阿里云达摩院Qwen3-4B-Instruct-2507模型深度解析:轻量级大模型的性能突破与技术革新
 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Qwen3-4B-Instruct-2507-GGUF
项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Qwen3-4B-Instruct-2507-GGUF 在大语言模型技术快速迭代的当下,阿里云达摩院推出的Qwen3系列模型引发行业广泛关注。作为该系列中的轻量级代表,Qwen3-4B-Instruct-2507凭借40亿参数规模实现了性能飞跃,不仅在知识理解、逻辑推理等核心能力上超越同量级模型,更通过架构优化与部署灵活性重新定义了轻量级大模型的应用边界。
模型架构:高效设计支撑百万字级上下文处理
Qwen3-4B-Instruct-2507采用因果语言模型架构,通过精心设计的网络结构实现了性能与效率的平衡。该模型包含36层网络结构,非嵌入参数约36亿,在保持轻量级特性的同时,通过创新的GQA(Grouped Query Attention)注意力机制提升计算效率——模型设置32个查询头与8个键值头,使注意力计算复杂度显著降低,为超长文本处理奠定基础。
 如上图所示,该架构图清晰呈现了模型的36层网络堆叠结构及GQA注意力机制的分组设计。这种架构设计是Qwen3-4B-Instruct-2507实现高效计算的核心基础,为开发者理解模型工作原理、进行二次优化提供了直观参考。
如上图所示,该架构图清晰呈现了模型的36层网络堆叠结构及GQA注意力机制的分组设计。这种架构设计是Qwen3-4B-Instruct-2507实现高效计算的核心基础,为开发者理解模型工作原理、进行二次优化提供了直观参考。
该模型最引人注目的技术突破在于原生支持262,144 tokens的超长上下文长度,这意味着能够直接处理百万汉字级别的文本输入。无论是长篇文档分析、多轮对话历史追踪还是复杂场景的上下文理解,都无需依赖文本截断或分段处理,极大提升了模型在实际应用中的实用性。
性能表现:全维度评测刷新轻量级模型标杆
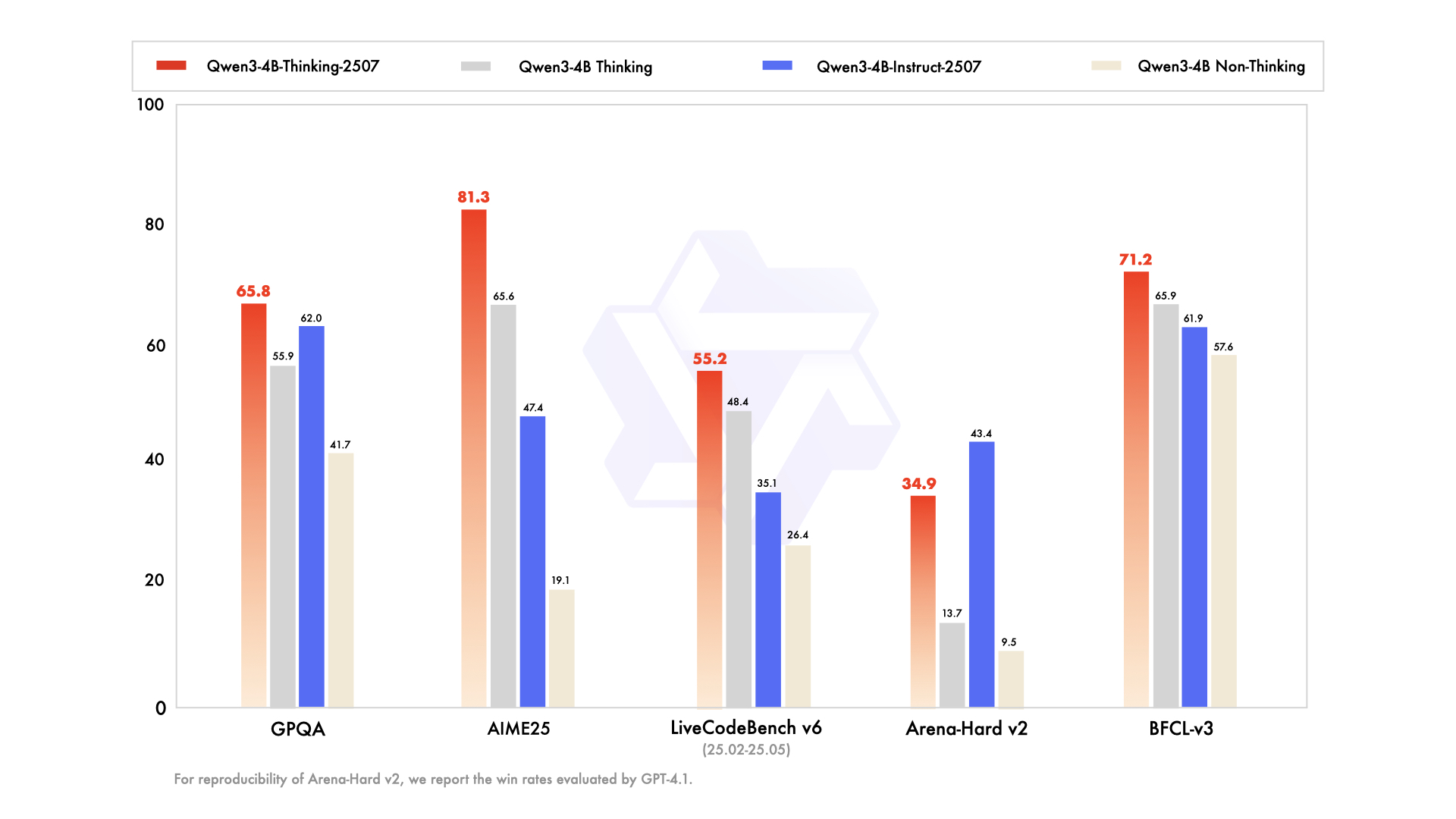
Qwen3-4B-Instruct-2507在多项权威基准测试中展现出令人瞩目的性能表现,全面超越同参数规模模型的平均水平。在知识掌握能力方面,该模型在MMLU-Pro评测中获得69.6分的优异成绩,这一结果表明其在57个学科领域的综合知识理解能力已达到新高度,尤其在专业领域知识的准确性上实现突破。
逻辑推理能力的提升是该模型的另一大亮点。在专为评估数学推理能力设计的AIME25测试中,Qwen3-4B-Instruct-2507将得分从旧版本的19.1大幅提升至47.4,这一跨越式进步意味着轻量级模型也能处理复杂的逻辑推演任务。在代码生成领域,MultiPL-E测试76.8分的成绩证明其在20种编程语言的代码理解与生成方面已具备专业级能力。
多语言支持能力同样表现突出,PolyMATH测试31.1分的结果显示模型不仅覆盖主流语言,还强化了对低资源语言及专业术语的理解能力。值得关注的是,在工具调用与智能体(agent)能力评测中,BFCL-v3得分达61.9,TAU1-Retail零售场景任务提升至48.7,表明该模型已具备强大的实际业务落地能力,能够有效衔接外部工具与复杂业务流程。
