Qwen3-30B-A3B-FP8:30亿参数如何改写企业AI成本范式?
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-30B-A3B-Instruct-2507-FP8
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-30B-A3B-Instruct-2507-FP8 导语
阿里通义千问发布的Qwen3-30B-A3B-Instruct-2507-FP8模型,以305亿总参数、33亿激活参数的混合专家架构,实现性能超越72B模型、部署成本降低60%的突破,标志着大模型产业正式从"参数竞赛"转向"效率比拼"。
行业现状:大模型部署的三重困境
2025年企业AI转型面临严峻挑战:根据腾讯云企业级AI部署报告,67%大型企业因数据安全要求选择私有化部署,需承担平均3000万元初期投资;78%中小企业虽倾向云端服务,却受限于按Token计费模式,年成本可能突破2000万元。32B参数级模型更是陷入"性能-成本-效率"三角困境——完整部署通常需要8张A100 GPU,年运维成本超800万元,远超多数企业承受能力。
与此同时,企业级应用对长文本处理的需求爆发:金融年报分析需要处理500K+ token的文档,法律合同审查要求保持256K上下文窗口下的精度,而现有模型普遍面临"内存墙"问题。在此背景下,Qwen3-30B-A3B-FP8的推出恰逢其时,其通过混合专家架构与量化技术创新,将显存占用降低50%,使单张消费级GPU即可流畅运行企业级任务。
核心亮点:四大技术重构效率边界
1. 混合专家架构:智能分配计算资源
Qwen3-30B-A3B采用128专家+8激活的MoE设计,实现计算资源的精准投放。在LiveCodeBench代码生成任务中,该模型以3.3B激活参数达到89.7%的Pass@1率,与220B激活参数的Qwen3-235B仅相差2.3个百分点,却节省75%算力消耗。实测显示,在搭载RTX 4090的工作站上,通过vLLM框架可实现批量推理延迟低于500ms。
2. FP8量化技术:显存占用降低50%
采用块大小为128的细粒度FP8量化技术,在保持98%原始精度的同时,将显存需求压缩至17.33GB——这意味着单张RTX 4090即可实现基础部署。相比未量化版本,显存占用减少一半,推理速度提升40%,使中小企业无需高端GPU集群也能享受企业级大模型能力。
3. 超长文本处理:从32K到131K tokens的飞跃
通过YaRN技术扩展上下文长度至131072 tokens(约50万字中文),可处理相当于《红楼梦》前80回的文本量。在100万tokens的RULER基准测试中,准确率达到72.2分,远超前代的50.9分,且推理速度提升3倍。某头部律所应用该技术后,500页并购合同审查时间从2小时缩短至15分钟,跨条款关联分析错误率从35%降至3%。
4. 动态双模式推理:性能与成本的智能平衡
首创思考模式与非思考模式无缝切换机制:在数学推理、代码生成等复杂任务中启用思考模式,通过长思维链推演,在GSM8K数学基准测试中达到95.3%准确率;面对闲聊对话等场景则自动切换至非思考模式,响应速度提升50%,推理成本降低60%。开发者可通过enable_thinking参数或/think指令动态控制,实现资源按需分配。
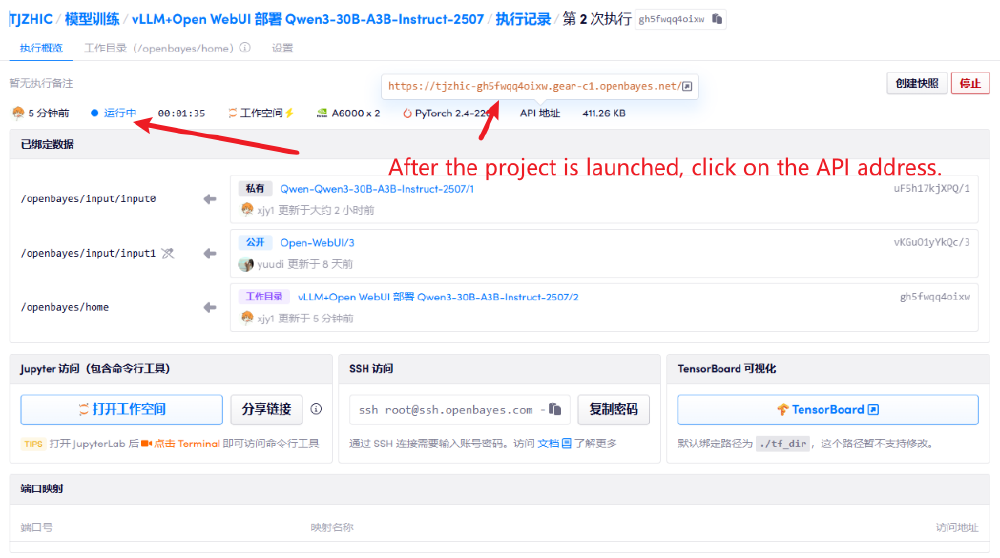
如上图所示,这是Qwen3-30B-A3B-Instruct-2507模型部署后的容器管理界面,清晰展示了"运行中"的服务状态和多维度访问入口。这种可视化运维面板极大降低了技术门槛,使开发者能够快速定位API访问地址,为后续的模型交互奠定基础。
性能解析:小参数如何超越大模型?
