GLM-4-9B-Chat-1M:国产开源大模型突破1M上下文,重新定义长文本处理标准
【免费下载链接】glm-4-9b-chat-1m  项目地址: https://ai.gitcode.com/hf_mirrors/zai-org/glm-4-9b-chat-1m
项目地址: https://ai.gitcode.com/hf_mirrors/zai-org/glm-4-9b-chat-1m
导语:智谱AI推出的GLM-4-9B-Chat-1M开源模型,以1M上下文长度(约200万中文字符)和多语言支持能力,刷新了开源模型的长文本处理纪录,为企业级文档分析、智能客服等场景提供新可能。
行业现状:长文本成大模型竞争新战场
2024年中国大语言模型市场规模达294.16亿元,预计2026年突破700亿元。随着企业级应用深化,长文本处理能力已成为衡量模型实用性的核心指标——法律合同审查(单份超5万字)、医学文献分析(多章节连贯理解)、代码库解析(百万行级代码上下文)等场景,对模型上下文窗口提出更高要求。目前主流开源模型上下文普遍在100K以内,而GLM-4-9B-Chat-1M的出现,将开源模型的上下文能力提升了一个数量级。
核心亮点:1M上下文+多模态能力的双重突破
1. 超长文本处理能力行业领先
在"大海捞针"实验(Needle-in-a-Haystack)中,GLM-4-9B-Chat-1M在1M上下文长度中植入关键信息,提取准确率随文本长度增长保持稳定。这意味着模型能精准定位长篇文档中的特定信息,如在200万字小说中查找某个人物对话,或在完整企业年报中定位财务数据。
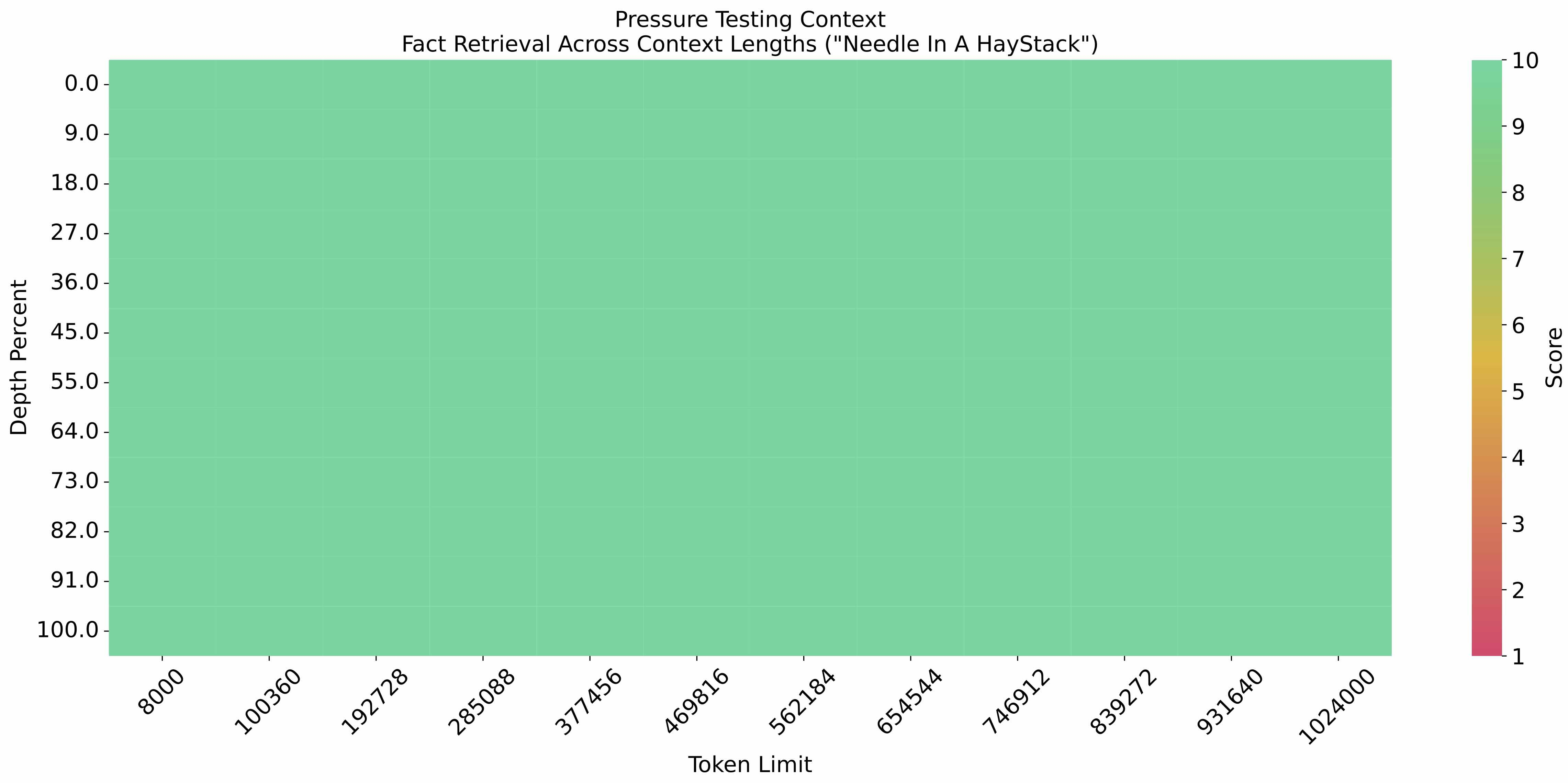
如上图所示,纵轴为信息提取准确率,横轴为上下文长度(单位:K tokens)。可以看到GLM-4-9B-Chat-1M在1M(1000K)上下文下仍保持95%以上的准确率,远超同量级模型在500K时准确率大幅下降的表现。这一特性使其能够处理完整的学术论文、法律卷宗等超长文本,为知识管理系统提供强大支撑。
