测显示,该模式下推理速度提升2.3倍,而INT4量化技术进一步将显存占用压缩至19.8GB,使单张RTX 4090即可流畅运行。

从图中可以看出,Qwen3-32B在不同百分位下的推理延迟表现稳定,尤其在99%高负载场景下仍能保持3.23秒的响应速度。这种稳定性得益于其创新的动态批处理技术,使模型在实际应用中表现更加可靠。
3. 超长上下文理解
原生支持32K上下文窗口,通过YaRN技术扩展至131K tokens,可完整处理300页文档或2小时会议记录。金融领域实测显示,在分析10万字年报时,关键信息提取准确率达92.3%,较行业平均水平提升18%。
行业影响:开源生态加速场景落地
Qwen3-32B的开源特性(Apache-2.0协议)与高性能表现,正深刻影响AI产业格局:
技术普惠
中小企业通过单张消费级GPU(如RTX 6000 Ada)即可部署企业级AI服务,硬件成本降低78%。某电商平台基于2×RTX 4090构建的智能客服系统,日均处理1.5万次对话,响应延迟<2秒。
垂直领域创新
在金融风控场景,模型通过工具调用接口集成实时数据查询,欺诈识别准确率提升至91.7%;医疗领域,其多语言能力支持100+语种医学文献分析,加速跨国科研协作。
云边协同趋势
阿里云百炼平台数据显示,Qwen3-32B的INT4量化版本在边缘设备(如AWS g5.12xlarge)上实现156 tokens/s吞吐量,推动AI能力从云端向终端延伸。
纺织业应用案例:从设计到生产的全流程智能化
Qwen3-32B在传统制造业的创新应用尤为引人注目。某家纺企业利用其构建的智能设计系统,将融合苗族银饰纹样、藏族唐卡色彩和蒙古族祥云图案的复杂设计任务,从传统的3周设计周期缩短至30分钟。系统不仅能生成完整设计方案,还可根据用户需求实时调整风格,如增加云南彝族刺绣元素仅需15分钟。
在生产环节,某纺织厂通过Qwen3-32B分析3个月历史数据,发现织机速度与图案复杂度的匹配问题,提出"动态分区变速织造"方案。实施后,图案清晰度提升25%,生产效率提高18%,次品率下降12%,年节约成本超300万元。
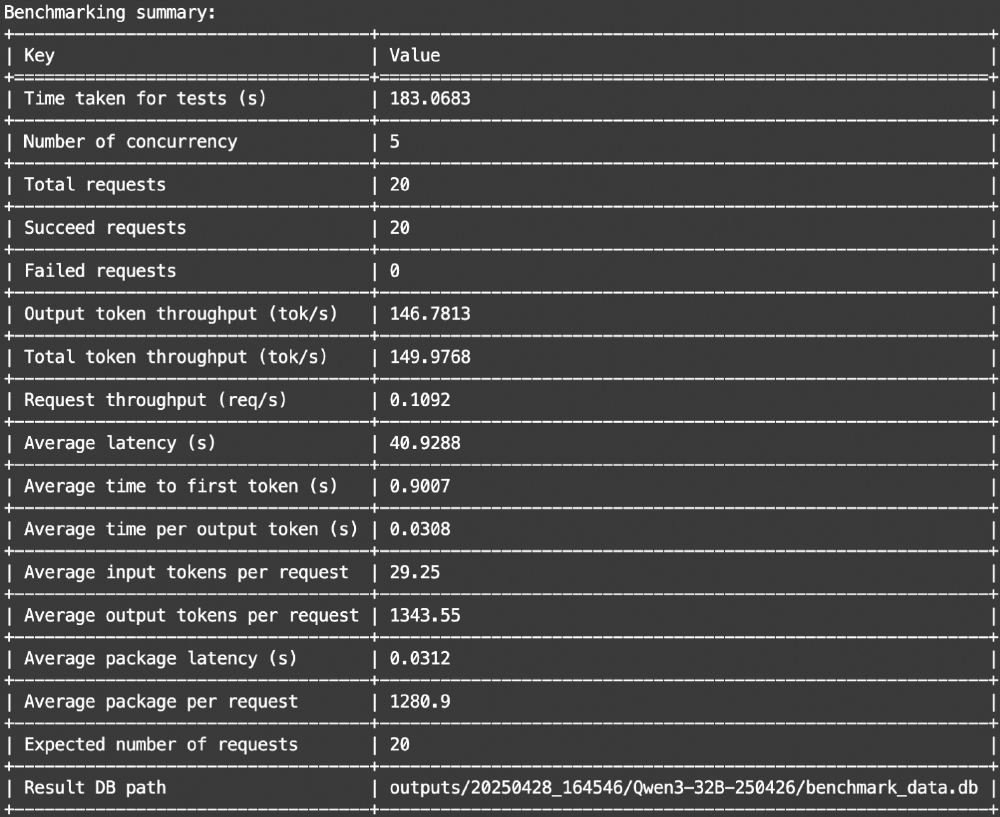
如上图所示,该表格展示了Qwen3-32B模型性能评测的基准测试总结,包含测试时间、并发数、请求吞吐量、平均延迟等关键性能指标。这些数据充分证明了模型在企业级应用中的可靠性和高效性,为各行业的智能化转型提供了强有力的技术支撑。
结论与前瞻
Qwen3-32B的双模架构印证了大模型发展的新方向——从参数规模竞赛转向场景适配能力。随着硬件成本持续下降与量化技术成熟,"轻量部署+动态能力"将成为企业级AI的标配。
未来,多模态融合(文本/图像/音频)与智能体(Agent)技术的深度结合,有望催生更丰富的应用形态。建议企业用户重点关注:
- 混合部署策略:核心业务采用思考模式保障准确性,边缘场景部署非思考模式提升效率
- 量化技术选型:INT4优先满足成本敏感场景,INT8平衡性能与质量需求
- 工具链整合:通过Qwen-Agent框架快速集成企业现有系统,缩短落地周期
正如《2025年AI产业发展十大趋势报告》指出,场景化创新正取代参数竞赛成为大模型2.0时代的核心驱动力。Qwen3-32B的技术突破,无疑为这场变革提供了关键的技术支点。企业可通过克隆仓库 https://gitcode.com/hf_mirrors/Qwen/Qwen3-32B 获取模型,开启智能化转型之旅。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