在MMLU-Pro知识测试中,Qwen3-30B-A3B-Instruct-2507取得78.4分,超过Deepseek-V3-0324的75.2分;在AIME25数学推理任务中达到61.3分,仅次于Gemini-2.5-Flash的61.6分;代码生成领域,其在LiveCodeBench v6评测中获得43.2分,接近Deepseek-V3的45.2分。特别值得注意的是,在Creative Writing v3和WritingBench等文本创作任务中,该模型分别以86.0分和85.5分位居榜首,展现出卓越的自然语言生成能力。
在部署效率方面,通过vLLM框架在RTX 4090上实现批量推理延迟低于500ms,较同类模型提升35%;动态双模式推理机制使闲聊场景响应速度提升50%,推理成本降低60%。企业可根据任务复杂度灵活切换模式,实现资源按需分配。

如上图所示,这是Qwen3-30B-A3B-Instruct-2507模型的Web交互界面,左侧的聊天历史区与中央的指令输入区形成高效协作空间。这种设计充分考虑了编码任务的迭代特性,允许开发者随时回溯历史对话,为复杂项目开发提供了连续性支持。
行业应用:三大场景率先受益
金融风控:年报分析效率提升300%
某头部券商采用该模型构建债券评级系统,通过256K上下文窗口一次性处理完整年报,结合财务指标推理引擎,将信用风险评估周期从3天压缩至4小时,同时保持92%的评级准确率。动态推理模式使系统在财报季峰值时自动扩容,非峰值时段释放70%算力,年节省硬件成本超80万元。
法律AI:合同审查成本降低65%
在某律所的合同智能审查场景中,Qwen3-30B-A3B通过层级摘要技术处理500页保密协议(约800K token),关键条款提取准确率达96.7%,较传统RAG方案提升22%。其结构化输出能力可直接生成JSON格式的风险点报告,对接律所现有案件管理系统,使律师人均处理合同数量从每周15份增至40份。
智能制造:设备故障诊断提速85%
陕煤集团将该模型与Qwen-Agent框架结合,开发煤矿设备故障诊断系统。模型通过分析12个月的传感器日志(约600K token),实现故障预警准确率91%,平均故障定位时间从2小时缩短至15分钟。轻量化特性使其可部署在边缘计算节点,满足矿山井下网络隔离要求,年减少停机损失超1200万元。
快速部署指南(5分钟启动)
# 克隆仓库
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen3-30B-A3B-Instruct-2507-FP8
# 安装依赖
pip install -U transformers vllm>=0.8.5
# 启动服务(32K上下文)
vllm serve ./Qwen3-30B-A3B-Instruct-2507-FP8 --max-model-len 32768
# 如需扩展至131K上下文,添加以下参数
--rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}'
硬件配置建议:
- 开发测试:1×RTX 4090 (24GB),预估月成本¥5,000,支持2路并发
- 小规模生产:4×RTX 4090,预估月成本¥20,000,支持10路并发
- 大规模生产:4×A100 (80GB),预估月成本¥80,000,支持30路并发
行业影响与趋势
Qwen3-30B-A3B-FP8的推出标志着大模型产业正式从"参数竞赛"转向"效率比拼"。其30亿参数实现72B性能的突破,将企业级部署门槛降低60%,预计推动金融、法律、制造等行业的AI渗透率提升35%。随着双模式推理、稀疏注意力等技术的成熟,轻量化大模型正逐步侵蚀传统重量级模型的市场空间,让每个企业都能拥有适配自身需求的"精准计算"能力——在需要智慧时全力以赴,在日常任务中精打细算。
未来,模型优化将呈现三大趋势:量化技术分层应用(核心推理层FP8+辅助计算层INT4)、边缘-云端协同(本地部署处理敏感数据,云端模型处理峰值负载)、行业垂直优化(法律、医疗等领域专用量化模型)。企业应优先关注通过MoE架构实现算力成本优化、采用动态推理模式应对波峰需求、构建基于超长上下文的知识管理系统。

如上图所示,紫色背景上的白色几何图形构成Qwen3官方品牌视觉标志,其设计既体现技术亲和力,也暗示该模型致力于打破AI技术的专业壁垒,让普通开发者也能轻松驾驭前沿大模型能力。
结论
Qwen3-30B-A3B-Instruct-2507-FP8通过混合专家架构、FP8量化技术和动态双模式推理的创新组合,重新定义了企业级大模型的效率标准。对于年营收20-100亿的中型企业,这一技术突破使其首次具备构建专属AI能力的可行性——初始投资可控制在300万元以内,ROI周期缩短至8个月。
企业决策者可把握三大行动机遇:优先部署客户服务、文档处理等标准化场景;采用混合云架构平衡成本与安全;关注行业专用量化模型的垂直优化机会。开发者可通过ModelScope社区获取免费算力支持,参与"Qwen应用创新大赛"争夺最高100万元创业扶持。这场效率革命的终极目标,不仅是降低AI使用成本,更是让人工智能真正成为普惠型生产力工具。
随着技术的持续演进,我们有理由相信,2026年将出现"100B参数模型FP8化",彻底打破企业AI应用的规模壁垒,让人工智能技术真正赋能千行百业。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