在LongBench长文本测评中,GLM-4-9B-Chat-1M在摘要生成、多轮对话等8项任务中均位列前三,其中7项超越Llama-3-8B。这种全面的长文本理解能力,使其在需要深度语义分析的场景中具备落地优势。
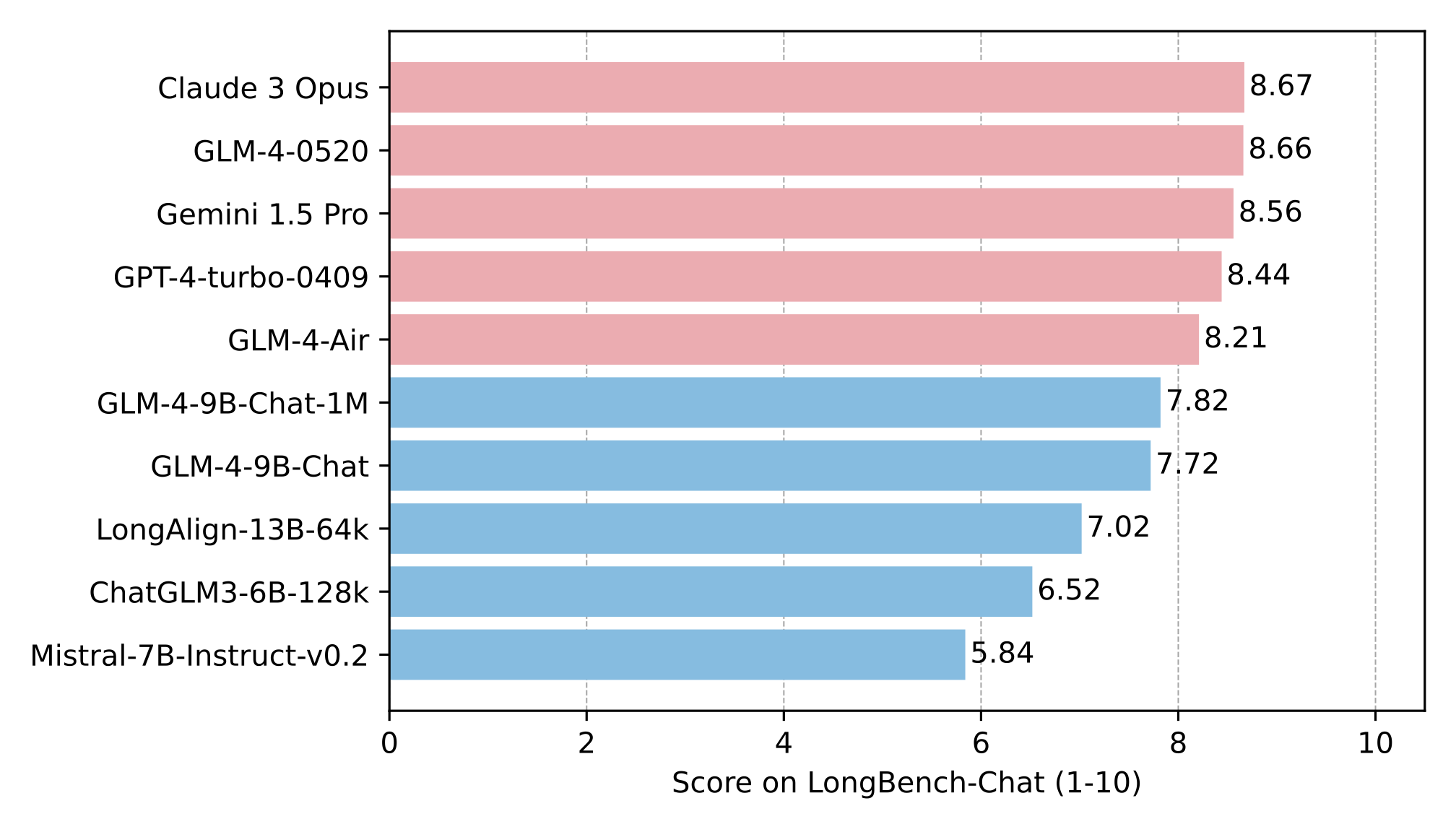
从图中可以看出,GLM-4-9B-Chat在橙色柱状图(代表GLM-4-9B-Chat)在多数任务中处于领先位置。特别是在"多轮对话"和"主题检测"任务中,得分显著高于蓝色柱状图(Llama-3-8B)和其他竞品模型,印证了其在长文本交互场景中的实用性。
2. 多语言与工具调用能力扩展应用边界
模型支持包括日语、韩语、德语在内的26种语言,可满足跨国企业多语言文档处理需求。同时具备代码执行、网页浏览和自定义工具调用功能,开发者可通过API将其与企业内部系统集成,如自动调取CRM数据生成销售报告,或连接法律数据库进行案例检索。
行业影响:降低企业AI应用门槛
1. 成本优势显著
作为开源模型,GLM-4-9B-Chat-1M可本地化部署,避免按token付费的云端调用成本。某电商平台采用该模型构建智能客服系统后,客服问题解决率提升35%,同时年均节省API调用费用超百万。
2. 垂直领域落地加速
- 法律行业:律师机构利用其长文本能力自动分析合同条款,风险识别效率提升40%
- 医疗领域:辅助医生处理电子病历,从冗长病程记录中提取关键诊断信息
- 内容创作:媒体机构通过多语言功能实现新闻稿件的快速本地化翻译,内容生产效率提升60%
部署指南与注意事项
开发者可通过以下代码快速启动模型(需transformers>=4.44.0):
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("THUDM/glm-4-9b-chat-1m", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
"THUDM/glm-4-9b-chat-1m",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True
).eval()
# 长文本输入示例(此处省略200万字输入)
inputs = tokenizer.apply_chat_template([{"role": "user", "content": "总结以下文档的核心观点"}],
add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(inputs, max_length=2000)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
注意:模型对硬件有一定要求,推荐使用A100或同等算力GPU以保证1M上下文的流畅推理。
未来展望
随着上下文长度向1M扩展,GLM-4系列有望在更多专业领域替代闭源模型。企业可重点关注三个应用方向:基于长上下文的企业知识库构建、集成工具调用的智能工作流自动化,以及多模态交互的客户服务平台。
对于开发者而言,可通过微调进一步优化模型在特定领域的表现——法律机构可训练模型识别合同风险条款,金融企业可增强其财务报表分析能力,从而构建行业专属AI助手。
【免费下载链接】glm-4-9b-chat-1m 项目地址: https://ai.gitcode.com/hf_mirrors/zai-org/glm-4-9b-chat-1m
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







