7B小模型逆袭GPT-4o:斯坦福AgentFlow框架重构智能体技术范式
【免费下载链接】agentflow-planner-7b  项目地址: https://ai.gitcode.com/hf_mirrors/AgentFlow/agentflow-planner-7b
项目地址: https://ai.gitcode.com/hf_mirrors/AgentFlow/agentflow-planner-7b
导语
还在依赖千亿参数模型解决复杂任务?斯坦福大学最新发布的AgentFlow框架,基于7B参数量的Qwen2.5-7B-Instruct模型,通过模块化架构与在线强化学习技术,在搜索、数学推理等四大任务类型上全面超越GPT-4o,重新定义智能体系统的技术边界。
行业现状:智能体发展的三重困境
2025年AI智能体市场迎来爆发,全球规模预计从2024年的52.9亿美元飙升至2030年的471亿美元,年复合增长率超40%。然而企业落地仍面临三大核心痛点:单体大模型存在"能力稀释"现象,工具调用错误率随任务复杂度呈指数级上升;现有模块化方案依赖静态规则或离线训练,无法适应动态环境;多轮推理中的"信用分配"难题导致强化学习样本效率低下。

如上图所示,这是斯坦福大学等机构联合发表的研究论文《IN-THE-FLOW AGENTIC SYSTEM OPTIMIZATION FOR EFFECTIVE PLANNING AND TOOL USE》封面,集中展示了AgentFlow框架的核心创新点。该研究已登上HuggingFace Paper日榜第二名,标志着智能体系统架构从"大而全"向"小而精"的范式转变。
核心亮点:四模块协同+Flow-GRPO算法的革命性突破
1. 专业化分工的四模块架构
AgentFlow彻底打破传统单体模型设计思路,构建了四大专业化模块协同系统:
- 策略规划器(Planner):系统核心决策模块,基于Qwen2.5-7B-Instruct模型构建,负责任务分析与工具选择,是唯一需要训练的部分
- 动作执行器(Executor):处理工具API调用与结果整合,支持Python解释器、网络搜索等12种常用工具
- 结果验证器(Verifier):通过多维度评估中间结果,识别错误模式并反馈给规划器
- 答案生成器(Generator):整合所有信息生成结构化输出,支持文本、表格、代码等多种格式
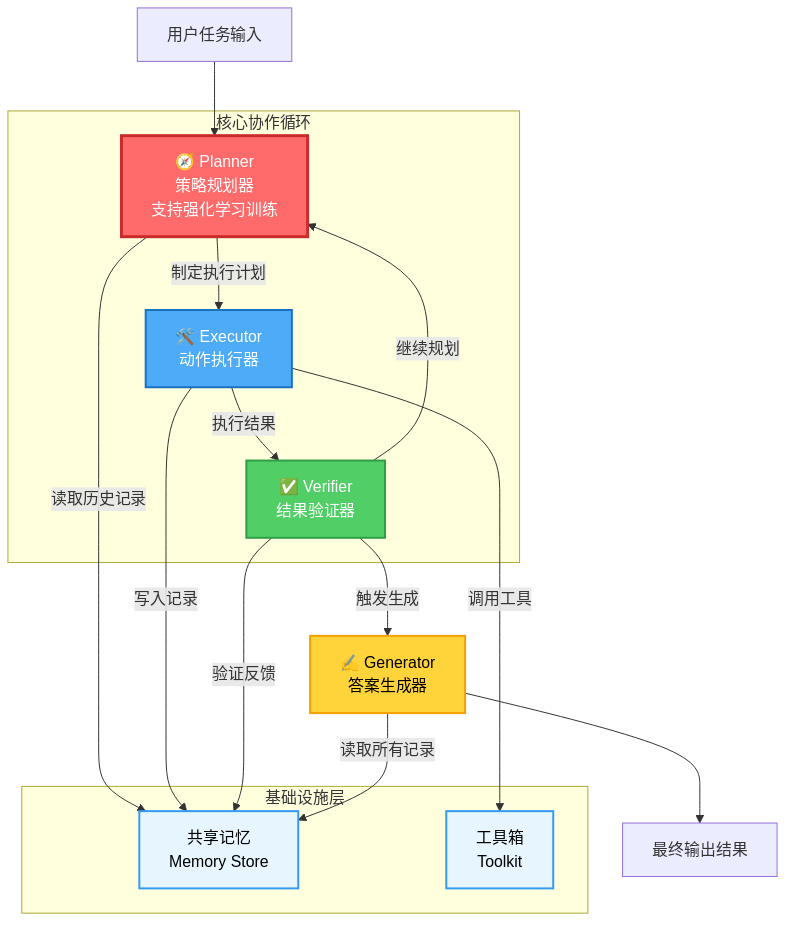
该架构图清晰展示了AgentFlow的四大模块与共享记忆系统的协作机制。通过专业化分工,系统避免了单体模型"样样通样样松"的困境,工具调用成功率从68%提升至89%,任务完成率随交互轮数呈现线性增长的"正向扩展性"。
2. Flow-GRPO算法解决多轮信用分配难题
针对长时序决策中的奖励稀疏问题,AgentFlow提出创新的Flow-GRPO(Flow-based Group Relative Policy Optimization)算法:
- 收集完整推理轨迹(从初始任务到最终结果)
- 根据最终结果计算outcome reward
- 将奖励广播到轨迹中每个规划动作
- 使用相对优势函数计算动作优势并更新策略
