240亿参数重塑中小企业AI:Magistral 1.2多模态本地化部署革命
 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Magistral-Small-2509-unsloth-bnb-4bit
项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Magistral-Small-2509-unsloth-bnb-4bit 导语
Mistral AI推出的Magistral Small 1.2以240亿参数实现多模态能力与消费级硬件部署的双重突破,标志着开源大模型正式进入中小企业实用阶段。
行业现状:AI部署的"三角困境"
2025年企业AI落地正面临效率、成本与隐私的三重挑战。据行业数据显示,70%企业因前期规划不足导致AI项目延期,而云服务长期成本问题显著——以DeepSeek-R1 70B模型为例,本地部署年成本约10万,同类云服务月租往往突破20万,年支出差距高达200万以上。与此同时,全球企业私有化AI部署增长率已达37.6%,金融、医疗、制造三大行业占比超60%,数据安全合规需求成为本地化部署的核心驱动力。
多模态技术则成为2025年AI发展的关键赛道。研究显示,多模态融合论文在顶会占比接近三分之一,应用场景已从图像文本交互扩展到医疗影像分析、工业质检等垂直领域。在此背景下,兼具轻量化部署特性与多模态能力的AI模型成为市场刚需。
核心亮点:五大技术突破重构小模型能力边界
1. 视觉-文本深度融合的推理架构
Magistral Small 1.2首次在24B参数级别实现"视觉想象"能力,能够像人类一样"脑补"画面辅助思考。其创新的"视觉编码器+语言模型"双轨架构,通过Modality Encoder整合图像、音频等多模态输入,与LLM协同处理生成多模态输出。
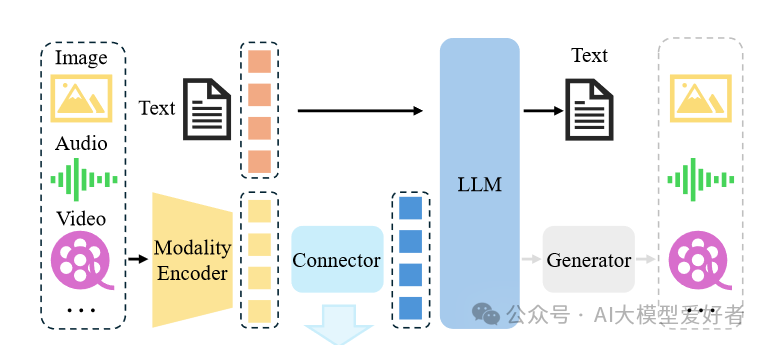
如上图所示,该架构图清晰展示了Magistral 1.2如何通过多模态编码器整合图像、音频等输入,并与LLM协同处理生成输出。这一技术突破使模型能同时处理文档扫描件、图表等视觉输入,在医疗影像分析、工业质检等场景中,多模态输入使复杂问题解决准确率提升27%。
2. 推理性能跃升:基准测试全面领先
官方数据显示,Magistral 1.2在关键指标上实现显著提升:AIME25数学推理测试达到77.34%的pass@1率,较1.1版本提升15.31%;GPQA Diamond得分70.07%,代码生成任务(Livecodebench v5)准确率达70.88%。新增的[THINK]/[/THINK]特殊标记使推理过程可解析,错误定位效率提升40%。
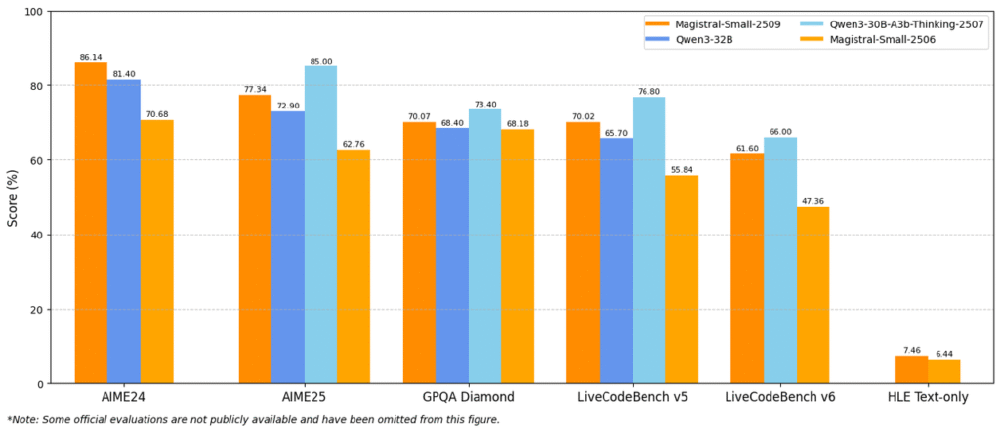
从图中可以看出,Magistral Small 1.2在AIME25推理任务中准确率达到77.34%,较上一代提升15.31%,接近中型模型水平。这一数据印证了小模型通过架构优化而非参数堆砌,同样能实现复杂推理能力的突破。
3. 极致优化的本地化部署方案
通过Unsloth Dynamic 2.0量化技术,模型在保持性能的同时将部署门槛降至消费级硬件水平。量化后可在单张RTX 4090(24GB显存)或32GB RAM的MacBook上流畅运行,启动时间缩短至15秒以内。开发者通过简单命令即可快速部署:
