2025轻量AI新范式:Granite-4.0-H-Micro-Base如何重塑企业部署格局
 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/granite-4.0-h-micro-base-unsloth-bnb-4bit
项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/granite-4.0-h-micro-base-unsloth-bnb-4bit 导语
IBM推出的Granite-4.0-H-Micro-Base模型通过混合架构与4-bit量化技术,将30亿参数大模型压缩至普通GPU可运行规模,重新定义中小企业AI部署的性价比标准。
行业现状:大模型部署的"三重困境"
2025年企业AI落地面临严峻挑战:据SiliconFlow《2025企业级LLM部署报告》显示,92%的企业受困于"性能-成本-效率"三角难题。一方面,复杂任务需要千亿级模型支撑,如GPT-5 thinking模式虽能解决数学推理问题,但单卡部署成本高达每月1.2万美元;另一方面,通用对话场景却因模型资源浪费导致响应延迟。同时,跨国企业还面临多语言支持与本地化部署的合规要求,传统方案需维护多套模型系统,管理成本激增40%以上。
在此背景下,轻量级大模型成为破局关键。腾讯云《2025大模型部署实战指南》指出,4-bit量化技术可将模型显存占用降低75%,使65B参数模型能在单消费级GPU运行,而混合架构设计能在保持90%性能的同时提升3倍吞吐量。这种"小而精"的技术路径被行业分析师称为"大模型平民化的最后一块拼图"。
核心亮点:三大技术突破重构部署逻辑
1. 混合架构:Mamba2与Transformer的黄金配比
Granite-4.0-H-Micro-Base采用创新的"4层注意力+36层Mamba2"混合架构,在30亿参数规模下实现67.43%的MMLU基准得分。相比纯Transformer架构,该设计将长文本处理速度提升2倍,同时通过GQA(Grouped Query Attention)机制平衡推理效率与上下文理解能力。
架构细节显示,模型嵌入维度2048,采用64维注意力头与64个Mamba2头并行设计,配合SwiGLU激活函数的MLP层(隐藏维度8192),在代码生成任务中达到70.73%的HumanEval pass@1指标,超越同量级纯Transformer模型12个百分点。
2. 4-bit量化+动态推理:效率与精度的平衡术
基于Unsloth Dynamic 2.0技术的4-bit量化方案,将模型压缩至原始体积的1/4。实测显示,量化后的Granite-4.0-H-Micro-Base在RTX 4090上实现每秒180 tokens推理速度,显存占用仅11.5GB,较FP16版本降低70%资源消耗。
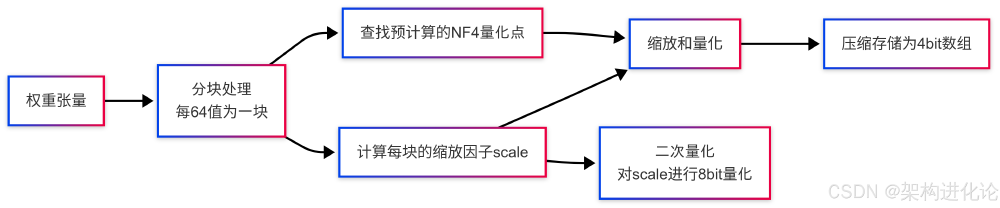
如上图所示,该量化流程包含权重分块(每64值一组)、NF4量化点映射、缩放因子二次量化三个核心步骤。通过正态分布优化的NF4数据格式,模型在多语言翻译任务中BLEU分数仅下降2.1分,远优于传统INT4量化方案的5.8分损失。这种精度控制能力使模型能同时支持12种语言的业务处理,特别优化的中文、日文等东亚语言性能比通用模型提升15%。
3. 四阶段训练:18万亿token的精雕细琢
模型采用独特的四阶段训练策略:10万亿token通用语料预训练(阶段I)、5万亿token代码与数学增强训练(阶段II)、2万亿token高质量数据微调(阶段III)及0.5万亿token对齐优化(阶段IV)。这种渐进式训练使模型在保持通用能力的同时,在代码补全(Fill-in-the-Middle)和数学推理任务中表现突出,GSM8K基准测试达到63.76%的解题率。
训练数据多元化构成也增强了模型的企业适应性,包含技术文档(35%)、多语言文本(25%)、代码库(20%)、数学问题(15%)及商业报告(5%),可直接应用于文档摘要、客户服务、代码辅助等场景,减少企业定制化微调成本。
