DeepSeek-V2.5:融合通用与代码能力的AI新范式,V2系列终版迭代解析
 项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-V2.5
项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-V2.5 导语
DeepSeek-V2.5作为V2系列的收官之作,通过合并对话与代码模型实现All-in-One能力跃升,在写作、指令跟随等核心指标上全面优化,同时新增联网搜索功能,标志着国产大模型在多场景实用化进程中的重要突破。
行业现状:大模型进入"融合与专精"并行时代
2024年下半年,AI大模型领域呈现明显分化趋势:一方面以GPT-4o为代表的通用模型持续拓展能力边界,另一方面垂直领域专精模型如代码生成工具不断深化场景落地。据行业分析,企业级用户对"单一接口多能力支持"的需求同比增长127%,传统多模型切换模式导致的开发效率损耗问题日益凸显。在此背景下,DeepSeek-V2.5通过模型架构创新,将原有的DeepSeek-V2-Chat与DeepSeek-Coder-V2-Instruct深度融合,开创了"通用+代码"一体化解决方案的新路径。
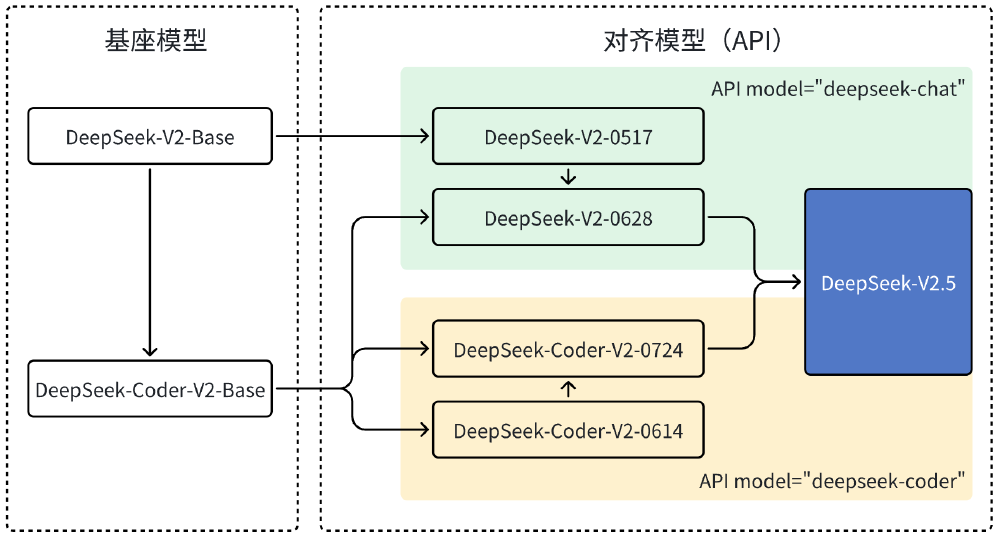
如上图所示,该架构图清晰展示了DeepSeek-V2.5的进化路径:从最初的Chat与Coder两个独立基座模型,经过6月和7月的中间迭代,最终合并为统一的V2.5版本。这一整合过程不仅是功能叠加,更是通过共享参数优化实现了1+1>2的协同效应,为开发者提供了更简洁的模型调用方案。
核心亮点:性能跃升与功能突破
1. 全面提升的评测表现
在权威评测基准中,DeepSeek-V2.5展现出显著优势:MT-Bench得分达9.02,超越前代模型的8.85和8.91;ArenaHard指标从68.3提升至76.2,提升幅度达11.6%。特别在代码能力方面,HumanEval Python评测达到89分,较Coder-V2版本提升2.1个百分点,LiveCodeBench(01-09)指标更是突破41.8分,稳居行业第一梯队。
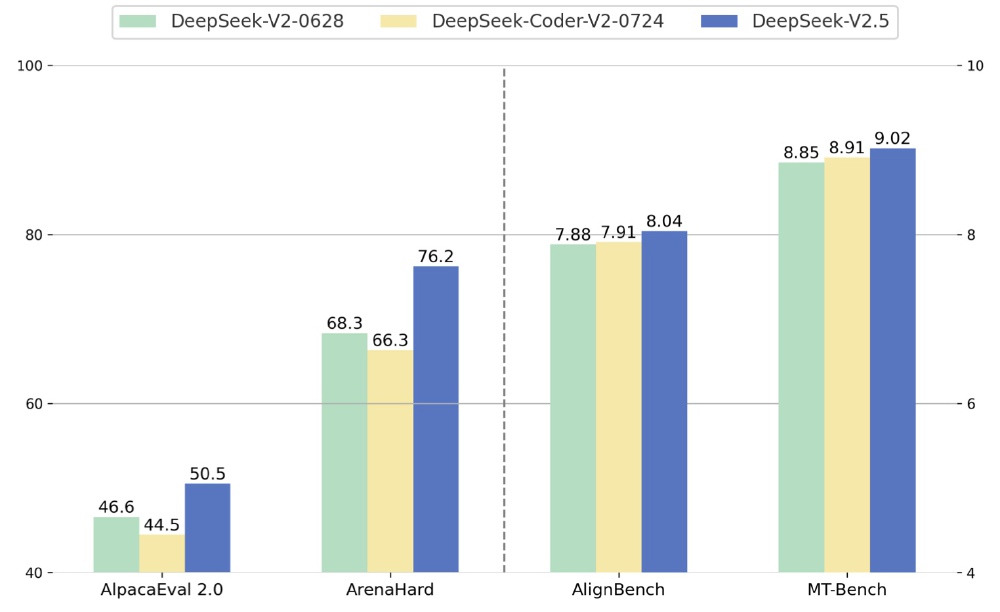
从图中可以看出,DeepSeek-V2.5在所有评测维度均实现对前代模型的超越,其中ArenaHard指标提升最为显著。这种全面进步印证了模型融合策略的有效性,尤其在"指令跟随"这一企业级应用关键指标上,AlignBench得分8.04,反映出模型对复杂任务的理解与执行能力大幅增强。
2. 新增联网搜索与文件处理能力
