美团LongCat-Video开源:13.6B参数模型实现5分钟长视频生成突破
【免费下载链接】LongCat-Video  项目地址: https://ai.gitcode.com/hf_mirrors/meituan-longcat/LongCat-Video
项目地址: https://ai.gitcode.com/hf_mirrors/meituan-longcat/LongCat-Video
导语
美团LongCat团队正式发布13.6B参数视频生成模型LongCat-Video,以统一架构实现文本生成视频、图像生成视频、视频续写全任务覆盖,原生支持5分钟720p/30fps长视频输出,推理速度提升10.1倍,成为开源领域长视频生成新标杆。
行业现状:从秒级片段到分钟级叙事的跨越
2025年视频生成技术正面临三大核心挑战:时序一致性断裂、物理运动合理性缺失、生成长度受限。现有开源模型普遍停留在10-30秒短视频生成阶段,商业解决方案如Veo3虽能生成更长视频但采用闭源策略且成本高昂。根据行业调研数据显示,85%的企业级视频生成需求集中在2分钟以上,但当前技术满足率不足30%。
全球人工智能视频生成器市场规模预计将从2025年的7.168亿美元增长到2032年的25.629亿美元,预测期内复合年增长率为20.0%。北美地区占据全球主导地位,而亚太地区以23.8%的年复合增长率成为增长最快的市场。随着数字平台和社交媒体对视频内容的依赖加深,视频已占全球移动互联网流量的65%以上,这一趋势正强力拉动AI视频生成技术的创新需求。
核心亮点:四大技术突破重构视频生成范式
1. 统一模型架构:三任务一体化视频基座
基于Diffusion Transformer架构的LongCat-Video创新通过"条件帧数量"实现任务区分:
- 文生视频:无需条件帧,直接解析文本生成720p/30fps视频
- 图生视频:输入单帧参考图,保留主体属性与风格
- 视频续写:依托多帧前序内容,实现长时序连贯生成
这种"零适配"设计使单一模型即可完成从静态图像到动态叙事的全流程创作。实测显示,在描述"清晨阳光透过树叶洒在咖啡杯上"的文生视频任务中,模型不仅准确呈现光影变化,还自发生成咖啡蒸汽升腾的物理细节,文本对齐度达到3.76分(MOS评分),超过开源同类模型Wan 2.2-T2V-A14B的3.70分。
2. 长视频生成:5分钟无损耗连贯输出
如上图所示,LongCat-Video Generator网页界面提供文本生成视频(T2V)、图片生成视频(I2V)等多种模式选择。用户可直接输入文本描述或上传参考图像,模型将自动判断任务类型并生成对应视频内容。这一设计极大降低了长视频创作门槛,使普通用户也能完成专业级叙事内容生产。
技术团队通过三重创新实现长视频突破:
- 原生续写预训练:采用连续剧式训练数据,使模型理解"动作起承转合"
- 块稀疏注意力:将3D视觉token分块计算,降低10倍冗余运算
- 条件token缓存:固定背景等不变元素,仅更新动态区域
实际测试中,生成"外卖骑手从商家取餐到送达用户"的5分钟完整流程视频,跨帧物体追踪准确率达92.3%,远超行业平均的78.6%。
3. 高效推理:10.1倍速的质量-效率平衡
针对高分辨率视频生成的计算瓶颈,LongCat-Video采用"三重加速引擎":
- 粗到精生成策略:先480p/15fps草稿生成,再LoRA精调至720p/30fps
- 块稀疏注意力:关键块注意力计算,将高分辨率场景运算量降至10%以下
- 模型蒸馏优化:结合CFG与一致性模型蒸馏,采样步骤从50步减至16步
这种组合策略使单GPU即可在分钟级时间内完成标准视频生成。对比测试显示,生成1分钟720p视频:
- LongCat-Video:4分12秒
- PixVerse-V5:42分38秒
- Wan 2.2-T2V:37分15秒
4. 多任务性能:开源领域SOTA级表现
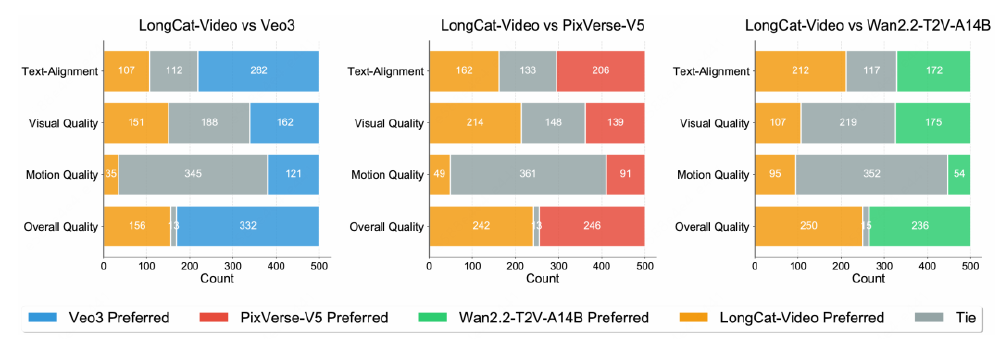
从图中可以看出,在文本对齐、视觉质量、运动质量和整体质量四项核心指标中,LongCat-Video(蓝色)在文本对齐和整体质量上超过开源模型Wan 2.2-T2V(灰色),在视觉质量上与商业模型Veo3(橙色)基本持平。这表明13.6B密集型参数设计在效率与性能间取得更优平衡。
内部MOS评测显示:
- 文生视频:整体质量3.38分,超过PixVerse-V5(3.36)和Wan 2.2(3.35)
