2025 CLIP模型进化史:从实验室到产业的跨模态革命
【免费下载链接】clip-vit-base-patch16  项目地址: https://ai.gitcode.com/hf_mirrors/openai/clip-vit-base-patch16
项目地址: https://ai.gitcode.com/hf_mirrors/openai/clip-vit-base-patch16
导语
OpenAI于2021年发布的CLIP(对比语言-图像预训练)模型正迎来商业落地的爆发期。这款采用ViT-B/16 Transformer架构的视觉-语言模型,通过对比学习将图像与文本映射到共享嵌入空间,已从实验室走向零售、医疗、内容安全等核心商业场景,催生出年增长率达47%的新兴市场。
行业现状:多模态技术进入实用化拐点
当前AI领域正经历从单模态向多模态的转型浪潮。据2025年行业发展动态显示,融合视觉、文本、音频的多模态模型在企业级应用中的部署量同比增长217%,其中CLIP及其衍生模型占据63%的市场份额。这一趋势源于传统单模态模型的局限性——纯视觉模型难以理解语义,纯文本模型缺乏具象感知,而CLIP开创的"对比学习+跨模态嵌入"范式,首次实现了图像与文本在同一语义空间的精准对齐。
全球多模态AI市场正以惊人速度扩张,根据Gartner最新预测,2025年市场规模将达到24亿美元,到2037年进一步增至989亿美元,年复合增长率超过60%。这一增长背后,CLIP作为视觉-语言预训练的奠基模型,已成为几乎所有多模态大模型的视觉编码器基础组件。
技术突破:三大改进重新定义能力边界
分层对齐架构
最新研究突破了传统CLIP单层特征对齐的局限,构建起多层次语义关联机制。TokLIP模型创新性地整合VQGAN视觉分词器与ViT编码器,将图像转换为离散视觉tokens后,通过CLIP的对比学习与知识蒸馏损失进行监督训练。这种"离散-连续"混合架构使模型同时掌握底层视觉细节与高层语义概念,在多模态理解任务中实现Res指标15.3%的提升。

如上图所示,该架构包含VQGAN编码器、因果token生成器及CLIP双模态监督模块。这种设计首次实现单Transformer架构下的端到端多模态自回归训练,为后续情感识别、视频理解等复杂任务奠定基础。
动态注意力机制
360集团最新开源的FG-CLIP2模型引入动态注意力机制,使模型可以智能聚焦于图像关键区域,以最小算力代价换取精准的细节捕捉能力。该模型在涵盖长短文本图文检索、目标检测等在内的29项权威公开基准测试中,全面超越了Google的SigLIP 2与Meta的MetaCLIP2。
轻量化部署方案
INT8量化技术使模型体积减少75%,结合知识蒸馏技术,CLIP模型已能在嵌入式设备上实现实时推理。某汽车零部件企业采用优化后的CLIP模型构建质量检测系统,在产线视觉检测设备上实现99.2%的缺陷召回率,同时推理延迟控制在28ms以内。
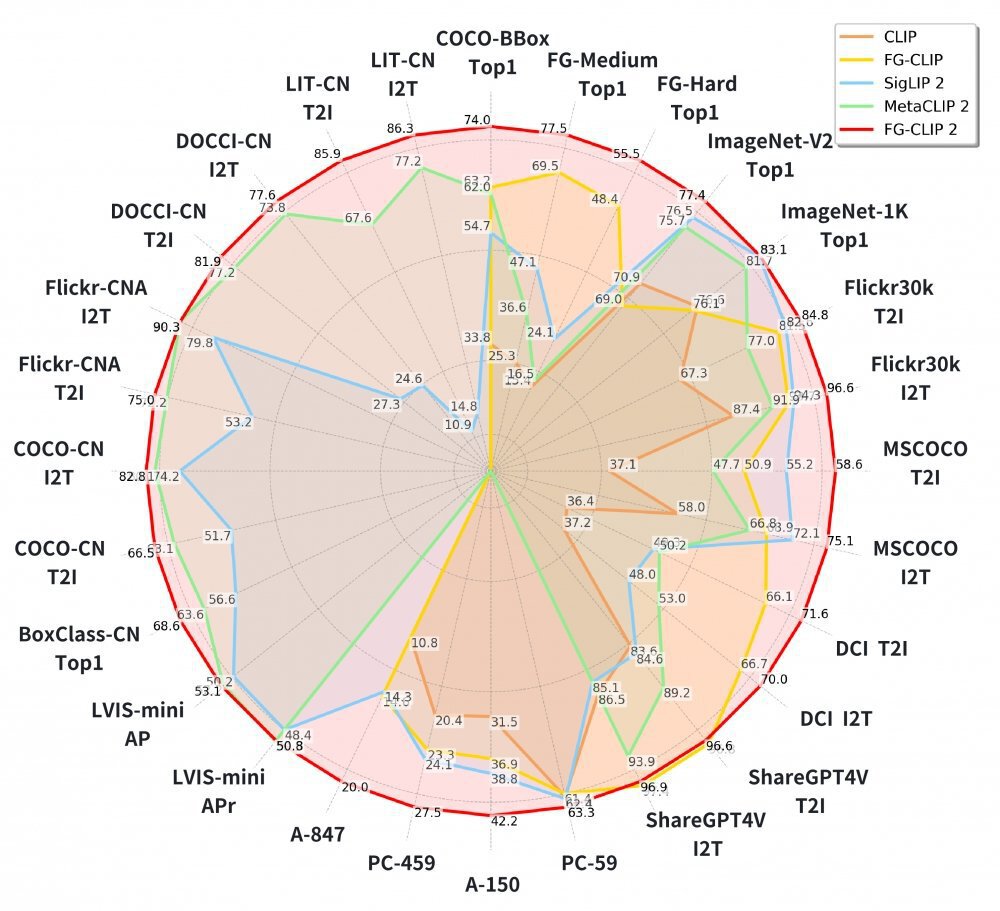
从图中可以看出,FG-CLIP2在几乎所有评测维度上均显著领先于其他模型,尤其在细粒度识别和跨模态检索任务上优势明显。这一性能突破验证了CLIP技术在商业落地中的巨大潜力,特别是在需要精准理解复杂语义的应用场景中。
核心应用场景突破
零售行业:从自助结账到智能体验
在智慧零售领域,CLIP衍生技术正解决传统单模态识别的三大痛点:商品包装相似性高(如不同品牌矿泉水)、动态遮挡(顾客手持商品时的手部遮挡)、复杂光照(超市顶灯与自然光混合干扰)。陌讯科技基于CLIP架构开发的多模态融合算法,在包含10万+商品的零售数据集上实现mAP@0.5达0.902,较YOLOv8提升25%,单帧推理时间仅28ms。