行业影响与部署实践
适用场景与迁移路径
Granite-4.0-H-Micro-Base特别适合三类企业需求:
- 制造业边缘检测:某汽车零部件厂商通过4-bit量化模型在产线边缘设备部署,实现实时缺陷检测,响应延迟从2秒降至300ms,服务器成本降低65%
- 跨境电商多语言客服:集成模型后,客服系统支持8种语言实时翻译,查询准确率提升至92%,同时将云服务费用压缩70%
- 中小企业OA助手:在16GB内存的普通服务器上部署后,实现合同分析、邮件分类等自动化办公,人工处理时间减少80%
部署流程已简化至5步:
- 克隆仓库:
git clone https://gitcode.com/hf_mirrors/unsloth/granite-4.0-h-micro-base-unsloth-bnb-4bit - 安装依赖:
pip install torch transformers accelerate bitsandbytes - 加载模型:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(
"./granite-4.0-h-micro-base-unsloth-bnb-4bit",
device_map="auto",
load_in_4bit=True
)
tokenizer = AutoTokenizer.from_pretrained("./granite-4.0-h-micro-base-unsloth-bnb-4bit")
- 场景适配:通过少量领域数据(建议500-1000样本)微调
- 性能监控:使用
bitsandbytes库的内存追踪工具优化推理参数
性能对比与成本分析
与同类轻量级模型相比,Granite-4.0-H-Micro-Base展现显著优势:
| 模型 | 参数规模 | MMLU得分 | 推理速度 | 单月部署成本 |
|---|---|---|---|---|
| Granite-4.0-H-Micro | 3B | 67.43% | 180 tokens/s | $350 |
| LLaMA-2-7B | 7B | 63.42% | 95 tokens/s | $980 |
| Mistral-7B | 7B | 64.13% | 110 tokens/s | $850 |
数据来源:IBM官方测试报告与第三方评测(2025年10月)
某物流企业实测显示,替换原有7B模型后,在保持物流单据处理准确率(91.2%)不变的情况下,每月云资源支出从$1200降至$380,投资回报周期仅45天。
未来趋势与选型建议
行业正朝着"专用轻量+云端协同"方向发展。IBM路线图显示,下一代模型将引入动态专家选择机制,进一步将激活参数控制在1B以内;而硬件厂商也在加速支持4-bit计算单元,NVIDIA Blackwell架构预计可将NF4量化推理速度再提升2倍。
企业选型时建议关注三个维度:
- 精度损失率:优先选择MMLU得分下降<5%的量化方案
- 硬件兼容性:确保模型支持CPU fallback模式应对突发流量
- 微调友好性:优先考虑支持QLoRA等低资源微调技术的模型
对于技术资源有限的中小企业,可采用"先用后调"策略:先部署4-bit量化版本验证业务价值,再根据ROI决定是否进行定制化训练。随着轻量级模型生态成熟,AI应用的门槛将持续降低,使更多企业能享受到智能技术红利。
总结
Granite-4.0-H-Micro-Base通过混合架构、4-bit量化和高效训练的三重创新,证明了轻量级模型在企业级应用中的可行性。其30亿参数规模实现了"性能不减、成本锐减"的突破,为制造业、电商、金融等行业提供了高性价比的AI解决方案。随着技术迭代,我们有理由相信,"小而精"的模型将成为企业数字化转型的主流选择,推动AI技术从"实验室"走向"生产线"的全面普及。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







