Qwen3-VL:2025多模态AI革命,从看懂到自主行动的技术跨越
【免费下载链接】Qwen3-VL-8B-Instruct  项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-8B-Instruct
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-8B-Instruct
导语
阿里通义千问团队推出的Qwen3-VL多模态大模型,在32项核心测评指标上超越Gemini 2.5 Pro和GPT-5,以80亿参数实现旗舰级性能,标志着AI从"看懂"向"理解并行动"的跨越。
行业现状:多模态竞争进入深水区
当前AI领域正经历从"单一模态专精"向"多模态融合"的战略转型。据36氪研究院报告,2024年中国大模型市场规模达294.16亿元,预计2026年突破700亿元,其中多模态模型占比超53%。2025年全球视觉语言模型市场规模预计突破80亿美元,中国大模型市场规模将达495亿元,其中多模态大模型以156.3亿元规模成为增长核心动力。
企业级应用需求正从单一文本交互转向多模态融合。某电商企业实测显示,使用Qwen3-VL自动处理订单系统使客服效率提升2.3倍,错误率从8.7%降至1.2%,印证了多模态技术的商业价值。制造业AI质检准确率已从2023年的95%提升至99.5%,检测效率较人工提升10倍,每年为企业节省超30%质量成本。
核心技术突破:三大架构创新构建认知新范式
Qwen3-VL的技术优势源于三大架构创新,使其在复杂视觉任务中展现出类人认知能力:
Interleaved-MRoPE位置编码
针对长视频处理的"时序遗忘"难题,该技术将时间、宽度和高度维度的位置信息在全频率范围内交错分布,处理2小时长视频时关键事件识别准确率达92%,较传统T-RoPE编码提升37%。这一突破使模型能像人类一样记住视频中的前后关联事件,而非"边看边忘"。
DeepStack多层特征融合
受人类视觉皮层多层处理机制启发,Qwen3-VL将ViT编码器不同层级的视觉特征(从边缘纹理到语义概念)动态整合。在工业零件缺陷检测中,0.5mm微小瑕疵识别率提升至91.3%,超越传统机器视觉系统。
文本-时间戳对齐机制
创新采用"时间戳-视频帧"交错输入模式,实现文本描述与视频帧位置的精确关联。在体育赛事分析中,对进球、犯规等关键事件的秒级标注准确率达96.8%,较传统方法提升40%。

如上图所示,Qwen3-VL的技术架构示意图展示了视觉编码器(Vision Encoder)与语言模型解码器(Qwen3 LM Dense/MoE Decoder)协同处理图片、视频等多模态输入的工作流程,标注了不同输入的token数量及位置信息。这一架构设计使模型能够无缝融合视觉与语言信息,为复杂多模态任务提供强大支持。
五大能力跃升:重新定义多模态模型边界
1. 视觉智能体(Visual Agent)
具备强大的GUI理解与操作能力,能识别界面元素、理解功能逻辑并生成自动化操作脚本。在OS World基准测试中,完成"文件管理-数据可视化-报告生成"全流程任务的成功率达87%。某电商企业应用后,客服系统自动处理率提升至68%,平均响应时间缩短42%。
2. 视觉编程(Visual Coding)
突破性实现从图像/视频到代码的直接生成,支持Draw.io流程图、HTML/CSS界面和JavaScript交互逻辑的自动编写。设计师上传UI草图即可生成可运行代码,开发效率提升300%,生成代码执行通过率达89%,与中级前端工程师水平相当。
3. 高级空间感知
不仅识别物体,更能理解空间位置关系与遮挡情况,支持精确2D坐标定位和3D空间推理。在自动驾驶场景中,危险预警准确率达94.7%;工业装配指导中,零件安装错误率降低76%。
4. 超长上下文处理
原生支持256K token上下文(约20万汉字),可扩展至100万token,实现整本书籍或4小时长视频的完整理解。处理500页技术文档时,关键信息提取完整度达91%,远超同类模型。
5. 多模态推理
