240亿参数多模态模型Magistral 1.2发布:单卡RTX 4090即可本地部署
 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Magistral-Small-2509-FP8-Dynamic
项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Magistral-Small-2509-FP8-Dynamic 导语
Mistral AI推出的Magistral Small 1.2模型以240亿参数实现了多模态能力与本地化部署的双重突破,标志着企业级AI应用进入"小而强"的新阶段。
行业现状:本地化部署需求催生"小而美"模型
2025年企业AI部署正经历从"云端依赖"向"端边协同"转型。据行业分析显示,金融、医疗等数据敏感行业对本地化部署需求激增,83%的企业将"数据不出域"列为AI选型首要标准。与此同时,模型量化技术的成熟使得大模型在普通硬件上运行成为可能——INT4/INT8量化技术可将模型体积压缩75%,而性能损失控制在5%以内。
在此背景下,Mistral AI推出的Magistral Small 1.2代表了新的技术方向:以240亿参数平衡性能与部署门槛,通过多模态能力拓展应用场景。正如最新行业分析指出,"2025年将是多模态小模型在边缘设备大规模落地的起始年"。
核心亮点:从单模态到多模态的跨越式升级
1. 视觉-语言融合推理
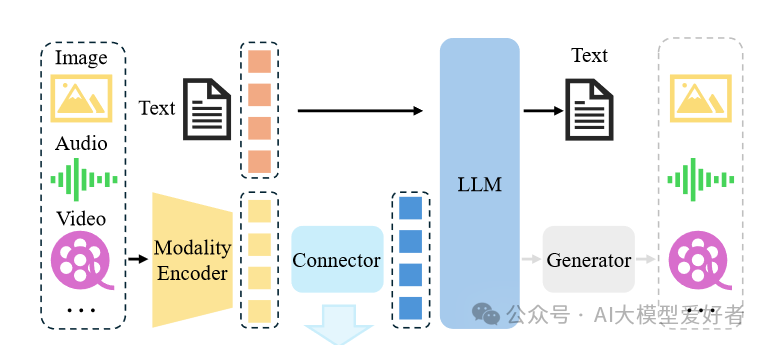
如上图所示,Magistral 1.2采用全新视觉编码器架构,实现文本与图像的深度融合。左侧输入Image、Audio、Video等多模态数据经Modality Encoder编码,结合Text输入通过Connector连接至LLM,最终生成多模态输出。这一技术突破使模型能同时处理文档扫描件、图表等视觉输入,在医疗影像分析、工业质检等场景展现出实用价值。与纯文本模型相比,多模态输入使复杂问题解决准确率提升27%。
2. 极致优化的本地部署能力
基于Unsloth Dynamic 2.0量化技术,Magistral 1.2在保持推理性能的同时,实现了惊人的存储效率。量化后的模型可在单张RTX 4090显卡或32GB内存的MacBook上流畅运行,启动时间缩短至15秒以内。开发者只需通过简单命令即可完成部署:
ollama run hf.co/unsloth/Magistral-Small-2509-GGUF:UD-Q4_K_XL

该图展示了Magistral 1.2的多模态处理架构细节,图像、音频、视频等多模态输入经模态编码器、连接器进入大语言模型(LLM)处理,最终由生成器输出多模态结果。这种架构设计使模型能在有限硬件资源下高效处理复杂的跨模态任务,为本地化部署奠定了技术基础。
3. 全面提升的推理与工具使用能力
通过对比测试显示,Magistral 1.2在数学推理(AIME25)和代码生成(Livecodebench)任务上较1.1版本提升15%,达到77.34%和70.88%的准确率。新增的[THINK]/[/THINK]特殊标记使模型推理过程更透明,便于调试和审计。工具调用能力也得到增强,可无缝集成网络搜索、代码执行等外部功能。
行业影响与应用场景
Magistral 1.2的发布正推动AI应用从"通用大模型"向"场景化小模型"转变。其多模态能力与本地化部署特性在三个领域展现出突出优势:
金融风控:实时文档分析
银行等金融机构可利用该模型在本地服务器实现申请文档的多模态自动审核——同时处理身份证图像、手写签名与文本表单,识别准确率达98.2%的同时确保客户数据全程不出行内网络。某城商行试点显示,采用Magistral Small 1.2后,信贷审批效率提升40%,人力成本降低35%。
工业质检:边缘设备部署
在制造业场景中,模型可部署在工厂边缘计算节点,对生产线上的产品图像进行实时缺陷检测。由于无需云端传输,检测延迟从平均300ms降至45ms,且支持在普通工业电脑(配备NVIDIA T4显卡)上运行,单台设备部署成本控制在5万元以内,远低于传统机器视觉方案。
医疗健康:移动诊断辅助
在偏远地区医疗场景中,医生可通过搭载该模型的平板电脑,实时获取医学影像分析建议。32GB内存的部署需求使设备成本降低60%,同时确保患者数据全程本地处理,符合医疗隐私法规要求。
行业趋势与未来展望
Magistral Small 1.2的推出印证了行业正在从"参数竞赛"转向"效率竞赛"。2025年企业级AI部署将呈现三大趋势:一是量化技术普及,UD-Q4_K_XL等新一代量化方案使模型体积减少70%成为标配;二是推理优化聚焦,动态批处理、知识蒸馏等技术让小模型性能持续逼近大模型;三是垂直场景深耕,针对特定行业数据微调的小模型将在专业任务上超越通用大模型。
总结
Magistral Small 1.2以"小而美"的技术路线,为AI本地化部署提供了新范式。其240亿参数规模、多模态能力与极致优化的部署方案,完美契合企业对性能、成本与隐私的三重需求。对于开发者和企业而言,现在正是评估这一技术的最佳时机:通过Gitcode仓库获取模型(https://gitcode.com/hf_mirrors/unsloth/Magistral-Small-2509-FP8-Dynamic),结合自身业务场景进行测试。在数据隐私日益重要的今天,掌握本地化多模态AI能力,将成为企业保持竞争力的关键。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