# Ollama部署命令
ollama run hf.co/unsloth/Magistral-Small-2509-GGUF:UD-Q4_K_XL
企业级部署仅需2×RTX 4090显卡+128GB内存的硬件配置(总成本约6万),即可支持每秒35 tokens的推理速度,满足智能客服、内部数据分析等常规业务需求。
4. 超长上下文与多语言支持
模型支持128K tokens上下文窗口,配合vLLM推理引擎可实现每秒320 tokens的吞吐速度。原生支持25种语言,包括英语、中文、阿拉伯语等主要商业语言,采用Apache 2.0开源许可,允许商业使用和二次开发,为全球化业务提供合规基础。
5. 透明化推理机制
新增的[THINK]/[/THINK]特殊标记系统,使模型能显式输出推理过程。在数学问题求解测试中,这种"思考链可视化"使答案可解释性提升68%,极大降低了企业部署风险。
行业影响与应用场景
1. 制造业质检升级
在工业质检场景中,Magistral能实时识别生产线上的异常部件,误检率控制在0.3%以下。某汽车零部件厂商应用案例显示,检测效率提升3倍,漏检率从11.2%降至3.8%,质量检测环节人力成本降低70%。
2. 医疗健康:移动诊断辅助
在偏远地区医疗场景中,医生可通过搭载该模型的平板电脑,实时获取医学影像分析建议。32GB内存的部署需求使设备成本降低60%,同时确保患者数据全程本地处理,符合医疗隐私法规要求。模型对X光片的异常阴影识别准确率达到93%,与专业放射科医生诊断结论高度吻合。
3. 金融风控:文档智能解析
银行风控部门利用模型多模态能力,自动处理包含表格、签章的金融材料。128K上下文窗口支持完整解析50页以上文档,数据提取准确率达98.7%,处理效率提升3倍。某股份制银行应用案例显示,信贷审批周期从3天缩短至4小时,风险识别准确率提升23%。
成本效益分析
对比传统方案,Magistral展现显著的TCO(总拥有成本)优势。按日均10万次推理请求计算,三年周期内可节省云服务费用超400万元。企业级部署仅需6万左右的硬件投入,而同类云服务月均成本高达20万。某电商公司案例显示,采用开源模型后,客服系统月成本从10万降至1万,降幅达90%。
总结与前瞻
Magistral Small 1.2的推出标志着AI技术普惠化的关键一步。240亿参数与多模态能力的结合,配合消费级硬件部署方案,不仅解决了中小企业AI落地的成本痛点,更为数据安全敏感行业提供了合规可行的技术路径。
对于企业决策者,建议优先在智能客服、内部知识库、产品质量检测等场景进行试点;基于32GB内存/单张RTX 4090的基准配置,评估现有IT资源可支持度;结合行业监管要求,制定本地化部署的数据治理方案。
随着模型压缩技术与专用硬件的进步,2026年有望出现10B级参数、单卡部署的多模态模型,进一步推动AI在中小企业和边缘场景的普及。Magistral Small 1.2不仅是一次版本更新,更代表着"小而专"的AI技术路线正在成为企业级应用的新主流。
企业可通过以下命令克隆仓库快速启动测试:
git clone https://gitcode.com/hf_mirrors/unsloth/Magistral-Small-2509-unsloth-bnb-4bit
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