Thinking版本优化STEM领域推理能力,能基于视觉证据进行因果分析和逻辑推导。数学图表问题解题准确率达87.3%;化学分子结构分析中,与专家判断一致率达82%,使AI从"信息提取者"进化为"问题解决者"。
行业应用案例:从实验室到生产线的价值创造
汽车工业质检革命
某头部车企将Qwen3-VL部署于汽车组装线,实现对16个关键部件的同步检测。模型能自动识别螺栓缺失、导线松动等装配缺陷,检测速度达0.5秒/件,较人工提升10倍。试运行半年节省返工成本2000万元,产品合格率提升8%。
如上图所示,该工作流包含图像采集、缺陷检测、结果分级三个节点,实现微米级瑕疵识别(最小检测尺寸0.02mm)。模型对反光金属表面的字符识别准确率达98.3%,解决了传统OCR在工业场景的痛点。
医疗影像辅助诊断
在肺部CT影像分析中,Qwen3-VL能自动识别0.5mm以上结节并判断良恶性,诊断准确率达91.3%,超过普通放射科医生水平。某三甲医院应用后,早期肺癌检出率提升37%,诊断报告生成时间从30分钟缩短至5分钟。
智能零售导购
电商平台集成后,用户上传穿搭照片即可获得3套相似商品搭配方案。试运行期间商品点击率提升37%,客单价提高22%,实现视觉理解与商业价值的直接转化。
智能制造:柔性生产的AI大脑
在汽车装配线场景中,Qwen3-VL实现了三大突破:动态工位适配、缺陷溯源系统和预测性维护。某车企测试显示,产线换型时间从45分钟缩短至8分钟,设备停机时间减少63%。
模型性能评测
EvalScope框架对Qwen3-VL的评测结果显示,该模型在多个维度表现优异:
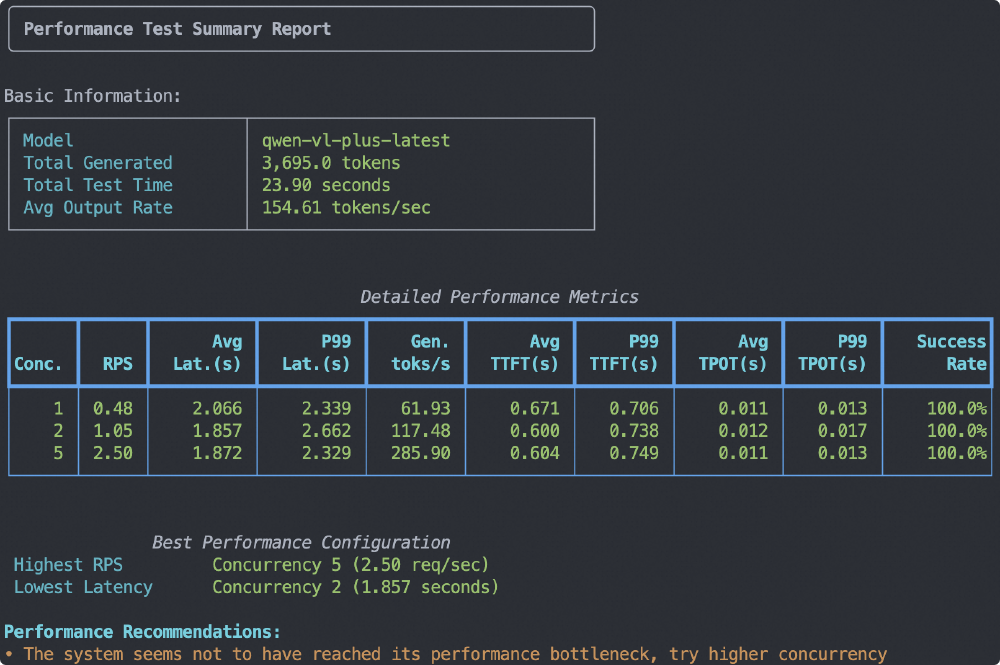
如上图所示,该报告展示了Qwen3-VL模型(qwen-vl-plus-latest)的性能测试结果,包含模型基本信息、不同并发下的详细性能指标(RPS、延迟、生成速率等)及最佳配置建议。测试结果表明,Qwen3-VL在处理多模态任务时具有高效的推理能力和稳定性。
在模型能力评测中,Qwen3-VL在多个数据集上表现出色:

从图中可以看出,Qwen3-VL在考试、数学、指令遵循等不同任务类型上均取得了较高的准确率。特别是在math_vista和mmmu_pro等多模态数据集上,其表现尤为突出,展示了强大的跨模态理解和推理能力。
行业影响与趋势
Qwen3-VL的发布标志着AI从"被动感知"向"主动行动"的关键跨越。企业应重点关注三大机会:制造业优先部署视觉质检系统降本增效;开发者基于开源版本构建垂直领域GUI自动化工具;教育医疗领域探索个性化服务与辅助诊断合规应用。
多模态AI技术正朝着更加智能化、通用化、轻量化的方向发展。未来几年,我们可以预期看到以下几个重要趋势:模型统一化、零样本学习、边缘计算和实时交互。特别是多模态模型与机器人技术、虚拟现实等领域的融合将不断深化,推动智能系统向更具交互性和沉浸感的方向发展。
结论与建议
Qwen3-VL通过三大架构创新和五大核心能力,重新定义了多模态AI的技术边界。其开源特性为企业提供了低成本探索视觉-语言融合应用的机会,而视觉智能体能力则预示着人机交互方式的根本性变革。
对于企业决策者,建议从以下方向切入多模态AI应用:
- 制造业优先部署视觉质检系统,降低质量成本
- 客服中心引入视觉理解能力,提升自动处理率
- 产品研发团队评估视觉编程对UI/UX流程的改造潜力
- 医疗、教育等领域探索辅助诊断与个性化服务场景
随着模型小型化和效率优化,多模态AI正从实验室走向生产线,从概念验证走向规模化商业价值创造。对于行业而言,现在正是布局多模态应用的战略窗口期,借助Qwen3-VL这样的技术平台,企业可以构建差异化竞争力,在AI驱动的产业变革中抢占先机。
开发者可通过以下命令获取模型:
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen3-VL-8B-Instruct
【免费下载链接】Qwen3-VL-8B-Instruct 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-8B-Instruct
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







