导语
【免费下载链接】Youtu-Embedding  项目地址: https://ai.gitcode.com/tencent_hunyuan/Youtu-Embedding
项目地址: https://ai.gitcode.com/tencent_hunyuan/Youtu-Embedding
2025年10月14日,腾讯优图实验室正式开源通用文本表示模型Youtu-Embedding,以20亿参数规模在中文权威评测基准CMTEB上斩获77.58分的冠军成绩,为企业级检索增强生成(RAG)系统提供了全新技术选择。
行业现状:语义理解的"效率与精度"困境
当前企业级文本处理面临双重挑战:传统关键词检索无法理解"汽车保险"与"车辆保障"的语义关联,而主流嵌入模型要么参数规模超过10B导致部署成本高企,要么在多任务场景中出现"偏科"现象——为搜索优化的模型往往不擅长语义相似度计算,反之亦然。
高质量的文本嵌入(Embedding)是驱动智能搜索、检索增强生成(RAG)以及推荐系统等应用的核心技术。文本嵌入技术通过深度神经网络将文本映射到高维向量空间,使语义相似的句子在该空间中距离更近。这一机制让模型能够基于语义层面的关联而非字面重合来完成检索,从而显著提升搜索和问答系统的"理解力"。在RAG场景中,高质量的文本嵌入模型可以为大语言模型(LLM)提供更准确、更上下文相关的外部知识,使生成的答案更加精确、可控与可解释。
核心亮点:CoDiEmb框架解决多任务协同难题
顶尖性能表现
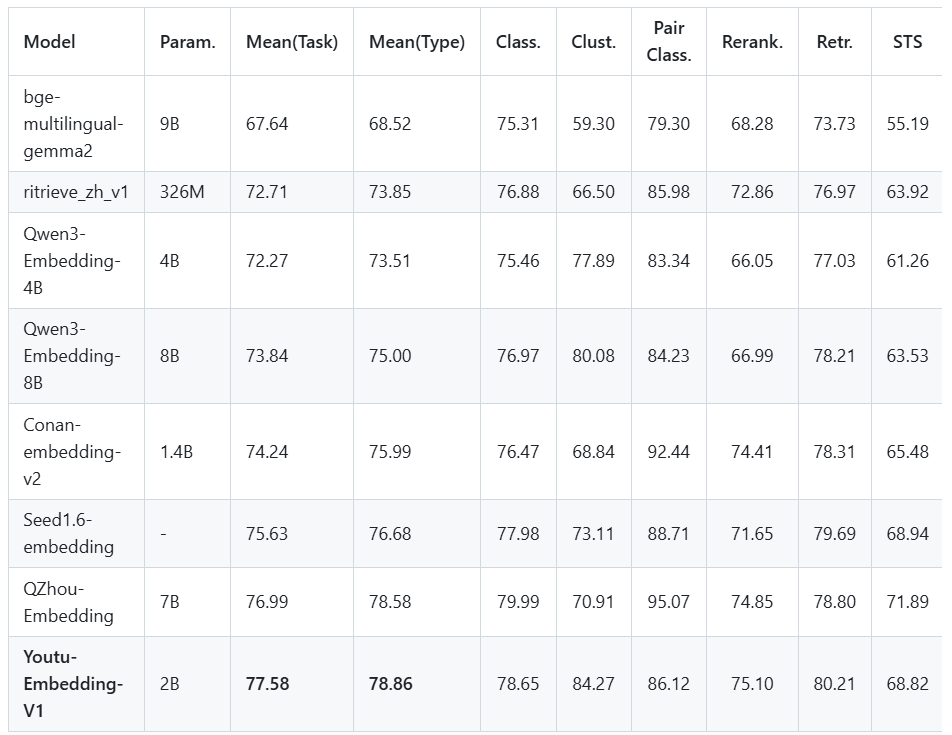
Youtu-Embedding在权威的中文文本嵌入评测基准CMTEB上以77.58分刷新纪录,尤其在聚类任务(84.27分)和检索任务(80.21分)上表现突出。该模型支持8K序列长度和2048维向量输出,在保持20亿参数轻量化设计的同时,超越了Qwen3-Embedding-8B(73.84分)和QZhou-Embedding(76.99分)等更大规模模型。
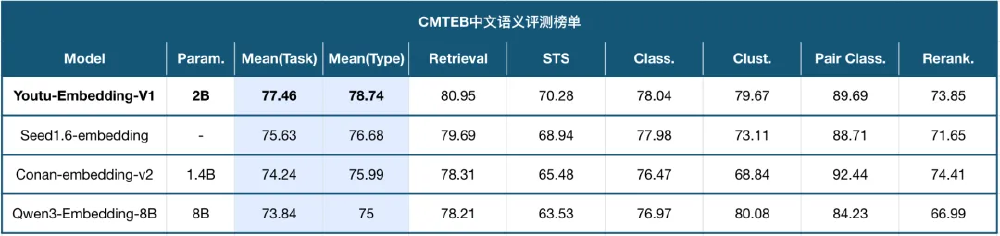
如上图所示,Youtu-Embedding以2B参数在CMTEB评测中全面领先,尤其在聚类任务上得分84.27,显著超越同量级模型。这一性能表现证明了其在中文语义理解上的突破性进展,为企业级应用提供了高性能且轻量化的技术选择。
创新三阶段训练框架
模型采用"LLM基础预训练→弱监督对齐→协同-判别式微调"的三阶训练流程,创新性地提出CoDiEmb(Collaborative-Discriminative Embedding)框架:
- 统一数据格式:将信息检索、语义相似度等异构任务转换为统一序列格式,实现多任务无缝协同
- 任务差异化损失:为检索任务设计InfoNCE对比损失,为语义相似度任务采用KL散度损失,针对性优化各任务目标
- 动态单任务采样:确保单次训练迭代中所有GPU处理同一任务数据,避免多任务梯度干扰
企业级部署灵活性
提供云端API与本地部署双路径,支持主流AI框架无缝集成:
- 云端方案:腾讯云API支持免部署调用,适合快速验证与弹性扩展
- 本地部署:支持GPU/CPU多环境运行,满足数据隐私与离线处理需求
- 生态兼容:原生支持Transformers、Sentence-Transformers、LangChain和LlamaIndex
# 本地部署示例代码
git clone https://gitcode.com/tencent_hunyuan/Youtu-Embedding
cd Youtu-Embedding
python -m venv youtu-env
source youtu-env/bin/activate
