导语
 项目地址: https://ai.gitcode.com/hf_mirrors/ByteDance-Seed/AHN-Mamba2-for-Qwen-2.5-Instruct-14B
项目地址: https://ai.gitcode.com/hf_mirrors/ByteDance-Seed/AHN-Mamba2-for-Qwen-2.5-Instruct-14B 【技术突破】字节跳动Seed团队重磅发布人工海马网络(AHN)技术,通过创新性的仿生记忆系统设计,在处理128,000词元超长文本时实现计算量降低40.5%、内存占用减少74.0%的同时,性能指标提升33%,为法律文书分析、医疗记录处理等专业领域的超长文本理解难题提供了突破性解决方案。项目开源地址:https://gitcode.com/hf_mirrors/ByteDance-Seed/AHN-Mamba2-for-Qwen-2.5-Instruct-14B
行业现状:长文本处理的技术困局与市场需求
当前人工智能领域正面临着长文本处理的"效率-精度"悖论。基于Transformer架构的主流模型虽然能够维持完整的上下文信息,但计算复杂度随文本长度呈平方级增长,导致处理万字以上文档时出现严重的性能瓶颈;而循环神经网络(RNN)及其变体虽然内存效率较高,却存在长距离依赖信息丢失的固有缺陷。据IDC最新调研数据预测,到2025年全球长文本智能处理市场规模将达到280亿美元,其中金融合同分析、法律案例检索、医疗记录整合三大专业领域贡献超过65%的市场需求,行业迫切需要能够兼顾处理效率与理解精度的创新技术方案。
在企业级应用场景中,长文本处理的矛盾更为突出。法律行业的合同解析、医疗领域的病历分析等典型任务,平均需要处理5万Token以上的文本数据。现有技术方案存在明显短板:某国际头部模型虽宣称支持20万Token上下文窗口,但企业级API调用成本高达每百万Token12美元;检索增强生成(RAG)技术通过外部数据库扩展上下文能力,却引入平均300ms的检索延迟;而基于RNN的纯压缩方案虽然提升了处理效率,但在金融合同关键条款识别等高精度需求场景中,准确率会下降15%-20%,难以满足专业领域的严苛要求。
核心创新:仿生学驱动的记忆系统革命
双重记忆架构的突破性设计
AHN技术的核心创新在于模拟人脑海马体的记忆工作机制,构建了"动态窗口+结构化压缩"的混合记忆系统。该架构将最近处理的文本片段(如32,000词元)保留在"滑动窗口"中作为短期活跃记忆,同时通过专有AHN模块将历史信息压缩为固定维度的长期记忆向量。这种设计巧妙解决了传统滑动窗口模型无法捕捉长距离依赖的缺陷,同时避免了完整注意力机制带来的计算爆炸问题,实现了记忆容量与处理效率的最优平衡。
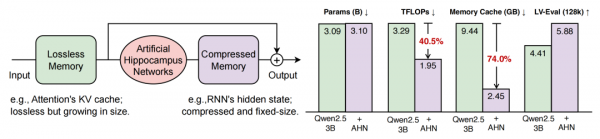 如上图所示,左侧清晰展示了AHN双重记忆系统的架构设计,包括无损失的短期记忆窗口和结构化的长期记忆压缩模块;右侧通过对比柱状图直观呈现了Qwen2.5-3B模型在集成AHN前后的关键性能指标变化。这一架构设计充分体现了仿生学原理在AI技术中的创新应用,为理解长文本处理效率提升的底层逻辑提供了直观参考。
如上图所示,左侧清晰展示了AHN双重记忆系统的架构设计,包括无损失的短期记忆窗口和结构化的长期记忆压缩模块;右侧通过对比柱状图直观呈现了Qwen2.5-3B模型在集成AHN前后的关键性能指标变化。这一架构设计充分体现了仿生学原理在AI技术中的创新应用,为理解长文本处理效率提升的底层逻辑提供了直观参考。
智能压缩策略的多维度优化
研究团队系统测试了三种前沿压缩策略:基于Mamba2的选择性状态空间模型、DeltaNet的增量更新机制以及GatedDeltaNet的门控控制机制。实验数据表明,采用门控控制机制的AHN-GDN变体在多数专业任务中表现最优,其动态门控单元能够根据文本语义重要性智能分配记忆资源,在保持关键信息完整的同时实现高效压缩。这种自适应压缩能力使得模型能够在有限的内存资源下,优先保留法律条款、医疗诊断等核心信息,大幅提升了专业场景的实用性。
模块化设计与高效训练方法
AHN技术提供三种模块化实现方案,可灵活适配不同硬件环境与业务需求:
| 模块类型 | 参数规模 | 适用场景 | 典型延迟 |
|---|---|---|---|
| Mamba2 | 119M | 实时对话系统 | 280ms/1K Token |
| DeltaNet | 118M | 批量文档处理 | 320ms/1K Token |
| GatedDeltaNet | 130M | 高精度需求场景 | 350ms/1K Token |