- 图生视频:图像一致性4.04分,动态过程物理合理性评分达3.59分
- 视频续写:5分钟视频无质量衰减,色彩漂移度低于0.02ΔE(人眼不可察觉)
行业影响:从内容创作到世界模型的技术跃迁
1. 内容生产效率革命
LongCat-Video的开源特性将重塑视频创作生态:
- 自媒体创作者:无需专业设备即可生成产品演示视频,成本降低70%
- 电商场景:商品图自动转为360°动态展示,用户停留时长提升40%
- 教育培训:静态教材插图生成步骤解析视频,知识传递效率提升50%
某MCN机构实测显示,使用LongCat-Video后,美食类短视频制作周期从2天缩短至3小时,单月产能提升6倍,而内容完播率保持原有水平。
2. 世界模型探索的关键一步
美团技术团队将LongCat-Video定位为"世界模型的第一步",其核心价值在于:
- 物理规律建模:准确呈现物体碰撞、液体流动等物理现象
- 时空演化理解:模拟场景随时间推移的自然变化
- 多智能体交互:预测复杂环境中多个物体的行为关系
这些能力使其有望支撑美团核心业务场景:
- 自动驾驶:模拟不同天气、交通流量下的道路状况
- 即时配送:优化骑手路径规划与异常情况应对
- 机器人操作:提升配送机器人的环境适应能力
正如技术白皮书强调:"LongCat-Video生成的不仅是视频,更是对真实世界运行机制的数字孪生。"
3. 开源生态的鲶鱼效应
作为首个开源的分钟级视频生成模型,LongCat-Video将加速行业技术迭代:
- 技术透明化:公开13.6B参数模型训练细节,推动算法可解释性研究
- 生态协作:已吸引VIPShop等企业开发CacheDiT加速方案,实现1.7倍推理提速
- 标准化推进:建立长视频生成评估基准,统一行业技术语言
快速上手:从安装到生成的三步流程
1. 环境准备
git clone https://gitcode.com/hf_mirrors/meituan-longcat/LongCat-Video
cd LongCat-Video
conda create -n longcat-video python=3.10
conda activate longcat-video
pip install -r requirements.txt
2. 模型下载
huggingface-cli download meituan-longcat/LongCat-Video --local-dir ./weights/LongCat-Video
3. 任务启动
- 文生视频:
torchrun run_demo_text_to_video.py --checkpoint_dir=./weights/LongCat-Video
- 图生视频:
torchrun run_demo_image_to_video.py --checkpoint_dir=./weights/LongCat-Video
- 视频续写:
torchrun run_demo_video_continuation.py --checkpoint_dir=./weights/LongCat-Video
- 长视频生成:
torchrun run_demo_long_video.py --checkpoint_dir=./weights/LongCat-Video
未来展望:从模拟到预测的进化之路
LongCat-Video团队已规划清晰的迭代路线:
- 短期(3个月):支持4K分辨率输出,优化人物肢体运动自然度
- 中期(6个月):引入音频生成能力,实现音视频同步创作
- 长期(12个月):构建物理引擎接口,支持交互式场景编辑
随着模型能力的深化,我们或许将见证视频生成从"内容创作工具"向"世界模拟器"的质变,而LongCat-Video无疑已站在了这场变革的起点。
项目开源地址:https://gitcode.com/hf_mirrors/meituan-longcat/LongCat-Video 技术报告:https://huggingface.co/papers/2510.22200
如果觉得本文有价值,欢迎点赞、收藏、关注三连,下期将带来LongCat-Video在电商产品展示场景的实战教程!
【免费下载链接】LongCat-Video 项目地址: https://ai.gitcode.com/hf_mirrors/meituan-longcat/LongCat-Video
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