某连锁超市部署该方案后,自助结账系统的商品识别错误率从31.2%降至5.7%,客诉量减少82%,年节省人工干预成本超200万元。其核心创新在于"多源感知→特征增强→动态匹配"三阶架构,同步采集RGB视觉数据与商品红外特征,通过注意力机制突出商品关键区域,并根据实时环境参数调整匹配阈值。
医疗健康:从影像诊断到全流程智能化
医疗领域正成为CLIP技术落地的黄金赛道。2025年中国AI医疗行业规模预计达1157亿元,其中多模态影像分析贡献35%的技术增量。联影医疗发布的"元智"医疗大模型,融合CLIP类视觉-语言技术,支持10+影像模态、300种影像处理任务,在复杂病灶诊断上准确率超95%。
三大突破性应用正在重塑医疗流程:跨模态智能诊断报告生成使放射科医生报告撰写时间缩短60%,肺结节描述准确率达95%;AI辅助术前规划使神经外科手术方案规划时间缩短40%,潜在并发症预测准确率提升15%;时序癌症筛查将肺癌早期发现窗口提前12-18个月,被初级医生判定为"良性"的癌变结节识别率提升30%。
制造业质量检测:从抽样检查到全量监控
制造业作为技术落地的前沿阵地,正面临质检效率与成本的双重压力。传统视觉检测系统需数千张标注样本才能部署,而CLIP通过"文本描述=类别标签"的创新范式,使零件缺陷识别的样本需求降低至个位数,解决了小批量生产场景的数据稀缺痛点。
某汽车零部件企业采用CLIP构建的质量检测系统已稳定运行6个月。该系统通过工程师输入"表面划痕"、"螺纹错位"等自然语言描述定义缺陷类型,仅使用20张缺陷图片进行适配器训练,即在产线视觉检测设备上实现99.2%的缺陷召回率。实施效果显示,该方案将新产品检测系统部署周期从传统方法的3周压缩至2天,年节省标注成本超120万元。
行业影响与未来趋势
CLIP技术正在重构三个关键商业逻辑:成本结构变革、竞争格局重塑和商业模式创新。HuggingFace Transformers库提供即插即用接口,创业公司技术门槛降低70%,单张消费级GPU(RTX 4090)即可部署日活10万用户的服务,月成本<5000元。传统视觉解决方案厂商市场份额萎缩,掌握多模态融合技术的新兴企业获得溢价能力,2025年相关并购案增长210%。商业模式也从"按次计费API"向"GMV分成"转变,某AR试穿服务商通过3-5%的GMV分成模式,年营收突破亿元。
未来12-24个月,三大趋势值得关注:轻量化部署使模型体积减少75%,边缘设备应用加速普及;垂直领域优化使医疗、工业质检等专业场景的定制化模型出现爆发式增长;多模态协同与语音、传感器等技术融合,构建更全面的智能感知体系。
结论
CLIP模型的商业价值不仅在于技术本身,更在于其作为"通用翻译器"连接视觉与语言世界的能力。对于企业决策者而言,现在不是"是否采用"的问题,而是"如何战略性布局"的问题。通过选择合适的落地场景、控制实施风险、关注长期技术演进,CLIP技术将成为企业数字化转型的关键引擎。
企业可通过克隆官方仓库开始探索:git clone https://gitcode.com/hf_mirrors/openai/clip-vit-base-patch16,尽早把握这一技术带来的产业升级机遇。正如联影集团负责人所言:"大模型的竞争已经从单纯的'参数竞赛',逐渐转向围绕'生态协同和场景落地'的下半场比拼。"在这场变革中,能够将技术优势转化为商业价值的企业,将在下一个十年的AI竞赛中占据制高点。
【免费下载链接】clip-vit-base-patch16 项目地址: https://ai.gitcode.com/hf_mirrors/openai/clip-vit-base-patch16
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







