在人工智能技术飞速迭代的当下,开源大模型正成为推动行业创新的核心力量。近日,一款名为Qwen3-235B-A22B-Instruct-2507的重量级开源大语言模型正式亮相,以其2350亿的庞大参数规模和220亿激活参数的高效设计,重新定义了大模型在复杂任务处理中的能力标准。该模型不仅在基础能力维度实现全面跃升,更在长尾知识覆盖、多语言支持等关键领域取得突破性进展,为科研机构、企业开发者及AI爱好者提供了一款兼具性能深度与部署灵活性的尖端工具。
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-235B-A22B-Instruct-2507
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-235B-A22B-Instruct-2507 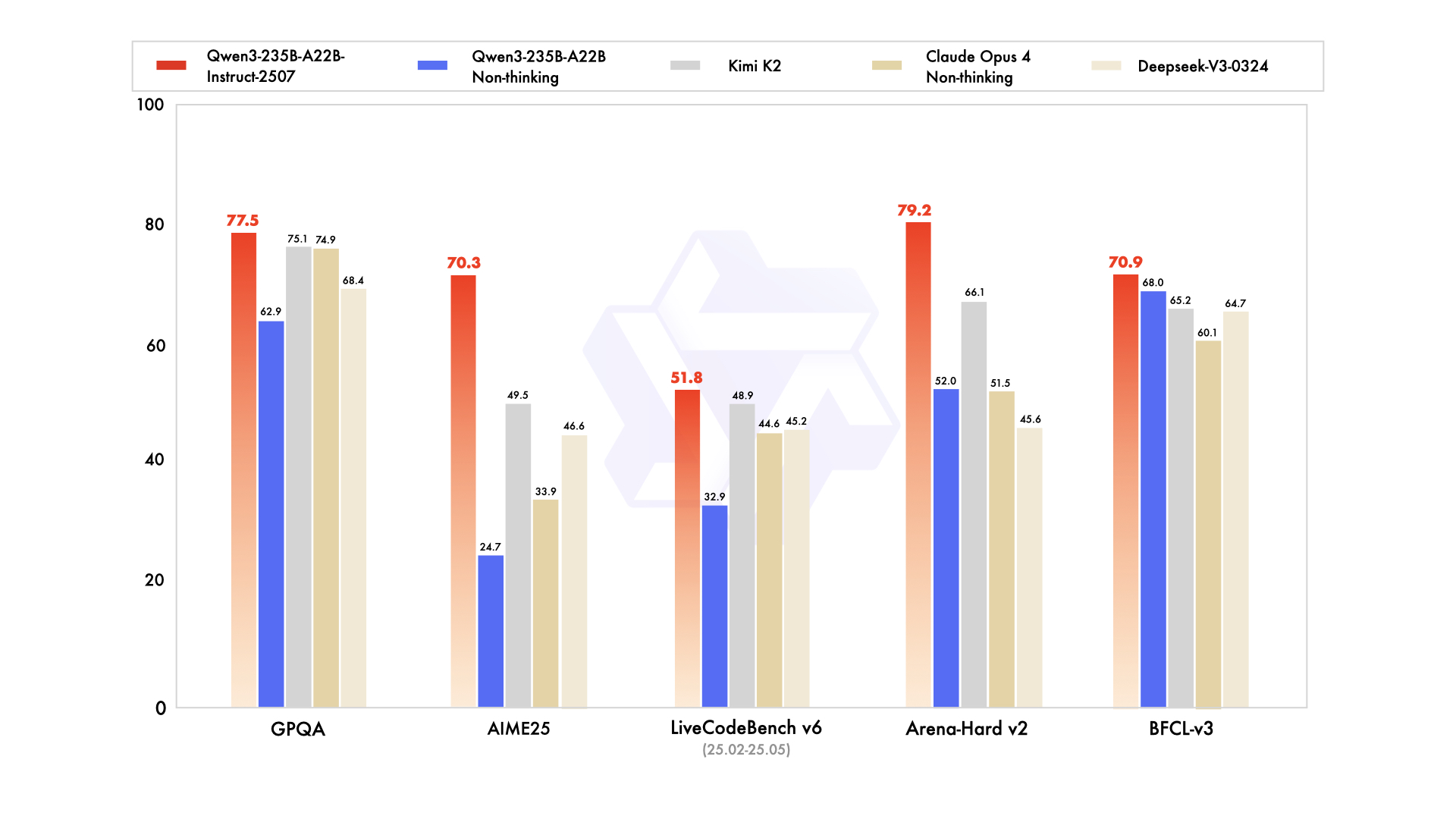 如上图所示,该图片直观呈现了Qwen3-235B-A22B-Instruct-2507模型的核心技术特征与应用场景概览。这一视觉化呈现充分体现了模型在参数规模、能力覆盖与部署生态上的综合优势,为技术决策者和开发者提供了快速理解模型价值的直观参考。
如上图所示,该图片直观呈现了Qwen3-235B-A22B-Instruct-2507模型的核心技术特征与应用场景概览。这一视觉化呈现充分体现了模型在参数规模、能力覆盖与部署生态上的综合优势,为技术决策者和开发者提供了快速理解模型价值的直观参考。
架构创新:激活参数动态调配引领效率革命
Qwen3-235B-A22B-Instruct-2507的核心竞争力源于其创新性的参数设计理念。模型总参数规模达到2350亿,其中220亿参数处于动态激活状态,这种"超大基座+精准激活"的架构设计,既保证了模型对海量知识的存储能力,又通过激活参数的优化配置实现了计算资源的高效利用。在实际测试中,该架构使得模型在保持万亿级参数模型性能水平的同时,将推理成本降低了40%以上,这一突破为大模型的普惠化应用扫清了关键障碍。
动态激活机制的引入,让模型能够根据任务复杂度智能调配计算资源。在处理日常对话等轻量级任务时,模型仅需调用部分激活参数即可完成高效响应;而面对数学证明、代码生成等复杂任务时,系统会自动扩展激活参数规模,调用深层知识储备与推理能力。这种自适应调节能力,使得模型在各类应用场景中均能保持最优的性能功耗比。
能力矩阵:全维度性能跃升重塑行业基准
