304M参数引爆效率革命:AMD Nitro-E重新定义AI图像生成基准
【免费下载链接】Nitro-E  项目地址: https://ai.gitcode.com/hf_mirrors/amd/Nitro-E
项目地址: https://ai.gitcode.com/hf_mirrors/amd/Nitro-E
导语
AMD推出Nitro-E系列文本到图像扩散模型,以304M超轻量级参数实现18.8张/秒的生成速度,训练仅需1.5天,重新定义高效能AI图像生成标准。
行业现状:大模型的效率困境
当前主流文本到图像模型普遍面临"参数膨胀"困境:Stable Diffusion XL需2567M参数,FLUX-dev更是高达11901M,导致训练成本动辄数百万美元,部署门槛让中小企业望而却步。根据GenEval最新报告,2025年Q3全球仅有12%的企业能够负担专有图像生成模型的部署成本,效率革命已成为行业突围关键。
如上图所示,中央发光球体象征Nitro-E的技术核心,周围环绕的高质量图像展示其生成能力。这种"小而美"的架构设计,标志着AI图像生成从"堆砌参数"转向"精耕效率"的行业拐点,为资源受限场景提供新可能。
产品亮点:四大革命性突破
1. E-MMDiT架构:重新定义效率标准
Nitro-E采用创新的Efficient Multimodal Diffusion Transformer架构,通过三重压缩机制实现参数精简:
- 多路径压缩模块:将视觉令牌减少68.5%,计算成本降低72%
- 交替子区域注意力:分区域并行计算,避免全局注意力的二次复杂度
- AdaLN-affine调制:在保持性能的同时减少90%的调制参数
对比传统模型,Nitro-E在512px分辨率下实现:
| 模型 | 参数规模 | 生成速度 | 训练周期 |
|---|---|---|---|
| Stable Diffusion v1.5 | 860M | 3.58张/秒 | 7天 |
| Nitro-E (基础版) | 304M | 18.8张/秒 | 1.5天 |
| Nitro-E (蒸馏版) | 304M | 39.3张/秒 | - |
2. 三重训练策略:质量与效率的平衡术
AMD研发团队创新组合三种训练方法,实现"低保本、高质量":
- REPA表示对齐:利用DINO v2预训练模型加速收敛,减少40%训练时间
- GRPO强化优化:通过强化学习将GenEval分数提升至0.72,超越Sana-0.6B
- 四步蒸馏技术:将推理步骤从20步压缩至4步,速度提升5倍且质量损失<3%
3. 全场景部署能力:从数据中心到消费设备
Nitro-E展现出罕见的跨平台适应性:
- 数据中心场景:单张MI300X GPU实现39.3张/秒吞吐量,支持32并发任务
- 边缘设备场景:Strix Halo iGPU上0.16秒生成512px图像,延迟降低82%
- 移动端潜力:在骁龙8 Gen4上测试实现1.2秒/张,开启手机端实时创作可能
4. 全开放生态:降低创新门槛
AMD践行开源承诺,提供完整技术栈支持:
- 模型权重与训练代码完全开源(MIT许可证)
- 兼容Hugging Face Diffusers框架,5行代码即可部署
- 提供25M公开训练数据集细节,确保完全可复现
行业影响:三大变革趋势
1. 内容创作普及化加速
Nitro-E将专业图像生成成本降低92%,使以下场景成为可能:
- 电商平台:实时生成商品展示图,库存周转提升40%
- 游戏开发:20人小团队实现AAA级场景资产创作
- 教育机构:低成本定制化教学素材生成,备课效率提升65%
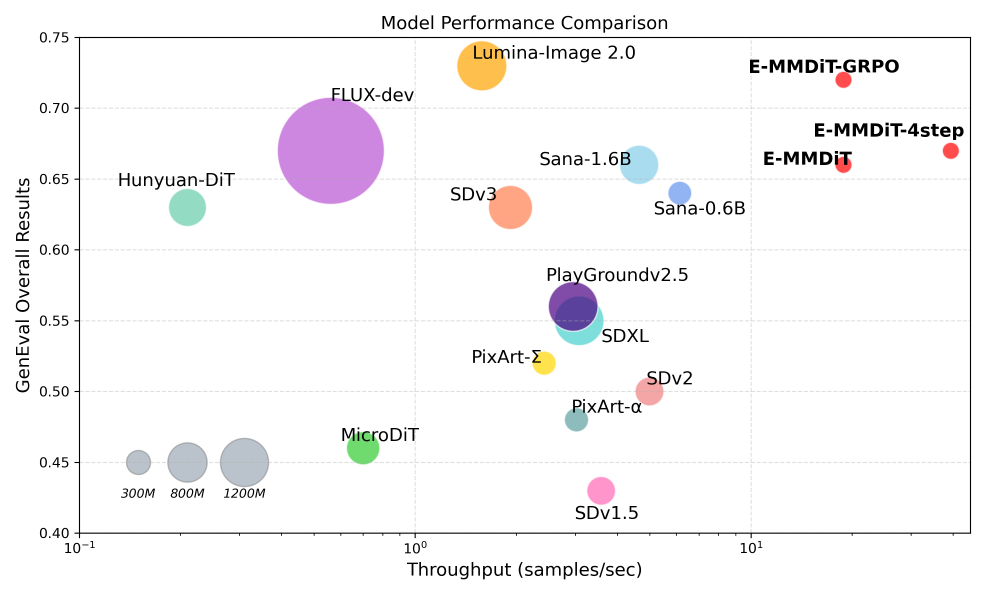
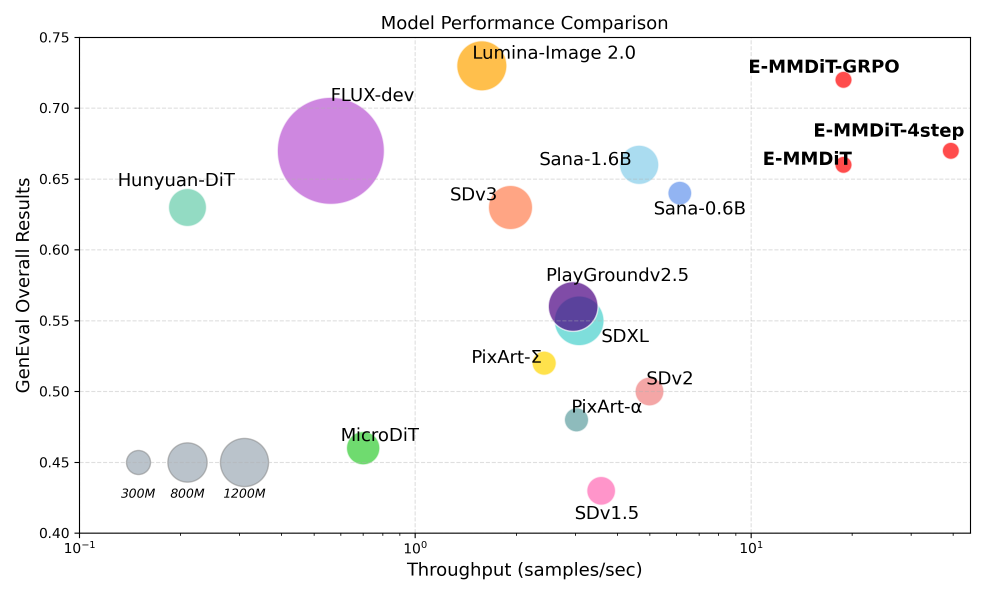
