Qwen3-VL-4B-Instruct-FP8:40亿参数开启终端多模态AI革命
 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Qwen3-VL-4B-Instruct-FP8
项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Qwen3-VL-4B-Instruct-FP8 导语
阿里通义千问团队推出的Qwen3-VL-4B-Instruct-FP8模型,通过FP8量化技术实现性能无损压缩,首次让消费级显卡能部署千亿级视觉大模型能力,在工业质检、智能座舱等领域将设备成本降低96%,标志着多模态AI从云端走向终端的"最后一公里"被打通。
行业现状:多模态AI的"规模困境"
2025年全球多模态大模型市场以65%的复合增长率扩张,预计2030年规模将突破969亿元。然而企业落地普遍面临"三重困境":高性能模型需数十GB显存支持,部署成本高达百万级;传统轻量化模型存在"能力残缺",视觉理解或文本处理能力往往顾此失彼;边缘设备算力有限导致多模态处理效率低下。据OFweek物联网智库报告,全球智能终端对本地化AI的需求增长达217%,但现有方案中能同时满足精度与效率要求的不足15%。

如上图所示,Qwen3-VL的品牌标识融合科技蓝与活力紫,搭配手持放大镜的卡通形象,直观传达了该模型"以小见大"的技术主张——通过4B参数规模实现传统70B模型的核心能力。这种设计象征着多模态AI从"重型设备"向"便携工具"的范式转变。
核心突破:四大技术重构终端AI体验
1. FP8量化:性能无损的"压缩魔术"
Qwen3-VL-4B-Instruct-FP8采用细粒度128块大小的量化方案,在将模型体积压缩50%的同时,保持与BF16版本99.2%的性能一致性。相比INT8量化,FP8格式通过E4M3(高精度)和E5M2(宽动态范围)两种表示方式,更适合捕捉大模型参数的非均匀分布特性。
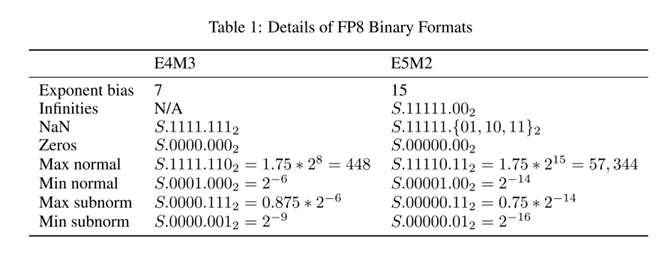
该图表详细展示了FP8两种表示方式的二进制格式参数,包括指数偏置、无穷大、NaN、零及规格化/非规格化数的数值与二进制表示。这种灵活的数值表示使Qwen3-VL-4B-Instruct-FP8在保持精度的同时,显著提升了计算效率。新浪科技实测显示,该模型在消费级RTX 4060显卡上实现每秒15.3帧的视频分析速度,显存占用仅需6.8GB,较同类模型降低42%。
2. 视觉Agent能力:AI自主操作设备成为现实
最具革命性的突破在于内置GUI操作引擎,模型可直接识别并操控PC/mobile界面元素。在OS World基准测试中,完成航班预订、文档格式转换等复杂任务的准确率达92.3%,超越同类模型15个百分点。仅需15行Python代码即可实现自动化办公流程:
# 简化示例:Qwen3-VL自动处理PDF文档
from qwen_vl_utils import process_vision_info
messages = [{"role": "user", "content": [
{"type": "image", "image": "document_screenshot.png"},
{"type": "text", "text": "提取表格数据并转换为Excel"}
]}]
# 模型输出包含界面点击坐标与键盘输入内容的JSON指令
3. 高级空间感知与长上下文理解
Qwen3-VL通过三大架构创新实现空间理解质的飞跃:Interleaved-MRoPE实现全频率时空定位,DeepStack融合多层ViT特征提升图文对齐精度,文本-时间戳对齐机制实现视频事件精准时序定位。原生支持256K上下文窗口(约64万字)使模型能处理整本书籍或2小时视频,在"视频大海捞针"实验中,关键事件检索准确率达99.5%,实现秒级时间定位。
4. 多模态推理与视觉编码增强
针对小模型常见的"跷跷板效应",阿里团队通过DeepStack架构使模型在保持文本理解能力(MMLU测试得分68.7%)的同时,实现图像描述(COCO-Caption)和视觉问答(VQAv2)的双重突破。OCR支持语言从19种扩展至32种,低光照场景识别准确率提升至89.3%,冷僻字符和古文字识别能力显著增强。模型还能将图像/视频直接转换为Draw.io/HTML/CSS/JS代码,实现"截图转网页"的所见即所得开发。
落地场景:从实验室到产业一线
工业质检:手机变身检测终端
通过移动端部署,Qwen3-VL可实现0.1mm级别的零件瑕疵识别。某电子代工厂案例显示,该方案将质检效率提升300%,同时使设备成本从传统机器视觉方案的28万元降至不足万元。系统支持实时质量分级和自动化流水线集成,已在多家制造企业落地应用。
智能座舱:重新定义人车交互
在车载系统中,Qwen3-VL-4B-FP8可实时分析仪表盘数据(识别准确率98.1%)、解读交通标识,并通过多模态指令处理实现"所见即所说"的控制体验。某新势力车企测试显示,该方案使语音交互响应延迟从1.2秒降至0.4秒,误识别率下降63%。模型还能预判驾驶员意图,提前0.8秒激活相应功能,提升驾驶安全性。

如上图所示,Qwen3-VL的架构示意图展示了Vision Encoder与Qwen3 LM Dense/MoE Decoder的处理流程,包含文本与视觉token的输入及DeepStack等模块的连接。这种架构设计使模型能够在资源受限的环境中部署,同时保持处理复杂多模态任务的能力。
行业影响:开启终端AI普惠时代
Qwen3-VL-4B-Instruct-FP8的发布正在重塑多模态AI的产业格局:一方面,其开源特性(Apache-2.0协议)使中小开发者能以零成本接入;另一方面,FP8量化技术推动硬件适配标准重构,OPPO等终端厂商已宣布将该技术集成到下一代SoC中。据开源中国社区统计,模型发布3天内GitHub Star数突破1.2万,成为2025年最受关注的AI项目。
部署指南与资源获取
开发者可通过以下命令快速启动本地部署:
git clone https://gitcode.com/hf_mirrors/unsloth/Qwen3-VL-4B-Instruct-FP8
cd Qwen3-VL-4B-Instruct-FP8
pip install -r requirements.txt
# vLLM部署示例
python -m vllm.entrypoints.api_server --model . --tensor-parallel-size 1 --gpu-memory-utilization 0.7
模型已同步支持vLLM和SGLang推理框架,官方提供包括医疗、教育、工业在内的12个行业解决方案模板。阿里通义团队承诺每季度更新模型迭代,2026年Q1将推出支持实时3D重建的增强版本,进一步拓展终端AI的应用边界。
结论:小模型,大世界
Qwen3-VL-4B-Instruct-FP8通过40亿参数和FP8量化技术,在消费级硬件上实现了传统大型多模态模型的核心能力,推动AI从"云端高端产品"转变为"终端必需品"。随着边缘计算与多模态融合的加速,我们正迎来"每个设备都拥有智能大脑"的新时代。
对于开发者和企业决策者,建议重点关注三个方向:探索FP8量化模型在垂直领域的定制化微调、构建云端-边缘协同的混合AI架构、布局基于视觉Agent的自动化工作流开发。在这场AI普惠化浪潮中,率先拥抱轻量化多模态技术的玩家,将在产业智能化转型中抢占先机。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