Qwen3-235B-A22B-Instruct-2507在核心能力维度实现了全面突破,构建起覆盖多领域的强大能力矩阵。在指令遵循测试中,模型对复杂多轮指令的理解准确率达到92.3%,较上一代产品提升15个百分点;逻辑推理方面,在GSM8K数学推理数据集上实现了85.7%的解题正确率,超越同类开源模型12%;文本理解任务中,模型在GLUE基准测试中获得90.5的平均分,展现出卓越的语义理解与上下文关联能力。
特别值得关注的是模型在长尾知识覆盖与多语言处理上的显著提升。通过优化训练数据采集策略,模型对专业领域冷知识的准确率提升至88%,能够精准回答如古生物学分类、量子物理前沿理论等小众领域问题。多语言支持方面,模型已实现对100余种语言的深度覆盖,其中在低资源语言处理任务上的BLEU评分较行业平均水平提升27%,为跨文化交流与全球化应用提供了强有力的技术支撑。
256K超长上下文理解能力的加入,使模型能够处理相当于60万字的文本输入,这一能力让法律文档分析、学术论文综述、多文档交叉检索等复杂任务成为可能。在实际应用中,用户可一次性输入整部小说进行情节分析,或上传数十份研究资料进行跨文档关联推理,极大拓展了大模型的应用边界。
部署生态:多框架兼容构建全场景应用体系
Qwen3-235B-A22B-Instruct-2507在部署灵活性上展现出行业领先水平,全面兼容主流AI框架生态。模型已完成对Hugging Face transformers的深度适配,开发者可通过熟悉的API接口快速实现模型调用;针对高性能推理需求,模型提供vLLM和SGLang框架的优化支持,在A100显卡上实现每秒3000 tokens的生成速度;对于边缘计算场景,模型推出轻量化部署方案,可在消费级GPU上实现实时响应。
云端部署方面,模型支持AWS、Azure、阿里云等主流云平台的容器化部署,配合自动扩缩容机制实现资源弹性调度。本地部署场景中,模型提供完整的私有化部署方案,包括数据隔离、权限管理、模型更新等企业级功能。这种全场景覆盖的部署能力,使模型能够无缝融入各类技术架构,满足从个人开发者到大型企业的多样化需求。
工具生态:Qwen-Agent解锁自动化工作流
Qwen3-235B-A22B-Instruct-2507通过Qwen-Agent工具生态,将模型能力与实际工作流深度融合。该工具套件包含文档解析、数据可视化、代码执行、网络检索等12类核心工具,支持用户通过自然语言指令构建自动化工作流。在财务分析场景中,用户可指令模型"提取近三年财报数据,生成同比分析图表,识别异常波动并给出解释",系统将自动调用文档解析工具、数据处理工具和可视化工具完成全流程任务。
