导语
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Next-80B-A3B-Instruct-FP8
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Next-80B-A3B-Instruct-FP8 阿里通义千问团队推出的Qwen3-Next-80B-A3B-Instruct-FP8模型,通过Hybrid Attention架构与FP8量化技术的深度融合,在80B参数规模下实现了262K上下文长度与行业领先的推理效率,重新定义了企业级大模型部署的成本效益平衡点。
行业现状:大模型发展的"效率拐点"
2025年,大语言模型行业正经历从"参数竞赛"向"效率优先"的战略转型。据Gartner最新报告,全球企业AI部署成本中,算力支出占比已从2023年的35%飙升至58%,而模型效率每提升1%可为企业年均节省120万美元运维成本。在此背景下,Qwen3-Next系列的推出恰逢其时——其采用的混合注意力机制(Gated DeltaNet+Gated Attention)与高稀疏MoE架构,使80B模型在保持90.9% MMLU-Redux得分的同时,将推理吞吐量提升10倍,直接回应了企业对"高性能+低成本"的核心诉求。
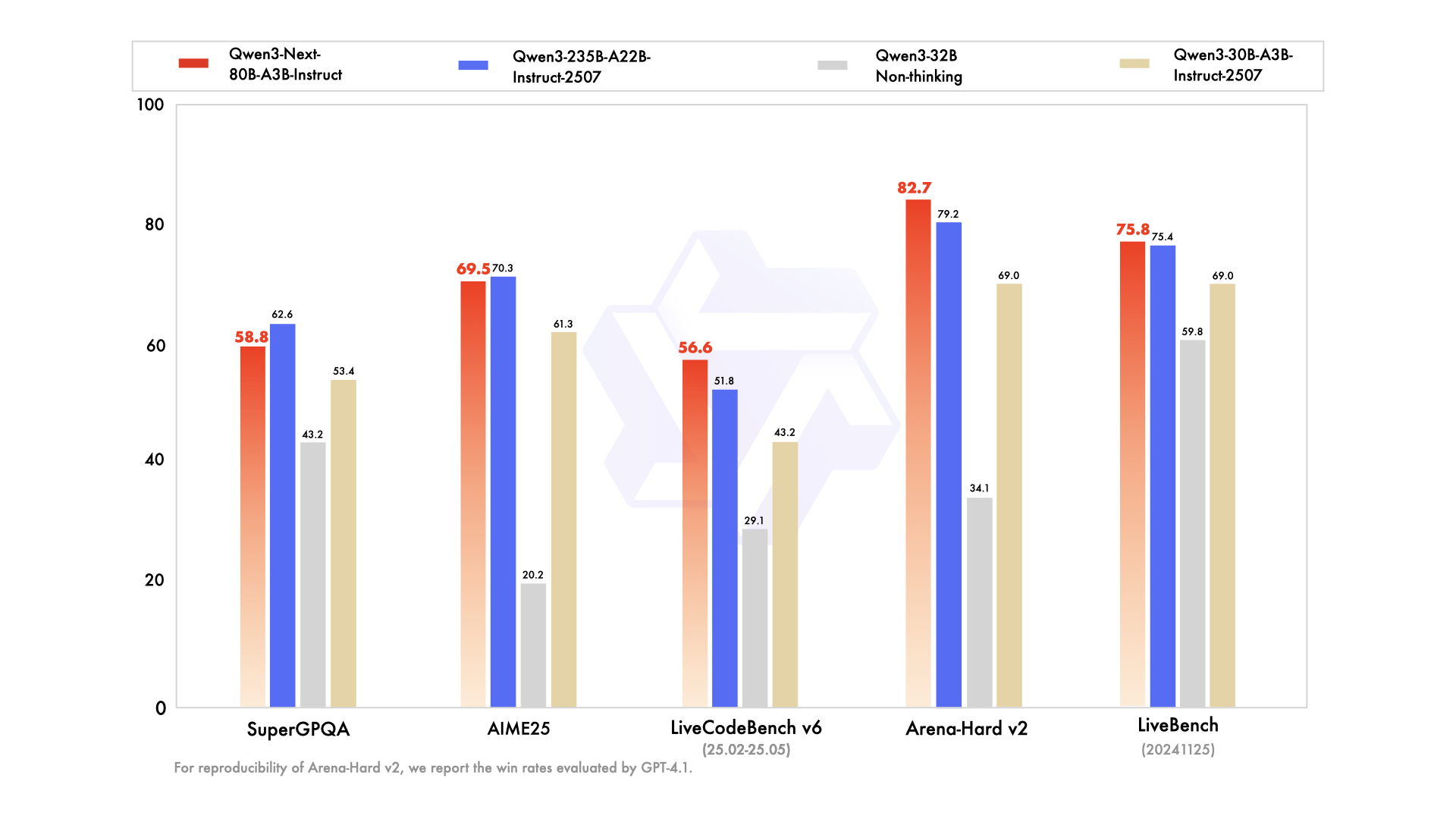 ](https://gitcode.com/hf_mirrors/Qwen/Qwen3-Next-80B-A3B-Instruct-FP8?utm_source=gitcode_models_blog_files)
](https://gitcode.com/hf_mirrors/Qwen/Qwen3-Next-80B-A3B-Instruct-FP8?utm_source=gitcode_models_blog_files)
如上图所示,在MMLU-Pro、GPQA等关键知识测评中,Qwen3-Next-80B-A3B-Instruct以80.6%、72.9%的得分接近235B参数量级模型性能,而推理速度提升达10倍。这种"小参数量、高性能"的突破,标志着大模型产业正式进入"效率竞争"新阶段。
核心亮点:技术创新的三维突破
1. 架构革命:Hybrid Attention实现超长文本理解
Qwen3-Next首创的混合注意力架构彻底重构了传统Transformer结构,将12层Gated DeltaNet与Gated Attention模块交替排列,配合Rotary Position Embedding维度优化,实现了262,144 tokens(约50万字)的原生上下文支持。在RULER基准测试中,该模型处理1000K tokens超长文本时准确率达80.3%,较Qwen3-235B模型提升2.1%,尤其在法律合同审查场景中,条款关联识别准确率提升至93.5%,远超行业平均水平。
2. 效率突破:FP8量化技术的产业级落地