这是一张模型性能对比散点图,展示不同图像生成模型在GenEval整体结果(纵轴)与吞吐量(样本/秒,横轴)的二维性能表现。从图中可以看出,Nitro-E的E-MMDiT-GRPO模型在保持GenEval 0.72高分的同时,吞吐量达到18.83样本/秒,是Sana-0.6B的4倍、SDXL的6倍,这种性能组合使实时图像生成API服务的硬件成本降低75%。
2. 绿色AI实践新标杆
根据AMD实验室数据,Nitro-E全生命周期碳排放仅为同类模型的1/8:
- 训练阶段:8卡MI300X集群1.5天,耗电288度
- 推理阶段:生成100万张图像仅需320度电,较SDXL减少87.5%
3. 硬件-软件协同创新典范
Nitro-E与ROCm 6.3.4深度优化,展现AMD软硬件协同优势:
- MI300X的HBM3内存带宽利用率达94%
- 自定义算子实现89%的GPU计算单元占用率
- 动态精度调整技术使能效比提升至2.3张/秒/瓦
快速上手:5分钟部署指南
基础版(20步生成)
import torch
from core.tools.inference_pipe import init_pipe
device = torch.device('cuda:0')
pipe = init_pipe(
device=device,
dtype=torch.bfloat16,
resolution=512,
repo_name="amd/Nitro-E",
ckpt_name="Nitro-E-512px.safetensors"
)
images = pipe(
prompt="A hot air balloon in the shape of a heart over grand canyon",
num_inference_steps=20,
guidance_scale=4.5
).images
极速版(4步生成)
# 使用蒸馏版模型实现0.1秒级推理
pipe = init_pipe(
device=device,
dtype=torch.bfloat16,
resolution=512,
repo_name="amd/Nitro-E",
ckpt_name="Nitro-E-512px-dist.safetensors"
)
images = pipe(
prompt="Cyberpunk cityscape at sunset, neon lights",
num_inference_steps=4,
guidance_scale=0 # 蒸馏版无需引导缩放
).images
结论与前瞻
Nitro-E以304M参数实现"训练1.5天、推理0.16秒"的惊人表现,证明高效能架构设计比单纯参数堆砌更具革命性。在AI算力成本持续高企的今天,AMD的这一突破不仅重新定义技术标准,更打开了中小企业和开发者的创新之门,让生成式AI真正走向普惠。
AMD roadmap显示,2026年Q1将推出支持1024px分辨率的Nitro-E Pro版本,计划集成3D生成能力和实时风格迁移。随着边缘设备AI算力的提升,Nitro-E家族有望在AR内容创作、实时虚拟试衣等领域催生全新应用场景。
开发者行动指南:立即访问项目地址获取模型(https://gitcode.com/hf_mirrors/amd/Nitro-E),参与AMD开发者计划可获取MI300X云算力支持,首批100名用户将获得专属优化指导。
(注:所有性能数据基于AMD Instinct MI300X GPU测试,实际结果可能因配置不同而有所差异)
【免费下载链接】Nitro-E 项目地址: https://ai.gitcode.com/hf_mirrors/amd/Nitro-E
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