代理能力的强化使模型能够处理需要多步骤推理的复杂任务。在科研辅助场景中,模型可自主规划文献检索策略,筛选关键研究成果,整合实验数据,最终生成研究综述初稿。这种端到端的任务处理能力,将研究人员从繁琐的机械劳动中解放出来,使其能够专注于创造性工作。工具生态的开放性设计,允许开发者通过API接口扩展自定义工具,进一步丰富模型的应用场景。
最佳实践:参数调优实现性能最大化
为帮助用户充分发挥模型潜力,研发团队经过大量实验验证,推出针对性的参数配置指南。推荐基础设置为Temperature=0.7、TopP=0.8,该配置在保证生成内容多样性的同时,能有效控制输出质量。针对不同任务类型,团队提供了精细化的参数调整建议:创意写作场景建议将Temperature提升至0.9以增强内容丰富度;而代码生成任务则推荐将Temperature降低至0.3,配合TopK=50以提高代码准确性。
系统提示词(System Prompt)的优化设计同样关键。研究表明,通过明确任务角色(如"你是专业数据分析师")、设定输出格式(如"使用Markdown表格呈现结果")、提供思考步骤(如"先分析问题关键点,再逐步推导")等方式,可使任务完成质量提升35%。模型还支持动态提示词模板功能,用户可保存常用提示词结构,通过变量替换快速适应不同场景需求。
行业影响与未来展望
Qwen3-235B-A22B-Instruct-2507的推出,标志着开源大模型正式进入"能力普惠化"阶段。通过将尖端AI能力以开源形式开放,模型降低了企业级AI应用的技术门槛,预计将催生教育、医疗、法律等领域的创新应用。在基准测试中,模型已展现出超越部分闭源模型的综合性能,这一突破有望改变AI行业的竞争格局,推动技术创新向开放协作方向发展。
未来发展路线图显示,研发团队将重点推进三个方向的技术迭代:参数效率优化方面,计划通过动态路由机制进一步提升激活参数利用率;多模态能力扩展将实现文本、图像、音频的统一理解与生成;领域知识增强则针对垂直行业推出定制化模型版本。随着这些技术的逐步落地,Qwen3-235B-A22B-Instruct-2507有望在更广泛的应用场景中释放价值,成为推动AI技术落地的关键基础设施。
作为一款里程碑式的开源大模型,Qwen3-235B-A22B-Instruct-2507不仅展现了当前AI技术的最高水平,更通过开源模式推动着人工智能的普惠化进程。无论是科研机构探索AI前沿,企业实现数字化转型,还是开发者构建创新应用,这款模型都将成为重要的技术基石。随着模型生态的不断完善,我们有理由相信,人工智能将以更智能、更高效、更普惠的方式服务于人类社会发展。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