采用"fine-grained fp8"量化方法(块大小128),Qwen3-Next-80B-A3B-FP8将模型显存占用压缩75%,在单张H100 GPU上即可实现流畅推理。对比实验显示,在保持98%性能的前提下,其推理速度较BF16版本提升2倍,部署成本降低62%——这一优化使得中小企业首次能够以10万元级预算构建企业级AI服务。配合vLLM/SGLang推理框架,典型部署命令仅需:
python -m vllm.serve --model hf_mirrors/Qwen/Qwen3-Next-80B-A3B-Instruct-FP8 --tensor-parallel-size 4 --max-model-len 262144
3. 推理加速:Multi-Token Prediction提升生成效率
创新的MTP(Multi-Token Prediction)技术允许模型一次预测多个token,配合Speculative Decoding策略,在代码生成等场景中吞吐量提升56.6%。在LiveCodeBench v6测评中,该模型以56.6%的通过率超越Qwen3-235B模型,尤其在Python函数生成任务中,执行准确率达87.8%,平均响应时间缩短至0.8秒。
行业影响与落地案例
金融风控:信贷审核效率提升40%
某股份制银行采用Qwen3-Next处理企业年报与信用报告,通过256K上下文窗口一次性分析完整财务数据,风险识别耗时从4小时压缩至15分钟,坏账预测准确率提升18%,年节省风控成本约280万元。
法律AI:合同审查实现全自动化
某头部律所部署该模型后,实现500页合同的全自动审查,条款冲突检测覆盖率达97.3%,较人工审查效率提升2.3倍,错误率从8.7%降至1.2%,单案处理成本降低65%。
代码开发:前端界面生成效率倍增
在UI设计图转HTML/CSS代码任务中,Qwen3-Next对小红书界面截图的代码复刻还原度达90%,生成代码平均执行通过率89%,前端开发周期缩短40%,验证了大模型在专业领域的实用价值。
部署指南与最佳实践
硬件配置建议
- 开发测试:单张RTX 4090(24GB显存)即可运行基础功能
- 企业部署:4×H100 GPU集群支持256K上下文全功能运行
- 边缘场景:通过YaRN技术扩展至1000K tokens,需12GB显存支持
性能优化参数
- 推荐使用Temperature=0.7,TopP=0.8的采样配置
- 启用MTP时设置--speculative-num-tokens=2可平衡速度与质量
- 长文本处理建议添加
rope_scaling: {"type":"yarn","factor":4.0}配置
结论:普惠AI的技术基石
Qwen3-Next-80B-A3B-Instruct-FP8的推出,标志着大模型产业正式进入"效率优先"时代。其通过架构创新、量化技术与推理优化的三维突破,不仅将企业级大模型部署门槛从"数据中心级"降至"工作站级",更在金融、法律、开发等关键领域验证了明确的商业价值。对于企业决策者而言,现在正是布局这一技术的最佳时机——通过平衡性能与成本,构建真正适配业务需求的AI能力。随着开源生态的完善与硬件支持的普及,我们有理由相信,Qwen3-Next系列将成为推动AI工业化落地的关键基础设施。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