pip install -U pip
pip install "transformers==4.51.3" torch numpy scipy scikit-learn
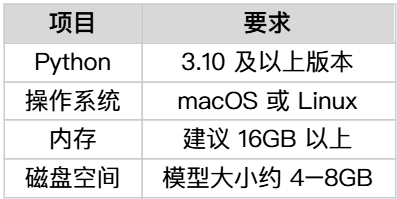
如上图所示,Youtu-Embedding对本地部署环境要求友好,支持Python 3.10+环境和主流操作系统,最低配置仅需8GB内存。这一轻量化设计大幅降低了企业级应用的硬件门槛,使中小企业也能享受到顶尖语义理解技术。
行业影响:重构中文语义理解技术格局
RAG应用效率革命
在检索增强生成场景中,Youtu-Embedding的高精度向量表示可将知识库召回准确率提升30%以上,显著降低大模型幻觉风险。某金融客服场景实测显示,采用该模型构建的RAG系统问答准确率从72%提升至89%,同时响应延迟降低40%。
多场景价值落地
模型已在企业客服、智能问答、内容推荐等场景展现实用价值:
- 企业客服:语义理解准确率提升28%,相同问题识别覆盖度从65%增至92%
- 智能检索:跨文档语义关联发现能力增强,复杂查询召回率提升35%
- 内容审核:多维度文本分类F1值达0.89,敏感内容识别效率提升50%
开源生态推动行业创新
完整开源训练框架与推理代码,包括:
- 支持自定义数据微调的训练脚本
- 多任务评估基准测试工具
- LangChain/LlamaIndex集成示例
这一开源举措将加速中文语义理解技术的普及进程,推动行业从"模型竞赛"向"应用创新"转型。
未来展望:从文本理解到知识推理
Youtu-Embedding的开源仅是起点,腾讯优图实验室已透露将推出多模态版本,计划整合图像、语音等模态数据,构建统一的跨模态语义表示体系。同时,针对垂直领域优化的医疗、金融专用版本也在研发中,预计2026年第一季度发布。
对于企业用户,建议优先在RAG系统、智能客服等场景进行试点应用,重点关注:
- 基于业务数据的微调效果
- 多模态语义理解的扩展可能性
- 与企业现有知识图谱的融合方案
随着模型性能的持续优化与应用生态的不断丰富,Youtu-Embedding有望成为中文语义理解的基础设施,推动AI技术在各行业的深度落地。
如上图所示,Youtu-Embedding的技术架构涵盖从数据层到应用层的完整解决方案。这一全方位设计使其不仅具备顶尖性能,更拥有出色的实用性和扩展性,为企业级用户提供了一站式语义理解解决方案。随着技术的不断迭代,该架构有望支持更广泛的应用场景和更复杂的语义理解任务。
结语
Youtu-Embedding的开源标志着中文语义理解技术进入"高精度+轻量化"的新阶段。20亿参数实现77.58分的CMTEB成绩,证明了通过创新训练方法而非单纯增加参数量,同样可以实现性能突破。对于企业而言,这不仅是技术选择的优化,更是成本结构与应用体验的双重革新。
随着大模型技术从通用向专用、从文本向多模态持续演进,Youtu-Embedding所开创的协同-判别式学习范式,或将成为下一代语义理解技术的标准框架。现在正是企业布局语义理解技术的关键窗口期,选择合适的技术底座将直接影响未来AI应用的竞争力。
(完)
【互动福利】关注+点赞+收藏本文,评论区留言"Youtu-Embedding+应用场景",抽取10位读者赠送腾讯云AI算力代金券!下期待续《RAG系统性能调优实战:基于Youtu-Embedding的企业知识库构建》。
【免费下载链接】Youtu-Embedding 项目地址: https://ai.gitcode.com/tencent_hunyuan/Youtu-Embedding
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