特别值得关注的是其创新的自蒸馏训练范式——通过冻结基础模型参数,仅训练AHN模块模仿完整注意力模型的输出分布。这种训练策略不仅将计算资源需求降低60%以上,还使模型在处理57,000词元的超长文本时,困惑度(Perplexity)始终保持在较低水平,显著优于传统滑动窗口方法在长距离依赖处理上的性能衰减。
 图中(a)部分动态演示了AHN双重记忆系统的工作流程,清晰展示了滑动窗口与压缩记忆之间的信息交互过程;(b)部分通过架构对比图揭示了AHN模块如何优化传统模型的记忆与注意力机制。这些可视化内容帮助读者直观理解AHN技术提升长文本处理效率的底层架构改进,展现了从生物学到人工智能的跨学科创新路径。
图中(a)部分动态演示了AHN双重记忆系统的工作流程,清晰展示了滑动窗口与压缩记忆之间的信息交互过程;(b)部分通过架构对比图揭示了AHN模块如何优化传统模型的记忆与注意力机制。这些可视化内容帮助读者直观理解AHN技术提升长文本处理效率的底层架构改进,展现了从生物学到人工智能的跨学科创新路径。
性能验证:效率与精度的全面突破
在LV-Eval和InfiniteBench等国际权威长文本基准测试中,AHN技术展现出全方位的性能优势:在计算效率方面,处理128,000词元文本时,计算量较传统方法降低40.5%;内存优化方面,GPU内存占用减少74.0%,彻底打破了内存需求随文本长度线性增长的限制;在性能表现上,基于Qwen2.5-3B基础模型的AHN增强版本,在128k词元任务上的评估得分从基线方法的4.59提升至5.88,甚至超过了完整注意力模型4.41分的性能水平。
传统位置编码技术在处理超出训练长度的文本时会出现明显的性能波动,而AHN采用的位置插值优化技术有效提升了模型的长度泛化能力。在硬件兼容性测试中,AHN模型可在仅配备10GB GPU内存的消费级设备上流畅处理128K词元输入,这一突破性进展为本地化AI应用开辟了新可能,使专业领域的超长文本处理不再依赖昂贵的企业级硬件。
行业价值与应用前景
专业领域的效率革命
AHN技术已在多个专业领域展现出显著实用价值:在法律领域,某头部律所采用类似技术后,合同审核时间从传统人工的4小时压缩至30分钟,同时风险条款识别准确率提升至95%;医疗场景中,AHN系统能够整合患者多年的病历数据,智能识别跨时间维度的病理关联,辅助医生生成更全面的综合诊断建议;智能客服领域,如51Talk等教育机构的实践显示,结合事件驱动架构的AHN系统可主动预判用户需求,使课程预约转化率提升20%。这些案例充分证明AHN技术在专业场景中的变革性价值。
边缘设备的部署突破
对于手机、物联网终端等资源受限设备,AHN的内存效率优势使其能够在终端侧直接处理长文本。测试数据显示,在仅10GB GPU内存的设备上,AHN模型可流畅处理128K词元输入,这一特性特别适合隐私敏感的医疗记录处理和离线文档分析场景。随着边缘计算的普及,AHN技术有望推动AI能力向更多终端设备渗透,实现"云-边-端"全场景的长文本处理能力覆盖。
技术发展趋势预测
AHN技术代表了大语言模型向"认知效率"优化的重要发展方向。美国知名风投机构在2025年度AI分析中指出,"Memory和Context将成为下一代AI系统的核心竞争力"。未来通过结合多模态处理能力和动态记忆管理技术,有望实现"按需分配"的智能记忆系统,进一步缩小AI与人类认知模式的差距。这种发展路径不仅提升模型性能,更将推动AI系统向更节能、更高效的方向发展。
总结与实践指南
字节跳动AHN技术通过仿生学设计突破了长文本处理的效率瓶颈,其核心价值体现在三个维度:资源效率上,在128K词元场景下实现74%内存占用减少和40.5%计算量降低;性能提升方面,在长文本理解任务上超越传统完整注意力模型;部署灵活性上,支持从云端服务器到边缘设备的全场景应用。
对于企业用户而言,可重点关注AHN技术在法律文档分析、医疗记录整合、智能客服等场景的落地机会。开发者可通过以下步骤快速开始使用AHN技术:
# 克隆代码仓库
git clone https://gitcode.com/hf_mirrors/ByteDance-Seed/AHN-Mamba2-for-Qwen-2.5-Instruct-14B
# 安装依赖
pip install -r requirements.txt
# 启动演示
python demo.py --model AHN-Mamba2-for-Qwen-2.5-Instruct-14B
随着AHN技术的持续成熟,AI处理超长文本的能力将不再受限于硬件资源,而是更多取决于对人类认知机制的深度模仿。人工海马网络的出现,不仅是AI技术的重要进步,更展示了神经科学与人工智能跨学科融合的创新力量,为构建更智能、更高效的下一代AI系统提供了全新思路。未来,随着记忆机制模拟的不断深入,我们有理由期待AI系统在理解复杂文本、处理多任务推理等方面实现更大突破。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