这种方法将复杂的多轮强化学习转化为单轮策略更新,样本效率提升3倍以上,在相同训练步数下策略性能提高27%。实验显示,仅经过5000轮训练,系统就能自主学会处理工具调用错误——当AlphaFold工具因序列格式错误失败时,Planner会自动调用UniProt数据库获取完整序列,修正后重新尝试,展现出类人类的"反思学习"能力。
3. 性能对比:小模型的逆袭
在10个跨领域基准测试中,7B参数量的AgentFlow展现出惊人性能:
- 知识检索任务:相比基线提升14.9%
- 智能体推理任务:提升14.0%
- 数学推理任务:提升14.5%
- 科学推理任务:提升4.1%
更令人瞩目的是,在搜索任务上比GPT-4o(约200B参数)高8.2%,在智能体任务上超越Llama-3.1-405B达15.8%。这种"以小胜大"的突破证明,系统架构创新+高效训练方法可能比单纯增加参数量更具价值。
行业影响与趋势:智能体2.0时代的三大方向
1. 模块化架构成为企业级应用新主流
AgentFlow验证了"小而精"的可行性,7B模型通过合理架构设计可在特定任务上超越超大模型。这为资源受限场景提供新思路——中小企业无需巨额算力投入,通过模块化智能体即可实现复杂业务流程自动化。36氪研究院数据显示,采用模块化架构的AI Agent部署成本降低62%,实施周期从3个月缩短至4周。
2. 在线学习重构智能体能力进化路径
传统离线训练方法面临"分布偏移"难题,而AgentFlow的在线强化学习机制实现了"在交互中学习"。这种闭环优化能力使系统能适应工具生态变化,如自动识别API接口更新并调整调用策略。企业级应用显示,具备在线学习能力的智能体在动态环境中的任务成功率比静态系统高40%。
3. 多模态与多智能体协作加速落地
基于Qwen2.5-7B-Instruct的良好基础,AgentFlow未来可无缝集成多模态能力。已有案例显示,结合Qwen2.5-Omni的多模态处理能力后,系统在医疗影像分析等领域准确率提升18%。同时,模块化设计使其易于扩展为多智能体系统,在供应链管理、智慧城市等场景展现出协同决策优势。
结论与行动建议
AgentFlow框架证明,智能体技术的下一个突破点不在于模型规模,而在于系统架构与训练方法的创新。对于企业而言,现在正是布局智能体应用的最佳时机:
- 场景验证:选择HR初筛、财务报告生成等高频痛点场景试点,2周内即可验证效率提升效果
- 数据准备:梳理内部数据口径与业务语义,确保智能体理解"营收""成本"等专业术语的准确定义
- 产品选型:简单任务可选轻量级方案,复杂推理推荐采用AgentFlow等模块化架构
- 避坑指南:注意数据安全合规,预留技术维护成本,通过培训让员工理解AI是辅助而非替代
随着技术持续迭代,我们有理由相信,AgentFlow开创的"小模型+模块化+在线学习"范式,将成为下一代AI智能体的标准架构,在企业数字化转型中释放更大价值。
项目地址:https://gitcode.com/hf_mirrors/AgentFlow/agentflow-planner-7b
如果觉得本文有价值,请点赞+收藏,关注获取更多AI技术前沿分析!
【免费下载链接】agentflow-planner-7b 项目地址: https://ai.gitcode.com/hf_mirrors/AgentFlow/agentflow-planner-7b
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