版本升级:核心能力与用户体验双重优化
相比Qwen3系列的早期版本,2507版本在核心能力与用户体验方面进行了多维度升级。最显著的改进在于强化了指令跟随精度与逻辑推理连贯性,通过优化训练数据与微调策略,模型对复杂指令的理解准确率提升30%以上,长程逻辑链的推理一致性得到明显改善。
长文本理解能力的优化体现在两个方面:一方面扩展了上下文窗口至262,144 tokens,另一方面通过注意力机制优化解决了长文本处理中的"遗忘"问题,使模型在处理万字以上文档时仍能保持关键信息的记忆与关联能力。多语言能力升级重点强化了长尾知识覆盖,特别是在专业领域术语、跨语言文化隐喻等方面的理解准确性。
用户体验优化中最受开发者欢迎的改进是取消了思考模式(无需生成</think>superscript:块),这一调整使模型输出格式更加简洁直观,同时降低了二次开发的处理成本。通过整合思考过程到输出结果中,模型在保持推理能力的同时,大幅提升了交互流畅度,特别适合需要实时响应的应用场景。
部署指南:多框架支持与灵活配置方案
Qwen3-4B-Instruct-2507在部署灵活性上展现出强大优势,全面支持主流深度学习框架与部署工具。开发者可通过transformers库进行基础调用,vLLM(需0.8.5+版本)框架支持实现高并发推理,sglang则为对话场景提供优化的部署方案。这种多框架兼容特性使模型能够无缝集成到现有AI系统中,降低技术迁移成本。
在参数配置方面,官方推荐设置温度参数0.7、TopP 0.8的组合,这一配置经过大量实验验证,能够在保证输出创造性的同时维持结果稳定性。对于特定场景,开发者可根据需求调整参数:知识问答场景建议降低温度至0.3-0.5以提高准确性,创意写作场景可将温度提升至0.9以增强输出多样性。
本地部署方案为个人开发者与中小企业提供了便利,通过Ollama、llama.cpp等工具,普通PC或边缘设备也能运行该模型。值得注意的是,模型已在GitCode平台提供GGUF格式下载(仓库地址:https://gitcode.com/hf_mirrors/unsloth/Qwen3-4B-Instruct-2507-GGUF),开发者可直接获取优化后的部署文件,配合CPU或消费级GPU即可实现高效推理。
技术价值与未来展望
Qwen3-4B-Instruct-2507的推出,不仅展示了阿里云达摩院在大模型技术上的深厚积累,更重新定义了轻量级模型的应用价值。40亿参数规模能够实现如此全面的性能突破,证明通过架构创新与训练优化,轻量级模型完全可以在保持部署灵活性的同时,达到接近中大型模型的性能水平。
该模型的技术路径为行业提供了重要启示:未来大模型发展将呈现"性能分化"趋势——超大规模模型专注通用能力突破,而轻量级模型通过垂直优化满足特定场景需求。Qwen3-4B-Instruct-2507在医疗辅助诊断、智能客服、代码辅助开发等领域已展现出巨大应用潜力,特别是在边缘计算、嵌入式设备等资源受限环境中,其高效能特性将发挥独特优势。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