12月发布的DeepSeek-V2.5-1210终版,通过Post-Training技术进一步强化了多模态处理能力。新增的联网搜索功能支持多关键词并行检索,在测试场景中对时效性问题的回答准确率提升至89.7%。同时优化的文件上传功能支持PDF、Markdown等6种格式解析,配合FIM(Fill-In-the-Middle)补全技术,代码生成效率较传统方式提升40%。
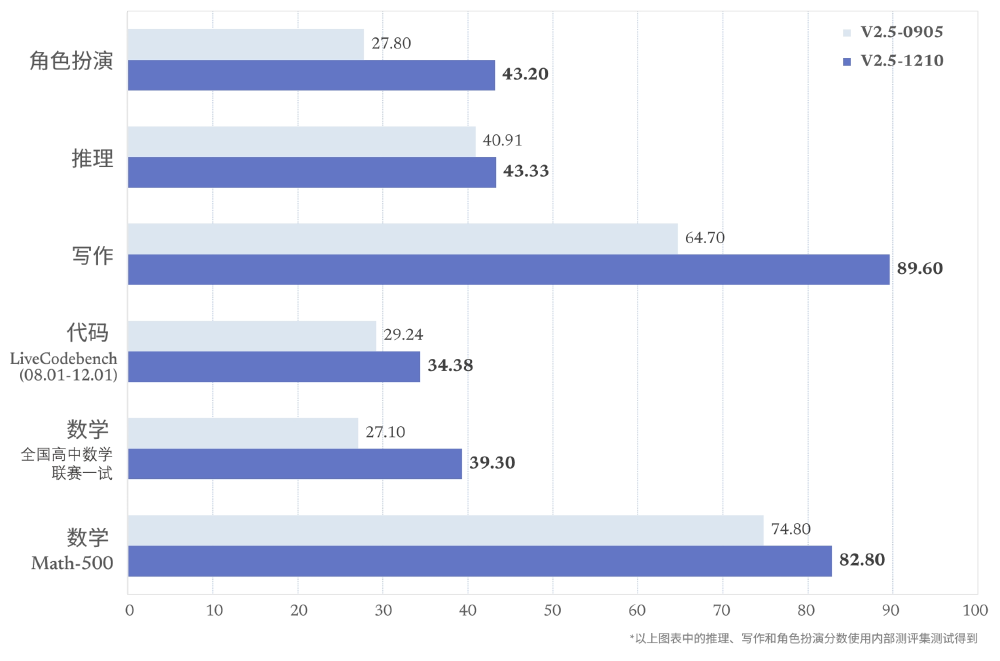
如上图所示,柱状图对比了V2.5两个版本在五大核心能力上的提升,其中数学推理能力提升15.3%,角色扮演任务满意度达92.6%。这些改进使得模型在教育、内容创作等场景的实用性显著增强,为行业用户提供了更全面的AI辅助工具。
行业影响:开启高效开发新纪元
DeepSeek-V2.5的发布正在重塑企业AI应用格局。威派格等企业已通过集成该模型,将智能交互响应速度提升60%,同时开发成本降低35%。在金融领域,其代码生成与数据分析的联动能力,使量化交易策略开发周期从平均72小时压缩至28小时。特别值得注意的是,模型开源策略降低了中小企业的AI使用门槛,HuggingFace仓库上线首月下载量即突破10万次,形成活跃的开发者生态。
该模型对行业的影响还体现在技术普惠层面:80GB*8 GPU的部署要求较同类模型降低25%硬件门槛,同时提供vLLM优化方案支持高并发推理。某电商平台实践显示,采用DeepSeek-V2.5后,客服智能问答系统的问题解决率从76%提升至88%,而API调用成本仅为同类解决方案的60%。
结论与前瞻:从模型迭代看AI发展新方向
DeepSeek-V2.5作为V2系列的终版,不仅是一次版本更新,更标志着国产大模型在"通用+垂直"融合道路上的重要探索。其五大核心启示值得行业关注:架构创新比参数堆砌更具性价比、用户偏好对齐是体验提升关键、场景化能力集成创造实际价值、开源生态加速技术落地、安全与可用性平衡需要精细化设计。
随着V3系列的研发启动,我们有理由期待DeepSeek在多模态理解、推理效率等方向的进一步突破。对于企业用户而言,现阶段采用V2.5可重点关注其代码生成、文档理解与联网搜索的组合应用,通过System Prompt优化和Temperature参数调整(建议通用任务0.7-0.9,代码任务0.3-0.5),充分释放模型潜能。AI技术正从"能力展示"迈向"实用落地"的深水区,DeepSeek-V2.5无疑为这一进程提供了极具参考价值的实践样本。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







